《网络是怎么样连接的》读书笔记 - 认识网络基础概念(一)
本章重点
- 关于互联网的一些历史补充
- 解析URL的过程简述
- HTPP请求的基本结构和组成
- IP 地址、子网掩码以及DNS的基本了解,掌握概念和相关知识点。
讲讲历史
1991年8月6日,在瑞士日内瓦的核子研究中心(CERN)工作的英国物理学家蒂姆·伯纳斯·李(Tim Berners-Lee),正式提出了World Wide Web,也就是如今我们非常熟悉的www。
www是什么?万维网WWW是World Wide Web的简称,也称为Web、3W等。WWW是基于客户机/服务器方式的信息发现技术和超文本的综合技术。
这里个人比较好奇我们天天都在说3w,3w,但是互联网是怎么出现的的书中并没有解释?
这里查了下网上资料根据个人理解解释一波:
实际上网络最开始苗头出现在美苏冷战的时期美国建立的APRA科研部门,被突然扯出来的科研部门一盘散沙不知道干嘛,对付苏联的科研工作也没什么进展,直到一个叫做罗伯特·泰勒的哥们出现,他的突破口是发现小型的通信网络不能兼容不同型号的计算机,我们都知道技术的顶峰就是定规则,毫无疑问他选择构建一套协议让所有的计算机都能遵守这一套规则干活。
于是他找来了几个牛逼的大佬开始捣鼓,中间巴拉巴拉做了很多事绕了很多弯,目的其实就是为了实现上面说的东西,最终在一次失败的“LOGIN”验证中虽然仅仅传输了“LO”两个字母就断开了,但是这次失败是历史性的进步,因为两个不同的设备实实在在的通信了,最终修复之后完成了这五个字母的正常传输。
随后捯饬出的ARPANET(阿帕网) 这个项目,也就是正式的互联网雏形。
课外知识到此结束,现在我们看看第一章主要看点:
- 如何解析网址?
- DNS 服务器如何查询域名对应的 IP 地址?
- DNS服务器如何接力?
- 浏览器如何将消息委托给操作系统发送给 Web 服务器?
核心是理解DNS的角色地位和作用,以及浏览器如何跟DNS交互完成网址(域名)解析为IP这一个操作的,本章最后的委托流程是整个第二章的重点内容,笔记顺其自然的放到了第二章笔记当中,为了方便理解把笔记归纳到第二部分。
如何解析网址
我们从URL开始,什么是URL,URL是Uniform Resource Locator的简称,专业解释叫做统一资源定位符,除开我们常见的http、https协议之外,浏览器还可以进行ftp文件上传,下载文件,发送电子邮件,浏览新文化等操作。
我们把这些行为看作是资源交互,虽然不同的资源交互会存在不同的URL组合,但是不管URL的组合形式如何变化,最终是开头决定一切,开头部分决定对待资源方式。
解析网址我们可以看下面的例子:
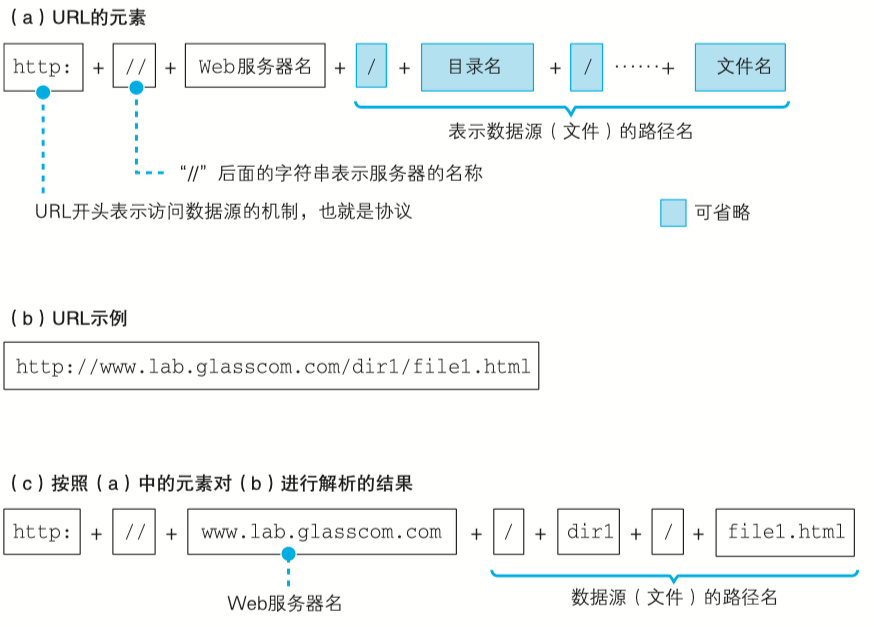
碰到省略文件名的情况,通常下面几种:
http://xxxx/dir/表示/dir/之后的内容被省略,这时候通常情况下会设置对应这个目录的真实访问路径进行补全。- 对于web中最为经典的
http://localhost:8080/访问路径,通常情况下Web服务器会访问到/index.html这个文件,如果没有就会返回404的页面。 - 如果只有域名,比如
www.baidu.com,那就会直接访问web服务器设置的根路径对应的资源和相关文件。 - 含混不清的路径比如
http://localhost:8080/wishlist,则会根据先判断是否为文件名,然后判断是否为目录的情况处理,或者看作一个请求映射到另一处资源,或者做一次重定向。
上面的内容不必深究,只需要明白浏览器的第一步工作就是对 URL 进行解析。
Http请求
http请求简单来说可以简单概括为一句话:对什么做了什么样的操作,所谓对什么指的是URL,表示标识了的目标对象,做什么样的操作就是所谓的方法,方法主要是分为两个POST和GET方法,其他方法基本没啥用处,个人只在偶尔几个对接文档中遇到过PUT和HEAD方法。
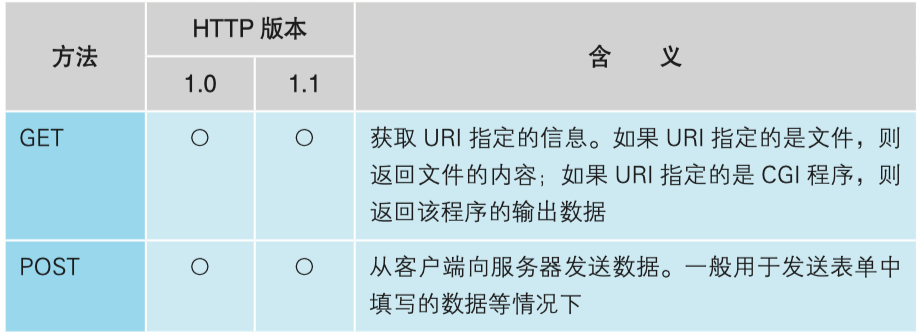
GET方法:通常用于一些可见资源的访问,或者开放资源的访问,通常情况下不需要过多的限制就可以直接向具体的目录寻找需要的资源。
POST方法:比较常见的是使用表单或者 AJAX的方式访问,并且通常会指向一个WEB的应用程序,获取应用程序的数据需要传递服务器需要的一些有效参数,否则服务端会根据具体情况通知客户端无权访问。
AJAX即“Asynchronous JavaScript and XML”(非同步的JavaScript与XML技术),指的是一套综合了多项技术的浏览器端网页开发技术。Ajax的概念由杰西·詹姆士·贾瑞特所提出[1]。
Http请求消息
知道了 对什么做了什么样的操作,现在来看看Http 具体是怎么做这件事情的。
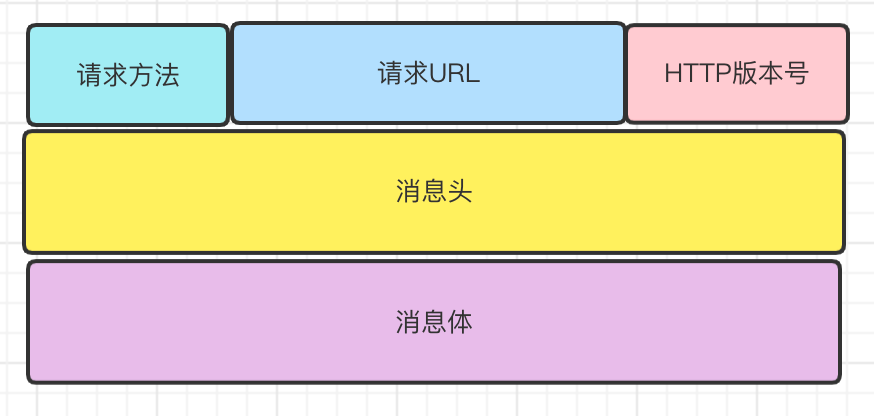
Http请求消息主要分为下面组织结构:
- 第一行最开头的部分提取URL的内容,原封不动解析,末尾为HTTP版本号主要标记当前HTTP请求版本。
例如:
GET /cgi/sample.cgi?Field1=ABCDEFG&SendButton=SEND HTTP/1.1
第二行为消息头,这里列举一些简单的内容:
- Data:请求响应生成日期。
- Pragma:数据是否允许缓存。
- Transfer-Encoding:消息主体编码格式(重要)。
- Via:经过的代理和网关。
消息头后面存在一行 完美没有内容的空行。
第四行为消息体,但是实验用的是GET方法所以通常内容为空。
我们以访问谷歌为例,下面的内容访问谷歌搜索页面的一次请求参考,这里的内容直接通过谷歌浏览器的F12拷贝,可以看到基本包含了请求行,消息头和消息行(GET通常没有所以下面没有体现)三种。
1 | 常规 |
响应内容
响应页面也是类似的需要回应请求行需要的内容信息,同时告知自己允许接受什么样的请求,如果目标IP找不到通常会变为404结果。
1 | 响应标头 |
响应内容相对比较简单,主要关注重点为第一行内容中的状态码和响应短语,请求执行结果是成功还是失败。上面的交互内容需要注意Http请求严格遵循一个请求对应一个响应内容。
注意:1 条请求消息中只能写 1 个 URI。如果需要获取多个文件,必须对每个文件单独发送 1 条请求。
“如何解析网址?”这个问题从头到尾的介绍到这里就完成的,接下来来看看下一个问题”DNS 服务器如何查询域名对应的 IP 地址?”。
IP 和 DNS
首先我们看看IP和DNS是啥,解析网址(域名)和发送请求和响应内容看似是浏览器完成的,实际上它并不具备这些功能, 浏览器收发网络请求实际上需要依托操作系统完成 ,而现代网络基本是TCP/IP 的天下,所以IP发挥关键作用,而DNS存储IP和域名映射的仓库。
- IP:可以类比做我们现实的具体位置,比如XX路XX号,XX路(网络号)对应的的是分配给整个子网的号码,而XX号(IP地址)的号码则分配给子网中的计算机,获得到IP地址之后就相当于锁定了当前计算机所在的具体位置,自然也可以可以找到了。
- DNS:直白来讲就是存储了域名和IP映射的记录的站点,浏览器要获取真实地址需要找DNS才能知道,因为域名放任用户自由定义将会出现同一个域名映射多个IP。
下面我们先观察XX路XX号的号也就是IP地址是如何被找到的。
发送网络的一方通过子网首先需要经过集线器,把内容转发到最近的路由器上,然后路由器会不断跨越找到离接受者更近的下一个路由器,最后再找到集线器然后在转发到接收者的路由器上,路由器在这里是方向盘的角色,而DNS寻址就像是导航。
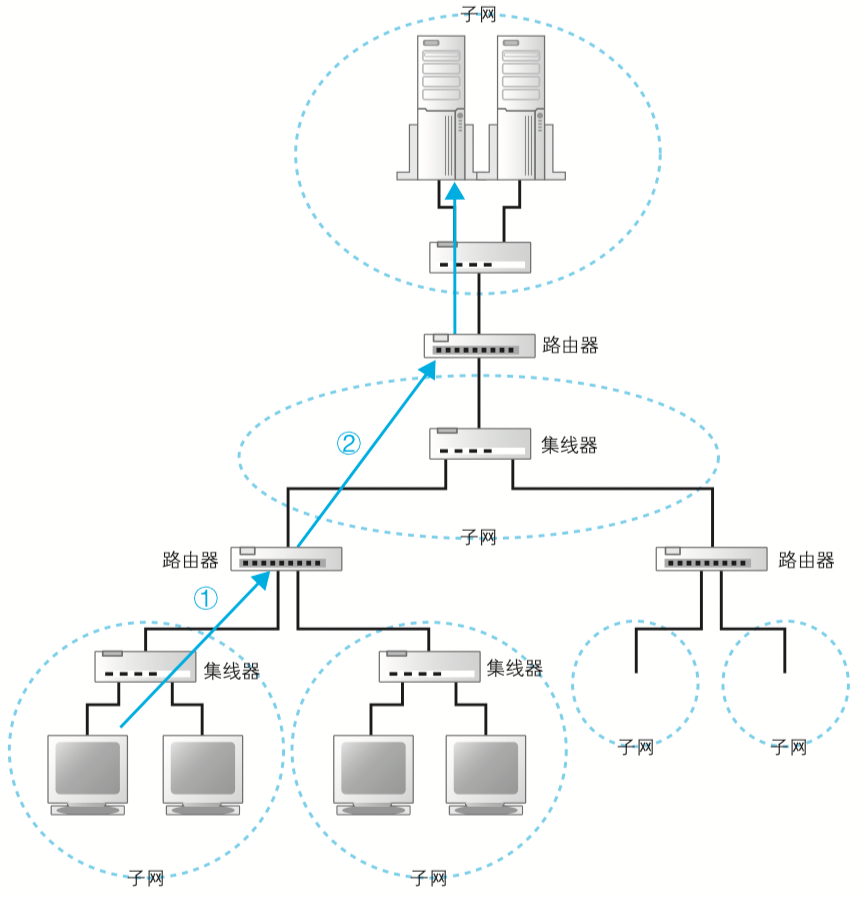
集线器和路由器是什么? A 路由器:一种对包进行转发的设备。 B 集线器:一种对包进行转发的设备, 分为中继式集线器和交换式集线器两种.
IP地址的组成
IP地址是一个32位的Bit数,通过8个bit为一组分为4组,每一组用十进制表示并且使用小圆点断开。
但是仅凭这32个bit是无法定位IP地址和网络号的,所以需要给IP地址附加信息。
通常IP地址的组合有下面的方法:
a)IP地址主体:11.22.33.44
b)IP和子网掩码:11.22.33.44/255.255.255.0
c)网络号的比特数作为子网掩码表示:11.22.33.44/24
d)子网地址:11.22.33.0/24,此时代表了整个子网
e)子网广播地址:11.22.33.255/24
首先整个IP分为32位固定长度,每四个为一组用圆点分隔,通过 0 - 255的十进制表示,比如0就是8个0,255就是8个1,但是仅仅凭借32个位数是没法辨别这32位那一部分是网络号,那一部分是主机号的,所以下面是IP的基本组成:
11.22.33.44:表示基本的IP。11.22.33.44/255.255.255.0:前面部分是基本IP,后面的部分表示子网掩码,表示方式和IP地址一致,注意最后的8位全部为0表示整个子网。11.22.33.44/24: 这个24也是子网掩码,但是表示子网的方式是使用比特数。11.22.33.0/24: 子网掩码没有变,IP地址变了,最后的8位0也是表示整个子网。11.22.33.255/24: 子网掩码没有变,IP地址变了,最后的8位全部位1表示广播 整个子网。
什么是子网掩码?
初学者可能比较难以理解的概念,这里如果看不懂建议多找找资料挑一个看得懂的解释(关键是自己理解并且能自己复述)。
下面是从书中原图,个人看完感觉并不是特别直观也不知道干嘛,所以做了一个补充说明。
实际上下面图中网络号用了AND(位操作 &)计算出网络号码,计算之后确认出网络号是10.1.2,而后面省略的部分其实是8个0的掩码掩盖主机,这里的子网就是 10.1.2.0,对应的主机IP是10.1.2.3。

如果看不懂上面说的是啥,这里补充解释一下:
首先我们需要清楚子网掩码这东西是干嘛的,说白了就是划分网络号和主机号的,网络号可以看作一栋楼,主机是里面的小房间,但是房间编号可能是101,也可能是0101,更有可能是00101,具体得看掩盖的房间号从0000到1111有多少个,决定能分配给多少主机,而计算机0又很特殊,所以网络号的部分+ 子网掩码掩盖的位数部分(表现全为0)组成一个子网,只有在同一个子网的主机才能互相通信。
所以子网掩码不能单独存在,它必须结合IP地址一起使用,子网掩码主要分为两个部分:全为1表示网络号,全为0表示的是主机号。
那么我们随便设置一个子网掩码比如255.255.255.111行不行?
答案是不行,不行,不行。因为子网掩码 必须是 连续的 1和0 组成,上面的掩码255.255.255.0 才是正确的用法,再举例比如255.255.255.244也是合格的子网掩码。
我们举例说明一下:
1 | 1100 0000.1010 1000.0000 0001.1000 0001 -- 192.168.1.129 |
从最终的结果来看192.168.1.0 的前面24位都为1是暴露的,而后面8位被子网掩码给遮掩住,所以他的另一种写法是192.168.1.0/24,表示24位是1代表网络号,剩余的8位用于表示主机号但是因为被掩盖了所以全部为0。
虽然被掩盖了,但是主机号位置是0是1不需要关心的,主机号如果落在192.168.1.0到192.168.1.255表示同在一个网段内子网一视同仁,比如192.168.1.129表示其中的129位,包含在这个网段之内。
小结
- 子网掩码 必须是 连续的 1和0 组成,简单记忆为1的部分来分割网络号,为0的部分用于掩盖主机号,同一个子网内的主机可以互相通信。
- 子网掩码有两种写入方式一种是使用和I P 地址一样的32位完全表示方式,另一种是使用数字计算1比特数进行替换,比如24就是下面图中的24个1。
- IP 地址的主机号,全 0表示整个子网,全 1表示向子网上所有设备发送包。这里补充一下全为1的情况 - “广播”。
广播是什么意思?广播地址是专门用于同时向该网络中所有主机进行广播的一个地址,只要是在同一个网段的主机都可以收听到广播。(例如
192.168.211.32/24的广播地址为:192.168.211.255)
DNS
DNS: Domain Name System 域名服务系统,最常见的用法是将服务器名称和 IP 地址进行关联,当然只是它的主业,他有一些副业也挺重要但是不是关键感兴趣了解即可。
IP是难以记忆的,而简短域名更容易被人记住。你可能会觉得域名长了也难记忆啊,虽然解析IP的速度要比解析域名来的快的很多,但是显然网民为了访问一个网站要记住一串数字显然是不可能的,同时域名实际上对于当时的互联网发展来说也是有意义的。
所以谁来告诉主机域名的真实IP是多少?这时候DNS就上场了,DNS的作用是说白了就是用来映射IP和域名的一个东西。
DNS是如何完成映射的?对于用户主机来说一定存在一个用于解析DNS的客户端,这个客户端通常被称为解析器,通过域名解析出IP地址的过程也被称为域名解析。
调用解析器
那么如何调用解析器?解析器实际上就是一段程序代码,这一段程序代码包含在底层操作系统的Socket库当中,通过Socket库调用解析器,然后解析器会向 DNS 服务器发送查询消息, DNS 服 务器根据请求查询IP然后返回响应消息。
Socket 解析域名的过程非常简单,只需要一行代码就可以完成:gethostbyname("www.lab.glasscom.com");。
库:指的是通用程序组件的集合,用于规范程序代码的规范组建。以解析器为例,Socket 库是用于调用网络功能的程序组件集合。
解析器内部又是如何工作的?
在应用程序调用解析器的时候,此时控制权会转移到解析器,当控制权转为解析器之后解析器会生成要发送给 DNS 服务器的查询消息,生成过程类似构建一条“请告诉XXX的IP地址”的消息,并且发给DNS服务器完成解析。
特别注意注意发送请求不是由解析器完成,而是需要再次委托给操作系统的协议栈完成,所以此时权限会再次转移到协议栈,协议栈最终通过网卡把消息发给DNS,然后DNS查到IP返回消息,至此一次DNS解析请求就完成了。
值得注意的是 解析器会将取出的 IP 地址写入应用程序指定的内存地址中,此外还需要注意请求DNS服务器本身IP也是需要配置的,只不过这个 IP 地址是作为 TCP/IP 的项目事先设置好的,不需要再去查询直接就可以获取。
最后在不同的操作系统中获取DNS服务器的地址方式会有差别。
根据上面的描述,总结DNS解析流程:
- WEB浏览器发送域名解析请求,通过Socket向解析器进行请求解析,此时应用程序将会挂起。
- 解析器负责“翻译”应用程序的DNS解析请求,但是把具体的请求操作委托给系统栈。
- 系统栈负责将请求通过网卡发送给DNS服务器,等待DNS反馈结果。
- DNS获取真实IP之后将结果通过链路反向回送到应用程序。

DNS工作
接下来我们看看dns要如何工作,dns需要查询用户消息包含下面几个部分:
- 域名:用来替代IP方便记忆。
- class:考虑到互联网之外的情况,当然外部网络现在只有标识为in的互联网。
- type:表示记录类型用于区分dns的解析方式,不同类型结果不同。
需要注意的是所有a类型的记录在DNS上注册了,再比如所有邮件类型都是MX的类型,整个DNS工作其实就简单的根据类型和域名进行查表,找到匹配的就回传,否则就会找不到。
域名层次:所谓域名层次就是DNS不可能是一台服务器,而是需要多台服务器配合,各自管理自己范围的内容,而对于域名来说越靠右边的部分在域名的层次里面越高。
这样看来是不是有点意思,以日常生活举例并不是我们认为的www是最高,其实他是最低的等级,.com才是最高的。
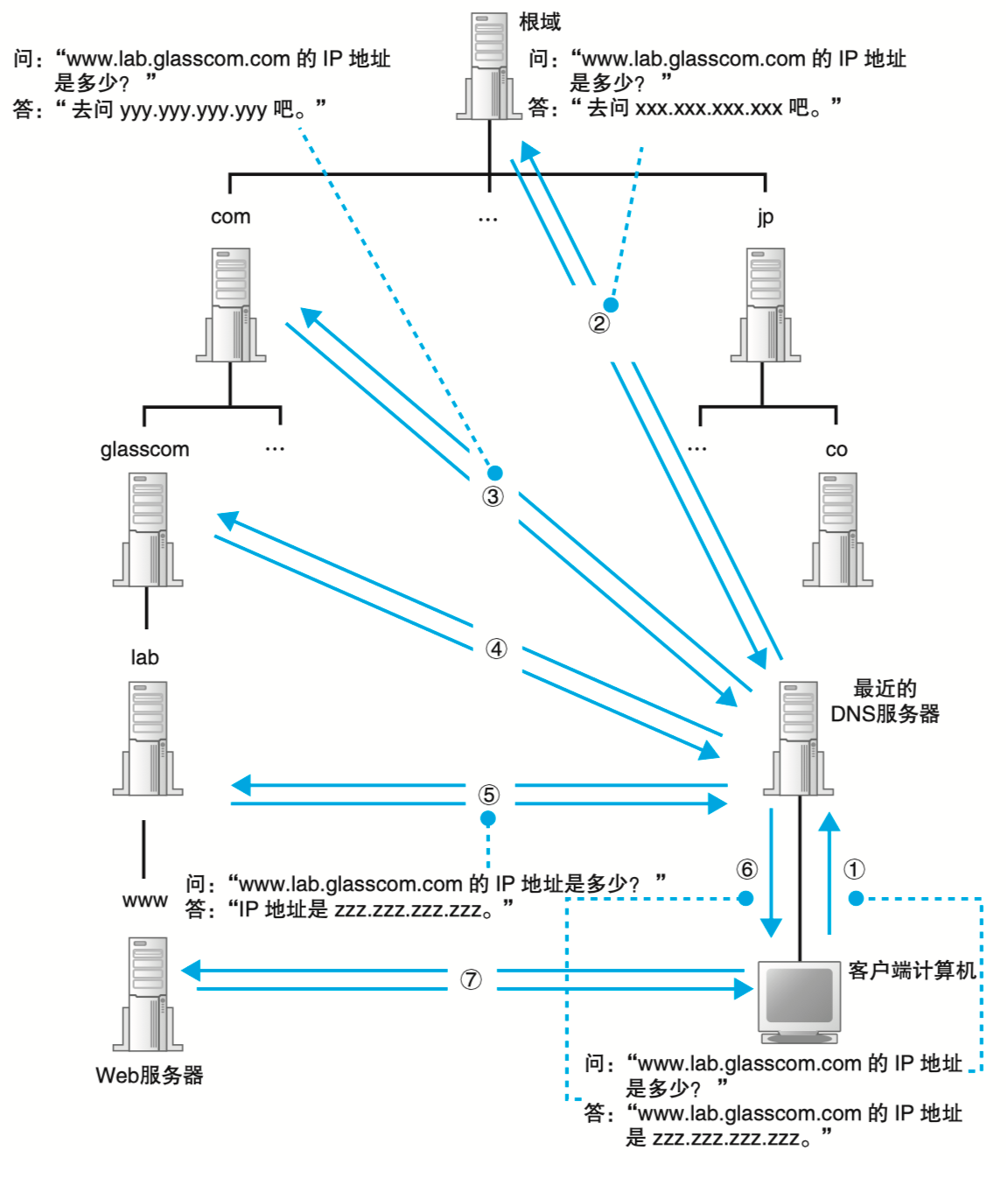
DNS查找步骤
首先将负责管理下级域的 DNS 服务器的 IP 地址注册到它们的上级 DNS 服务器中,然后上级 DNS 服务器的 IP 地址再注册到更上一级的 DNS 服务器中,以此类推。
举个例子,需要解析等域名为www.baidu.com,DNS需要事先把整个www.baidu.com整个域名注册到baidu.com,再把baidu.com注册到com域名,再把com注册到根域,这样就可以通过上级找下级。
这里提到DNS有一个根域,根域名指的是就是一个句点 . ,和Linux的根路径意义表现形式上类似。
根据根域可以解释为什么任何奇怪等域名都可以被访问到,原因是所有的下级都会注册到上级中,最后都有一个共同的 ,如果所有下级要找到根域,自然需要注册根域这个句点。
DNS查找的过程是自下而上找最近的DNS然后自上而下找根域向下查找的的,也就是先找最近的dns找,没有找到就需要直接从根域进行查找,一路通过层级下探找到最终的ip,这也是为什么访问国外ip慢的原因,因为路由链路实在是很长,可能需要几十次dns搜索查找。
DNS缓存
如果每个主机每次请求总是要通过DNS获取域名对应的IP信息,是不可能每次都DNS让找一遍的,实际上解析到的真实IP会预先缓存起来下次访问重复的数据直接返回即可。
另外虽然前面介绍的是查找自上而下从根域向下查找,实际上DNS还可以利用缓存特性通过多个层级的共享域名加快访问速度跨级查找,比如www.baidu.com和www.baidu 可以共享缓存直接跳两个层级快速找到(当然这里其实找最近的一个DNS就能找到,这里仅仅是举例)。
但是缓存有个副作用,就是不存在的ip地址消息也会缓存,不过为了防止这种情况一般会有过期时间,过期之后依然需要再次走一遍DNS查找流程。
问题引导:问题
- http://www.nikkeibp.co.jp/ 中的 http 代表什么意思?
表示的是HTTP 协议
- 下面两个网址有什么不同?
a. http://www.nikkeibp.co.jp/sample
b. http://www.nikkeibp.co.jp/sample/
区别点在于sample 可能被解析出和预期不符合的结果。
用来识别连接在互联网上的计算机和服务器的地址叫什么?
IP地址
根据 Web 服务器的域名来查询 IP 地址时所使用的服务器叫什么?
DNHS服务器
向 DNS 服务器发送请求消息的程序叫什么?
解析器。