LSM-Tree - LevelDb 源码解析
引言
在上一篇文章[[LSM-Tree - LevelDb了解和实现]]中介绍了LevelDb相关的数据结构和核心组件,LevelDB的核心读写部分,以及为什么在这个数据库中写入的速度要比读取的速度快上好几倍。
LevelDB的源代码还是比较好懂的,好懂到我只学过学JAVA只有定点基础C语言入门知识的人也能看懂,另一方面作者在关键的地方都给了注释,甚至告诉你为什么要这么设计(写的很好很棒让人落泪为什么自己没这样的同事)。
如果还是看不懂,作者也写了很多数据结构介绍的md文档(在doc目录中)告诉你核心组件的作用。
总之,不要惧怕这个数据库,无论是作为优秀代码和设计模式还是各种主流数据结构算法应用都非常值得学习和参考。
Tip:这一节代码内容非常多,所以不建议在手机或者移动设备阅读,更适合在PC上观看。
源码运行
LevelDB的编译是比较简单的,可以从官网直接克隆代码。
地址:https://github.com/google/leveldb
具体操作步骤如下(也可以参考仓库中的README):
1 | git clone --recurse-submodules https://github.com/google/leveldb.git |
完成整个编译动作之后,我们可以新增一个动态库,一个静态库和test目录,接着就可以编写单元测试了,同时官方的源代码中有很多的单元测试可以提供自己编写的测试程序进行调试使用,当然这里跳过这些内容,直接从源码开始。
底层存储存储结构
关联:[[SSTable]]
在LevelDB中SSTable是整个数据库最重要的结构,所有的SSTable文件本身的内容是不可修改的,虽然通常数据在内存中操作,但是数据不可能无限存储,当数据到达一定量之后就需要持久化到磁盘中,而压缩合并的处理就十分考验系统性能了,为此LevelDb使用分层的结构进行存储,下面我们从外部的使用结构开始来了解内部的设计。
整个外部的黑盒就是数据库本身了,以事务性数据库为例,通常的操作无非就是ACID四种,但是放到LSM-Tree的数据结构有点不一样,因为更新和删除其实都会通过“新增”与“合并”的方式完成新数据对旧数据的覆盖。
扯远了,我们从简单的概念开始,首先是整个DB的源代码,DB源代码可以通过以下路径访问:
https://github.com/google/leveldb/blob/main/include/leveldb/db.h
首先我们需要了解DB存储结构,可以看到存储引擎的对外提供的接口十分简单:
1 | class LEVELDB_EXPORT DB { |
Get 和 Put 是 LevelDB 为上层提供的用于读写的接口,注意这个接口的Update和Delele操作 实际上是通过Put完成的,实现方式是内部做了类型判断,十分有意思,这里可以先留意一下。
write部分
下面先从写入操作开始,看看数据是如何进入到LevelDb,以及内部是如何管理的。
Write的内部逻辑算是比较复杂的,所以这里画了下基本流程图:
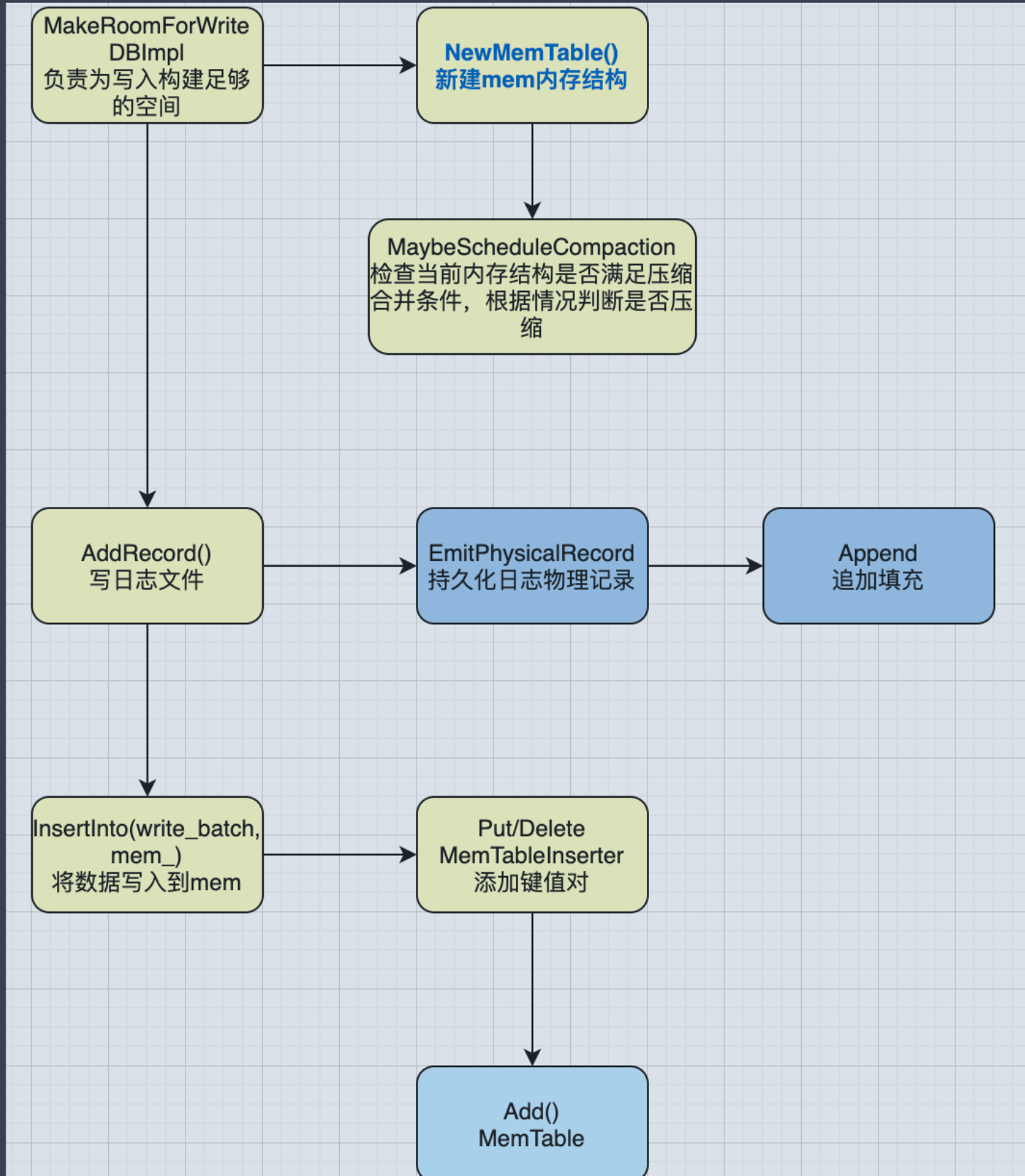
我们从DB的Write()接口方法切入,简化代码之后大致的流程如下:
1 | // 为写入构建足够的空间,此时可以不需要加锁。 |
整个执行流程如下:
- 首先调用
MakeRoomForWrite方法为即将进行的写入提供足够的空间。- 如果当前空间不足需要冻结当前的
memtable,此时发生Minor Compaction并创建一个新的MemTable对象。 - 如果满足触发
Major Compaction需要对数据进行压缩并且对于SSTable进行合并。
- 如果当前空间不足需要冻结当前的
- 通过
AddRecord方法向日志中追加一条写操作记录。 - 最终调用memtable往内存结构中添加key/value,完成最终写入操作。
将写入操作的源代码逻辑简化之后最终如下:
1 |
|
上面代码有较多的方法封装,这里我们一个个来看。
MaybeScheduleCompaction()压缩合并(如果觉得这里突兀可以请参阅上文的流程图)在源码中系统会定时检查是否可以进行压缩合并,if/else用于多线程并发写入的时候进行合并写入的操作,当发现有不同线程在操作就会等待结果或者等到拿到锁之后接管合并写入的操作。
如果对于下面的代码有疑问可以阅读[[LSM-Tree - LevelDb了解和实现]]中关于“合并写入”的部分,为了节省时间,可以在网页中直接输入关键字“合并写入”快速定位,这里假设读者已经了解基本的工作流程,就不再赘述了。
#LevelDb合并写入操作
1 | void DBImpl::MaybeScheduleCompaction() { |
不可变memtable:
在write的函数内部有这样一串代码,此时会暂停解锁等待写入,这个写入又是干嘛的?
1 | Status status = MakeRoomForWrite(updates == nullptr); |
进入方法内部会发现通过一个while循环判断当前的 memtable状态,一旦发现memtable写入已经写满整个mem,则需要停止写入并且将当前的memtable转为imutiablememtable,并且创建新的mem切换写入,此时还会同时根据一些条件判断是否可以进行压缩 mem。
这里额外解释源码中GUARDED_BY含义:
GUARDED_BY是数据成员的属性,该属性声明数据成员受给定功能保护。对数据的读操作需要共享访问,而写操作则需要互斥访问。
该 GUARDED_BY属性声明线程必须先锁定listener_list_mutex才能对其进行读写listener_list,从而确保增量和减量操作是原子的。
总结:其实就是一个典型的互斥共享锁,至于实现不是本文的重点。
mem可以看作是当前的系统备忘录或者说临时的记账板,和大多数的日志或者关系型数据库类似,都是先写入日志在进行后续的所有“事务”操作,也就是日志优先于记录操作 原则,根据日志写入操作加锁来完成并发操作的正常运行。
MakeRoomForWrite 方法中比较关键的部分都加了注释,很多操作作者都有介绍意图,代码逻辑都比较简单,多看几遍基本了解大致思路即可。(C++语法看不懂不必过多纠结,明白他要做什么就行,主要是我也看不懂,哈哈)
1 | while (true) { |
下面用一个简单的示意图了解上面的大致流程:

注意这对于[[SSTable]]的原始理论的实现结构显然是有一定出入,当然这是很正常的理论和实践的差别。
在通常情况下memtable可以通过短暂的延迟读写请求等待压缩完成,但是一旦发现mem占用的内存过大,此时就需要给当前的mem加锁变为_imu状态,然后创建一个新的 MemTable 实例并且把新进来的请求转到新的mem中,这样就可以继续接受外界的写操作,不再需要等待 Minor Compaction 的结束了。
再次注意此处会通过函数 MaybeScheduleCompaction 是否进行压缩合并的操作判断。
这种无等待的设计思路来自于:[[Dynamic-sized NonBlocking Hash table]],可以自己下下论文来看看,当然也可以等我后面的文章。
log部分
写入的大致操作流程了解之后,下面来看看LevelDb的日志管理也就是AddRecord()函数的操作:
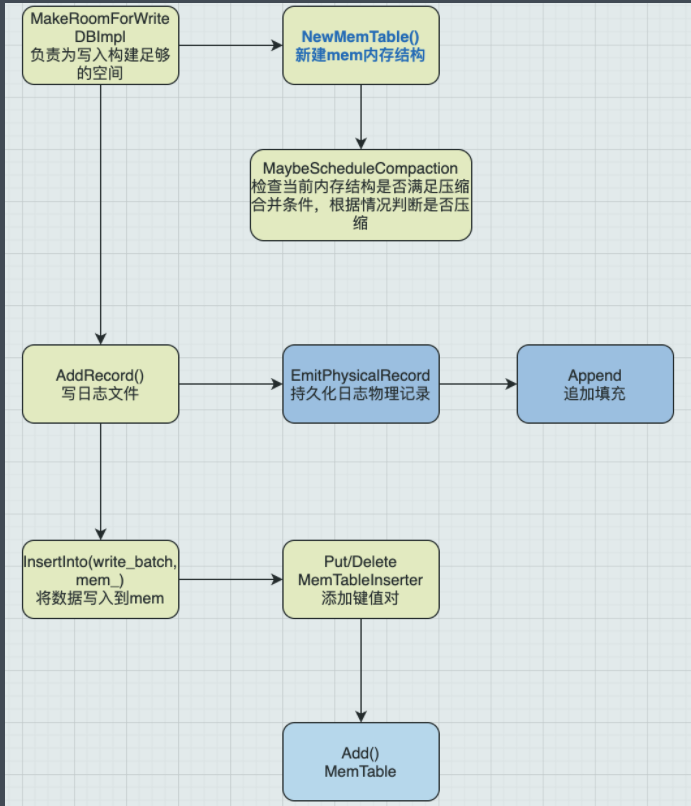
注意日志的核心部分并不在AddRecord()内部,因为内部只有一些简单的字符串拼接操作,这里将核心放到了RecordType的部分,可以看到这里通过当前日志字符长度判断不同的类型,RecordType标识当前记录在块里面的位置:
1 | //.... |
First:是用户记录第一个片段的类型,
Last:是用户记录的最后一个片段的类型。
Middle:是一个用户记录的所有内部片段的类型。
如果看不懂源代码,可以根据作者的md文档介绍也可以大致了解日志文件结构:
1 | record := |
我们可以根据描述简单画一个图:
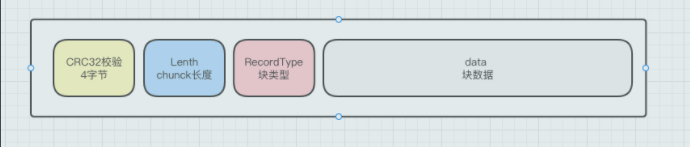
从RecordType内部的定义可以看到日志固定为32KB大小,在日志文件中将分为多部分,但是一个日志只包含在一个单一的文件块。
RecordType 存储的内容如下:
- 前面4个字节用于CRC校验
- 接着两个字节是块数据长度
- 接着是一个字节的类型标识(标识当前日志记录在块中位置)
- 最后是数据payload部分
32kb大小选择是考虑到日志记录行的磁盘对齐和日志读写,针对日志写的速度也非常快,写入的日志先写入内存的文件表,然后通过fdatasync(...)方法将缓冲区fflush到磁盘中并且持久化,最后通过日志完成故障恢复的操作。
需要注意如果日志记录较大可能存在于多个block块中。
一个记录永远不会在一个块的最后六个字节内开始,理由是一个记录前面需要一些其他部分占用空间(也就是记录行的校验和数据长度标识信息等)。
为了防止单个日志块被拆分到多个文件以及压缩考虑,这种“浪费”是可以被接受。
如果读者非要清楚最后几个字节存储的是什么,想满足自己的好奇心,可以看下面的代码:
dest_->Append(Slice("\x00\x00\x00\x00\x00\x00", leftover));
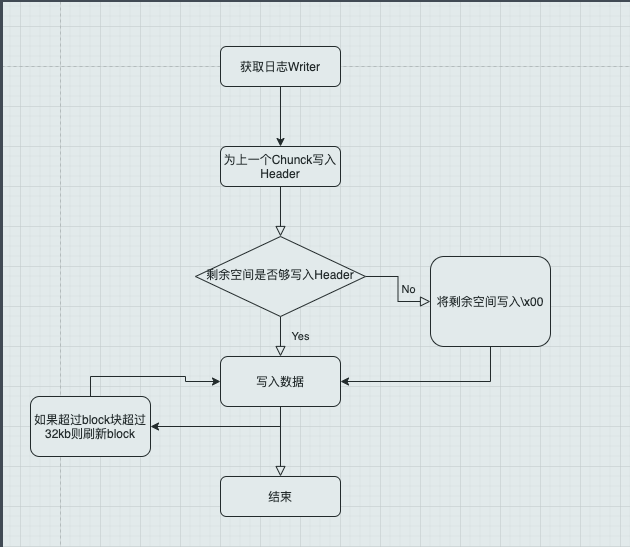
日志写流程图:
日志写的流程比较简单,主要分歧点是当前块剩余空间是否够写入一个header,并且最后6个字节将会填充空格进行补齐。
在日志写入的过程中通过一个while(ture)不断判断buffer大小,如果大小超过32KB-最后6个字节,则需要停止写入并且把开始写入到现在位置为一个数据块。
下面是日志写流程图:
下面是日志读流程图:
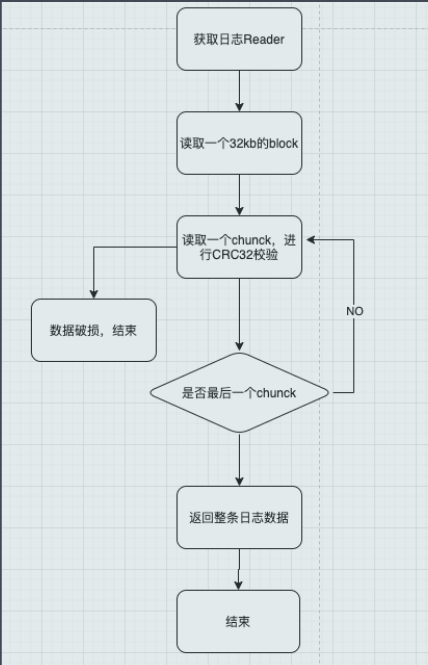
既然日志大小为32kb,那么日志的读写单位也应该是32kb,接着便是扫描数据块,在扫描chunk的时候如果发现CRC校验不通过则返回错误信息,如果数据破损则丢弃当前chunk。
翻了一下代码,简单来说就是读取通过while(true)循环read,直到读取到类型为Last的chunk,日志记录读取完成。
memtable比较有意思的特点是无论插入还是删除都是通过“新增”的方式实现的(你没有看错),内部通过Mainfest维护状态,同时根据版本号和序列号维护一条记录是新增还是删除并且保证读取到的内容是最新值,具体介绍同样在上一节[[LSM-Tree - LevelDb了解和实现]]中。
注意写入日志之后记录是不能查询的(因为中间有可能存在断电故障导致真实记录没有写入),日志仅作为故障恢复,只有数据写入到mem之后才被访问到。
关于mem新增和删除的代码如下:
1 | namespace { |
在Add()函数的内部通过一个[[LSM-Tree - LevelDb Skiplist跳表]]完成数据的插入,在数据的node中包含了记录键值,为了保证读取的数据永远是最新的,记录需要在skiplist内部进行排序,节点排序使用的是比较常见的比较器Compare,如果用户想要自定义排序(例如处理不同的字符编码等)可以编写自己的比较器实现。
对于一条记录的结构我们也可以从 Add() 函数中看到作者的注释:
1 | // Format of an entry is concatenation of: |
[[VarInt32编码]]:在这里虽然是变长整型类型但是实际使用4个字节表示。
uint64((sequence << 8) | type:位运算之后实际为7个字节的sequence长度
注意在tag和value_size中间有一个ValueType标记来标记记录是新增还是删除。
VarInt32 (vary int 32),即:长度可变的 32 为整型类型。一般来说,int 类型的长度固定为 32 字节。但 VarInt32 类型的数据长度是不固定的,VarInt32 中每个字节的最高位有特殊的含义。如果最高位为 1 代表下一个字节也是该数字的一部分。
因此,表示一个整型数字最少用 1 个字节,最多用 5 个字节表示。如果某个系统中大部分数字需要 >= 4 字节才能表示,那其实并不适合用 VarInt32 来编码。
根据get()代码内部通过valueType进行区分,valueType占用一个字节的空间进行判断新增还是删除记录,默认比较器判断新增或者删除记录逻辑如下:
1 | if (comparator_.comparator.user_comparator()->Compare( |
根据代码定义和上面的描述画出下面的结构图:

Compare键排序
LevelDb的memtable通过跳表维护了键,内部默认情况下通过InternalKeyComparator对于键进行比较,下面是比较内部逻辑:
比较器通过 user_key 和 sequence_number 进行排序,同时按照user_key进行升序排序,序列号通过插入的时间递增,以此来保证无论是增加还是删除都是获取到最新的信息。
1 | /* |
需要注意被比较key可能包含完全不同的内容,这里读者肯定会有疑问对于key获取值进行提取信息是否会有影响,然而从get的逻辑来看它可以通过键长度,和序列号等信息进行获取Key,并且获取是header的头部信息,所以key是任何类型都是没有影响的。
记录查询
现在我们再回过头来看一下memtable是如何读取的,从memtable和imumemble的关系可以看出有点类似缓存,当memtable写满之后转为imumem并且等待同步至磁盘。
key读取和查找的顺序如下:
- 在memtable中获取指定Key,如果数据符合条件则结束查找。
- 在Imumemtable中查找指定Key,如果数据符合条件则结束查找。
- 按低层至高层的顺序在level i层的sstable文件中查找指定的key,若搜索到符合条件的数据项就会结束查找,否则返回Not Found错误,表示数据库中不存在指定的数据。
记录按照层级关系进行搜索,首先是从当前内存中正在写入memtable搜索,接着是imumemtable,再接着是存在于磁盘不同层级的SSTable,SSTable通过*.ldb的形式进行标记,可以快速找到。
最终我们可以把LevelDb的查询看作下面的形式:

小结:
这一部分我们了解了LevelDB源代码部分等基础结构DB,介绍了LevelDB的基础对外接口,LevelDB和map的接口看起来十分类似,这一部分重点讲述了读写操作等源代码,以及内部合并压缩的一些细节。
另外记录查询等动作和之前介绍LevelDB等读写流程大致类似,当然代码简化了很多的内容,读者可以根据自己感兴趣的内容研究。
SSTable操作
前面我们提到了记录的增删改查底层查询,和日志的读写细节,下面则针对谷歌发明的特殊数据结构SSTable进行介绍。
SSTable如何工作?
SSTable在初始的论文中可以总结出下面的特点:
- 写入的时候不写入磁盘而是先写入内存表的数据结构。
- 当数据结构内存占用超过一定的阈值就可以直接写入到磁盘文件由于已经是排好序的状态,所以可以直接对旧结构覆盖,写入效率比较高。并且写入和数据结构改动可以同时进行。
- 读写顺序按照 内存 - 磁盘 - 上一次写入文件 - 未找到。
- 后台定时线程定时合并和压缩排序分段,将废弃值给覆盖或者丢弃。
[[SSTable]] 最早出现在谷歌2006年的论文当中,LevelDB的SSTable设计也有部分特性体现这个数据结构,当然并不是完全一致的,LevelDB利用SSTable在磁盘中维护多层级的数据节点。
可以认为了解SSTable结构就相当于了解了LevelDb的核心数据结构设计。
多层级SSTable
我们重点看看多层级的SSTable部分,levelDB在磁盘中扫描SSTable的时候LevelDB并不会跳过层级,这里肯定会有疑问每个层级都扫一遍的效率问题,针对这个问题作者在db中设计了下面的数据结构:
1 | struct FileMetaData { |
在上面的结构体声明中定义了压缩SSTable文件的全部信息,包括最大值和最小值,运行查找次数,文件引用次数和文件号,SSTable会按照固定的形式存储到同一个目录下面,所以可以通过文件号进行快速搜索。
查找和记录key顺序类似,都是按照从小到大的顺序进行读取的,以Level0为例,里面通常包含4个固定的SSTable,并且内部通常存在key交叉,所以会按照从SSTable1-4的顺序进行读取,而更高层次的层级则通过查找上面结构体的最大值和最小值的信息(smallest和largest)。
具体的文件搜索细节可以通过TableCache::FindTable查找 ,由于篇幅有限这里就不贴代码了,简要逻辑是配合缓存和RandomAccessFile对于文件进行读写,然后把读到的文件信息写入到内存中方便下次获取。
如果了解Mysql Btree设计会发现文件搜索有些类似页目录的查找。不同的是Btree页目录通过页目录等稀疏搜索。
SSTable合并
我们再来看看SSTable是如何合并的,之前提到过SSTable通过MaybeScheduleCompaction尝试合并,需要注意这个合并压缩和Bigtable的形式类似,都是根据不同的条件判断是否进行合并,一旦可以合并便执行BackgroundCompaction操作。
合并分为两种情况,一种是Minor Compaction,另一种是将Memtable数据写满转为不可变对象(实际就是加锁),执行CompactMemtable进行压缩。
合并操作简化版源代码如下:
1 | void DBImpl::CompactMemTable() { |
CompactMemTable方法会先构建当前的修改版本号,然后调用WriteLevel0Table()方法尝试把当前的Imumtable写入到Level0的层级。
如果发现Level0的层级SSTable过多,则进一步进行Major Compaction,同时根据BackgroudCompcation()选择合适的压缩层级和压缩方式。
下面是writeLevel0的简化代码:
简化代码的最后几行代码会获取文件信息的最大值和最小值以此判断是否在当前SSTable搜索还是跳转到下一个。
数据如果是写入Level0我们可以看作是Major Compaction。
1 | Status DBImpl::WriteLevel0Table(MemTable* mem, VersionEdit* edit, |
结合上下两段源码可以发现文件管理最终是通过VersionEdit来完成的,如果写入成功了则返回当前的SSTable的FileMetaData,在VersionEdit内部通过logAndApply的方式记录文件内部的变化,也就是前文介绍的日志管理功能了,完成之后通过RemoveObsoleteFiles()方法进行数据的清理操作。
如果Level0写满了此时就需要进行Major Compaction,这个压缩会比前面的要复杂一些因为涉及低层级到高层级的压缩。
这里需要再回看BackgroundCompaction的代码,具体代码如下:
1 | void DBImpl::BackgroundCompaction() { |
首先根据VersionSet 查找需要压缩的信息,并且打包加入到 Compaction 对象,这个对象根据查询次数和大小限制来选择需要压缩的两个层级,因为level0中包含很多重叠键,则会在更高层级找到有重叠的键的SSTable,再通过FileMetaData找到需要压缩的文件,另外查询频繁的SSTable将会“升级”到更高层级进行压缩存储,并且更新文件信息方便下一次查找。
合并的触发条件
每个 SSTable 在创建之后的 allowed_seeks 都为 100 次,当 allowed_seeks < 0 时就会触发该文件的与更高层级和合并,因为频繁查询的数据通常会降低系统性能。
这样的设计理由是在高层级搜索键说明在上一层肯定是相同的键查找,同时也是为了减少每次都覆盖扫描多层级扫描寻找数据。最终这种设计方式核心是以更新FileMetaData 来减少下一次查询的性能开销。
另外这种处理可以简单理解为我们在操作系统中进行深层次文件夹搜索的时候,如果频繁查询某个深层次的数据很麻烦,解决此问题的第一种方式是建立一个“快捷方式”的文件夹,另一种是直接做标签直接指向这个目录,其实两者都是差不多的,所以压缩设计也是同理。
LevelDB 中的 DoCompactionWork 方法会对所有传入的 SSTable 中的键值使用归并排序进行合并,最后会在更高层级中生成一个新的 SSTable。
归并排序主要是对于key进行归并,使得迭代的时候key就是有序的可以直接合并到指定的高高层级。关键代码存在于下面的代码
Iterator* input = versions_->MakeInputIterator(compact->compaction);
归并排序
DoCompactionWork 归并排序 的源代码如下:
1 | Status DBImpl::DoCompactionWork(CompactionState* compact) { |
归并排序并且处理完键值信息完成跨层级压缩,之后便是是一些收尾工作,收尾工作需要对于压缩之后的信息统计。
1 | CompactionStats stats; |
最后层级压缩的默认层级为7个层级,在源代码中有如下定义:
static const int kNumLevels = 7;
小结
这里我们小结一下合并压缩的两个操作:Minor Compaction和Major Compaction:
Minor Compaction:这个GC主要是Level0层级的一些压缩操作,由于Level0层级被较为频繁使用,类似一级缓存,键值不会强制要求进行排序,所以重叠的键会比较多,整个压缩的过程比较好理解,关键部分是skiplist(跳表)中构建一个新的SSTable并且插入到指定层级。
注:Minor Compaction进行的时候会暂停Major Compaction操作。
Minor Compaction:这个比Minor Compaction复杂不少,不仅包含跨层级压缩,还包括键范围确定和迭代器归并排序和最终的统计信息操作,其中最最关键的部分是归并排序压缩列表,之后将旧文件和新文件合并生产新的VersionSet信息,另外这里除开全局的压缩进度和管理操作之外。
另外Minor Compaction完成之后还会再尝试一次Minor Compaction,因为Minor Compaction可能带来更多的重复键,所以再进行一次压缩可以进一步提高查找效率。
Major Compaction:这个操作需要暂停整个LevelDB的读写,因为此时需要对于整个LevelDb的多层级进行跨层级合并,跨层级压缩要复杂很多,具体的细节会在后面介绍。
这里可以认为是作者在测试的过程发现一种情况并且做的优化。
存储状态 - VersionSet
从这个对象名称来看直接理解为“版本集合”,在内部通过一个Version的结构体对于键值信息进行“版本控制”,毫无疑问这是由于多线程压缩所带来的特性,所以最终是一个双向链表+历史版本的形式串联,但是永远只有一个版本是当前版本。
VersionSet最为频繁也是比较关键的一个操作函数LogAndApply,下面是简化之后的VersionSet::LogAndApply代码:
这里可以对照关系型数据库Mysql的Mvcc中的undo log类比进行理解
1 | Status VersionSet::LogAndApply(VersionEdit* edit, port::Mutex* mu) { |
关键部分注释已给出,这里的Mainfest细节在之前没有提到过,在作者提供的impl.md是这样介绍mainfest的:
MANIFEST 文件列出了组成每个级别的排序表集、相应的键范围和其他重要的元数据。 每当重新打开数据库时,都会创建一个新的 MANIFEST 文件(文件名中嵌入了一个新编号)。 MANIFEST 文件被格式化为日志,并且对服务状态所做的更改(随着文件的添加或删除)被附加到此日志中。
从个人的角度来看,这个文件有点类似BigTable中的元数据Meta。
SSTable文件格式
理解这部分不需要急着看源代码,在仓库中的table_format.md的文件中同样有相关描述,这里就直接照搬官方文档翻译了:
leveldb 文件格式
[数据块 1]
[数据块 2]
…
[数据块N]
[元块 1]
…
[元块K]
[元索引块]
[索引块]
[页脚](固定大小;从 file_size - sizeof(Footer) 开始)
我们可以根据描述画一个对应的结构图:

上面的结构图从上至下的介绍如下:
- 数据块:按照LSM-Tree的数据存储规范,按照key/value的顺序形式进行排序,数据块根据
block.builder.cc的内部逻辑进行格式化,并且可以选择是否压缩存储。 - 元数据块:元数据块和数据块类似也使用
block.builder.cc进行格式化,同时可选是否压缩,元数据块后续扩展更多的类型(主要用作数据类型记录) - “元索引”块:为每个其他元数据块索引,键为元块的名称,值为指向该元块的 BlockHandle。
- “索引块”:包含数据块的索引,键是对应字符串>=数据块的最后一个键,并且在连续的数据块的第一个键之前,值是 数据块的 BlockHandle。
- 文件的最后是一个固定长度的页脚,其中包含元索引和索引块的 BlockHandle 以及一个幻数。
幻数又被称为魔数,比如JAVA的字节码第一个字节8位是
CAFEBABE,数值和字节大小没什么意义,更多是作者的兴趣。
注意Footer页脚固定48个字节的大小,我们能在其中拿到 元索引块 和 索引块的位置,然后通过这两个索引寻找其他值对应的位置。
更详细的内容可以继续参考table_format.md介绍,这里就不再赘述了。
TableBuilder:
SSTable接口定义于一个TableBuilder构建器当中,TableBuilder 提供了用于构建 Table 的接口,关于此接口的定义如下:
TableBuilder提供了用于建立表的接口 (一个从键到值的不可变和排序的映射)。
多个线程可以在一个TableBuilder上调用const方法而不需要外部同步。但如果任何一个线程可能调用一个非常量方法,所有访问同一个TableBuilder的线程必须使用外部同步。
1 | // TableBuilder 提供了用于构建 Table 的接口 |
小结:
SSTable 相关的设计在整个LevelDB中有着重要的地位和作用,我们介绍了SSTable的多层级合并和压缩的细节,以及两种不同的压缩形式,第一种是针对Level0的简单压缩,简单压缩只需要把存在于内存中的SSTable也就是将Imumemtable压缩到磁盘中存储,特别注意的是这个动作在第一次完成之后通常还会再执行一次,目的是为了防止合并之后产生的。
另一种是针对频繁Key查询进行的多层级压缩,多层级压缩要比简单压缩复杂许多,但是多层级压缩是提高整个LevelDB写入性能和查询性能到关键。
最后,从LevelDB中也可以看到很多经典数据结构和算法的实现,比键管理利用了跳表+归并排序的方式提高管理效率,排序的内容不仅利于查询,在存储的时候也有利于数据的顺序扫描。
Skiplist跳表
跳表不仅在LevelDb中使用,还在许多其他的中间件中存在实现,这一部分内容将会放到下一篇文章单独介绍。
压缩文件使用了归并排序的方式进行键合并,而内部的数据库除了归并排序之外还使用了比较关键的[[LSM-Tree - LevelDb Skiplist跳表]]来进行有序键值管理,在了解LevelDB跳表的细节之前,需要先了解跳表这个数据结构的基本概念。
[[LevelDb跳表实现]]
布隆过滤器
Bloom Filter是一种空间效率很高的随机数据结构,它利用位数组很简洁地表示一个集合,并能判断一个元素是否属于这个集合。Bloom Filter的这种高效是有一定代价的:在判断一个元素是否属于某个集合时,有可能会把不属于这个集合的元素误认为属于这个集合(false positive)。因此,Bloom Filter不适合那些“零错误”的应用场合。而在能容忍低错误率的应用场合下,Bloom Filter通过极少的错误换取了存储空间的极大节省。
leveldb中利用布隆过滤器判断指定的key值是否存在于sstable中,若过滤器表示不存在,则该key一定不存在,由此加快了查找的效率。
布隆过滤器在不同的开源组件中用的也比较多,所以这里同样放到了一篇单独文章讲解。
[[LSM-Tree - LevelDb布隆过滤器]]
写在最后
LevelDB的设计还是很有意思的,关键是大部分的代码都有解释和介绍。
源代码内容很多,但是仔细分析的话不难分析,感谢看到最后。
参考资料
- leveldb-handbook
- bigtable-leveldb
- Skip List–跳表(全网最详细的跳表文章没有之一) - 简书 (jianshu.com)
- # Bloom Filter概念和原理
相关阅读
- LSM-Tree - LevelDb了解和实现
- 《数据密集型型系统设计》LSM-Tree VS BTree