HTTP 缓存技术
缓存技术出现在HTTP1.1当中,目的是尽可能的减少对于服务器进行请求。为了实现缓存技术,HTTP设计者在头部字段增加针对缓存的头部字段。HTTP 缓存有两种方式,强制缓存和协商缓存。
认识缓存
介绍具体的缓存技术之前,我们先来认识一下HTTP中的缓存特点。
注意缓存只对获取文件有效,从服务器上拿到文件然后放入本地缓存,下次再获取则从本地缓存区获取文件,这样可以减轻服务器压力。
缓存技术在HTTP中的体现是通过几个请求字段的配合,按照一定的判断流程控制。HTTP1.1主要通过下面三个请求头部信息判定缓存有效性:
Cache-Control:服务器可以返回此字段指定浏览器和中间缓存应该存活多久。ETag:浏览器缓存过期的时候,通过Etag令牌检查文件是否出现改变。Etag 是特殊算法计算的唯一哈希值。Last-Modified:和Etag用途相同,但是它是基于时间的策略检查是否更改。
这三个字段基本囊括大部分HTTP缓存技术的应用场景。
缓存位置
缓存位置通常存在下面几种:
- Service Work
- Memory Cache
- Disk Cache(常用)
- Push Cache
Service Work
通常运行在浏览器的后台,主要功能是实现缓存,使用此组件需要请求协议为HTTPS,因为Service Work 本身会拦截请求,需要 HTTPS保证安全才能使用。
Memory Cache
内存中的缓存,主要是当前页面已经捕获的资源。比如图片,脚本等,这种方式要比Disk Cache 要快上非常多,但是注意这个缓存寿命非常短,一旦关闭Tab,内存缓存会随着页面的关闭立马释放。
内存缓存中有一块重要的缓存资源是 preloader 相关指令,也是页面优化的手段之一,可以做到解析脚本和CSS文件的同时请求下一个资源。
Disk Cache
Disk Cache 存在于磁盘的缓存,读取虽然慢一点,但是可以实现持久化存储,并且容量比内存缓存要宽泛很多。
Disk Cache的覆盖面在浏览器中占用比重很大,通常结合HTTP头部字段进行判断,如果跨站点下载文件,已经下载过的文件不会再次请求,而是直接从Disk Cache 获取。
如何判断缓存进内存还是进磁盘?
通常有两个依据:
- 如果是大文件,通常会进入磁盘当中进行缓存。
- 如果是频繁访问的文件,也会放入磁盘。
Push Cache
推送缓存是HTTP/2 新加入的内容,上面三种情况都没有命中的时候才会尝试使用。它是会话级别缓存,一旦会话结束,也会立即释放缓存,生命周期只比内存缓存长一点点。
缓存过程
缓存的大致流程如下:
- 客户端发起HTTP请求访问浏览器缓存,浏览器不存在缓存,告知客户端让它重新发请求。
- 客户端再次发起HTTP请求到原始服务器,原始服务器返回结果和缓存规则。
- 客户端再次发起请求,从浏览器的缓存中获取请求结果。
注意第一步是隐式处理的,所以缓存过程主要有两个要点:
- 每次请求都会检查浏览器是否存在缓存标识,以及请求的缓存结果。
- 如果没有特殊字段禁用缓存,缓存将会把请求结果缓存存在浏览器缓存当中。
缓存判定主要依赖两项技术:强制缓存和协商缓存,也是HTTP缓存技术的要点。将在下文进行进行介绍。
Pragma 头部
Pragma 于 HTTP1.0 中定义,单词含义叫做“编译指令”,几乎可以包含任何内容,目的是给浏览器发送请求中进行一些指令操作,但是主要的应用场景是缓存操控。
Pragma主要作用是保持 HTTP1.0 向后兼容,因为缓存技术是在HTTP1.1中才出现的。
比如让一些HTTP1.0的源服务识别客户端理解”无缓存“的请求头部,这时候Prama就可以派上用场。
Pragma 如果被发送,将会应用于所有的应用程序和客户端。如果存在HTTP1.1缓存技术的相关请求头部字段,在服务器可以识别的前提下,会优先解析HTTP1.1的请求头部,从而忽略Pragma头部。
但是这里介绍的所有内容都是 HTTP1.0 约定俗成的东西。HTTP1.0 本身不能算作标准,只能算作“草稿”,所以 Pragma 既没有明确规范,也没有可靠性,现在的网络环境这个字段基本不再使用。仅仅是有可能的向后兼容场景中用到。
介绍这些内容,只是让大家知道点历史。
Pargma 头部使用方式
基本语法 Pragma: 1# pragma-directive
举例 Pragma: no-cache(实际上也是唯一取值)
强制缓存
强制缓存指的是只要浏览器没有过期,就使用缓存进行返回,主动性在浏览器方。
比如下面的请求当中,使用了缓存进行返回,强缓存利用两个响应头部实现, 相对时间“Cache-Control” 以及 “Expire”绝对时间 两个字段。
在讲述Cache-Control之前我们先停一下,先来了解后面这个过时的东西Expires。
Expires 有什么用? 这个字段的作用是设置一个特殊的时间,一旦超过这个时间,就会过期。简而言之就是所谓的绝对时间,比如我们设置时间为 Expires:Sat,13 May 2022 07:00:00 GMT,意味着一旦超过这个时间就会失效。
但是这个时间是存在问题的,虽然原始服务器的时间无法更改,但是 客户端时间是可以自由改动的,这样就会导致客户端时间和服务器时间不一致,出现缓存一致性问题,你也可以把这种乱改时间的方式叫做the world(砸瓦鲁多)。
此外Expires日期时间必须是格林威治时间(GMT),而不能是本地时间,也不能随意指定日期格式,局限性比较大。
如果设置的Expires过期时间是固定时间,但是返回之前没有没有更新下一次过期时间,那么每一次客户端的请求都会进入到服务端,会加大服务端压力,缓存的意义也就失效了。
于是Cache-Control针对Expires的局限性进行改进而在HTTP1.1中登场。
如果同时有 Cache-Control 和 Expires 字段,Cache-Control的优先级高于 Expires 。所以通常情况下不建议使用 Expires,如果非要使用,建议用在静态资源上给资源设置绝对过期时间,或者作为双保险兼容所有HTTP代理服务使用。
此外Cache-Control和Expires这两个字段的区别是 Cache-Control 字段的选项要多一些,Cache-Control是HTTP1.1标准协议中出现并推荐使用的,Expires 是HTTP1.0的规定,但是HTTP1.0并不是明确标准,不具备任何约束力。
HTTP 1.0 虽然明面上属于草稿纸协议,Expires看似也不推荐使用,但是后续的协议并没有废弃它,所以还是有一定的存在意义的(前后兼容问题)。
首部字段 Expires 会将资源失效的日期告知客户端。如果不希望资源被缓存,则建议把首部字段 Expires 和首部字段Date设置相同的时间。
强制缓存的使用策略
- 第一次访问服务器资源,服务器会在返回资源的同时返回这两个字段,同时为这两个字段设置过期时间。
- 浏览器第二次乃至更多次访问,首先比对 Cache-Control的时间是否过期,如果有就使用缓存,没有就重新请求。
- 再次请求会更新
Cache-Control,之后以此反复。
Cache-Control例子
例子网址:https://web.dev/i18n/en/http-cache/#examples
Cache-Control价值 |
解释 |
|---|---|
max-age=86400 |
响应可以由浏览器和中间缓存缓存长达 1 天(60 秒 x 60 分钟 x 24 小时)。 |
private, max-age=600 |
响应可以由浏览器(但不是中间缓存)缓存长达 10 分钟(60 秒 x 10 分钟)。 |
public, max-age=31536000 |
响应可以由任何缓存存储 1 年。 |
no-store |
不允许缓存响应,并且必须在每次请求时全部获取。 |
Cache-Control 字段选项
max-age:此参数为高优先级,代表缓存的最大存活时间,单位为秒,其实时间为客户端接受响应的那一刻计算。no-cache:浏览器在每次使用缓存之前都必须使用服务器重新验证。注意这个字段并不是禁用缓存的真正含义,这里暂时卖个关子,下文继续解释。no-store:缓存不应该缓存任何客户端和服务端的内容,实际上的不使用缓存。和no-cache的区别是这个设置完全才是真实的不使用缓存。public:表示资源可以由任何代理进行缓存。private:表示指定资源专属于特定用户,虽然依然可以缓存,但只能在客户端缓存,比如私有的网页响应由桌面浏览器缓存,不能给CDN进行加速。
注意在
Cache-Control指定max-age的属性时候,比起首部字段Expires,会优先处理max-age。
在 《HTTP权威指南》 可以看到更多字段解释,上面仅仅列举一些常用字段。
重点关注 no-cache,很容易误解含义的一个属性。


s-maxage
有时候我们会看到下面的请求属性:s-maxage
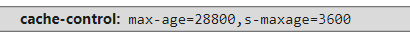
它所表示的含义是覆盖max-age或者Expires头,但是仅适用于共享缓存 (比如各个代理),私有缓存会忽略它(private)。
Cache-Control案例
通过下面的案例可以看到,内容是从disk cache本地返回的,没有请求服务器。
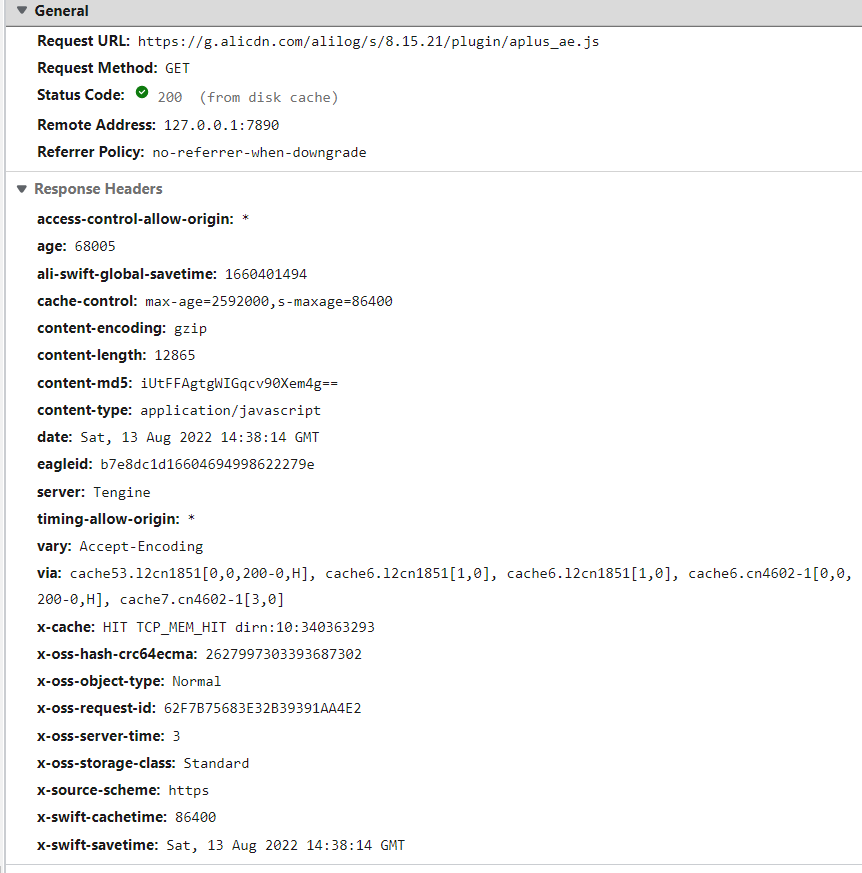
强制缓存除了 from disk cache 之外,还有可能遇到使用from memory cache进行返回,表示同样不会访问服务器,但是返回的内容是从内存中来的,并且因为是内存所以如果关闭当前页面会被立马释放。
更多有关Cache-Control的内容可以看看下面的资料网站。
Cache-Control - HTTP | MDN (mozilla.org)
Expires 和 Cache-Control 两者对比
这个比较容易被问到,所以这里再啰嗦一遍。其实本质上区别并不是很大,只不过Expires 是 HTTP1.0 出现的,要比Cache-Control (HTTP1.1)出得早而已,并且Cache-Control本身就是为了替换Expires 而存在的。
虽然目前大部分网站都是支持HTTP1.1 的,但是如果真的碰到只能识别HTTP1.0 的服务器,此字段依然有存在价值,所以这种做法只是一种保证前后兼容的稳定而已。
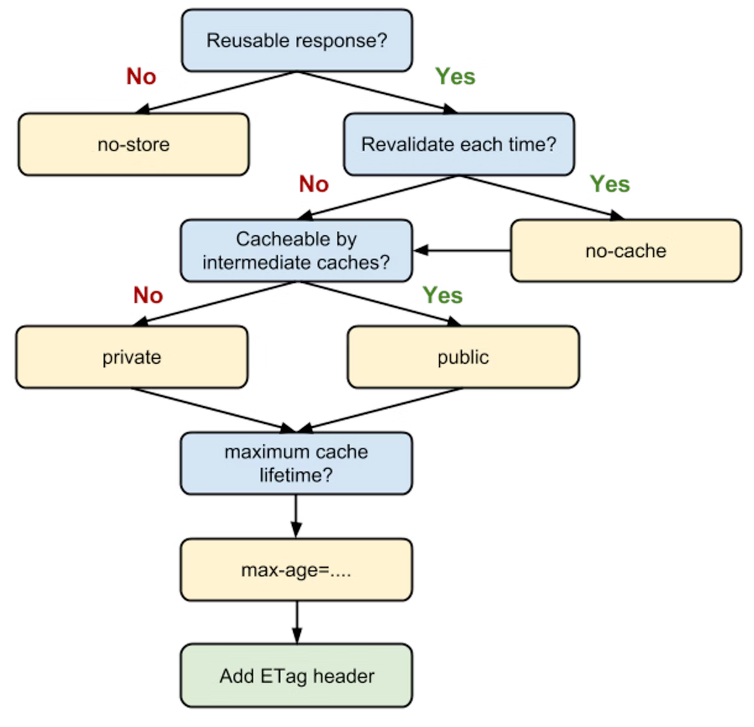
Cache-Control 流程图
图来自老外的博客:# Prevent unnecessary network requests with the HTTP Cache
需要注意最后一步的Etag,是协商缓存中的重要判断依据,这部分内容会在下文解释。
no-cache VS no-store
“no store”请求指令指示缓存不能存储此请求或对其的任何响应的任何部分。
The “no-store” request directive indicates that a cache MUST NOT store any part of either this request or any response to it. This directive applies to both private and shared caches.
no-store 比较好理解,它是真正意义上的不使用缓存,含义是禁用中间代理(浏览器,CDN,缓存服务器、代理)缓存响应内容,行为类似非代理缓存服务,一旦碰到缓存就会删除。

“no cache”请求指令表示,如果未在源服务器上成功验证,缓存不得使用存储的响应来满足请求。
The “no-cache” response directive indicates that the response MUST NOT be used to satisfy a subsequent request without successful validation on the origin server.
上面是RFC协议的原话,这个定义非常容易误解,隐藏的含义是:实际上no cache 是会进行缓存的。
什么时候缓存呢?在与原始服务器进行新鲜度再验证之前,缓存不能将其提供给客户端使用。而如果再度验证服务器没有对于内容进行更改,那么还是使用缓存数据进行处理。
简而言之就是一句话:如果服务器没有更新内容,那么就会缓存数据,否则需要重新请求和服务器进行验证比对。
大多数人会理解错这一层含义,会误认为是“不接受服务器的缓存响应”,实际上它是会接受的。《HTTP权威指南》解释说这个首部更适合用 do-not-serve-from-cache-without-revalidation(不需要请求服务,直接用缓存,除非服务器重新验证) 这个名字会更恰当一些,我们同样可以按照作者的建议进行理解。
但是这里肯定又会问,你都no-cache了我怎么知道什么时候响应新内容呢?
先别急,这里有一套稍微复杂的判断机制:协商缓存,学东西一点一点来,我们接着看其他几个强制缓存的问题。
max-age=0 和 no-cache 等价吗?
这个问题比较偏门,但是作为面试题角度比较刁钻。
两者的区别是max-age=0通常是告诉浏览器建议刷新缓存,max-age=0是非强制性(Should) 的,no-cache要求强制和服务器进行验证才允许使用缓存,所以no-cache 具有强制(MUST)性。
但是怎么处理还得看浏览器的设计,所以不考虑浏览器设计的因素下,可以认为行为比较一致,或者直接自信点:它们差不多。
什么样的请求方法会被缓存?
- GET 请求通常具备缓存失效。
- HEAD方法跟GET方法相同,只不过服务器响应时不会返回消息体,所以HEAD请求会被缓存。(比较容易被忽略)
- PUT 无法被缓存。
- POST 缓存在指定明确的过期请柬请求字段的时候可以使用,但是基本没有被实施。
HEAD 很容易被忽略,实际上它具备一定的作用:
- 检查连接是否活跃(active)。
- 检查网页是否存在改动。
- 多用于获取RSS,网站标志等信息的场景使用。
缓存优先级判断
采用下面的顺序:
- 如果是共享缓存并且存在
s-maxage,则为最高优先级。 - 检查是否存在max-age。
- 检查是否存在Expires,需要使用此时间减去响应字段的Date字段值,算出来的数值就是有效期。
需要提醒这些时间是不会和时区产生影响的,因为返回的都是原始服务器的时间。
但是在这里我们发现一个问题,如果上面条件都不满足,如果不存在到期时间咋办?
因为原始服务器的时间并不是总是可靠的,如果请求当中没有任何“新鲜度“(max-age、Expires等过期时间)设置,请求头部也没指定任何禁用缓存和任何限制,那么这时候需要用heuristic expiration time这个值。
heuristic expiration time(中文说法:启发式缓存时间),在《HTTP权威指南》叫做试探性过期时间,其实是利用其他字段的算出一个“合理”的估计值(也就是 Last-Modified)。
关于计算的方法,在RFC规范柄中没有强制如何设计,而是在协议中给出下面这句话:
If the response has a Last-Modified header field (Section 2.2 of [RFC7232]), caches are encouraged to use a heuristic expiration value that is no more than some fraction of the interval since that time. A typical setting of this fraction might be 10%.
如果响应具有Last-Modified header的标头字段(RFC7232的第2.2节),则鼓励缓存使用启发式缓存时间值,该值会计算一个不超过自该时间起间隔 * 某个比例(的时间)。比例的经典设置可能为10%。
这是嘛意思?没看懂呀,其实这里要联系RFC原文的前后文了,这里就不贴英文了。大致意思是在优先级判断中的第三点判断,有效期计算被定义为Expires-Date字段。
如果服务端返回Last-Modified header ,则计算方式为 Date字段 - Last-Modified字段值。
但是如果直接这样计算有可能会太长了,RFC给出 10 % 的建议值。这个建议值有这两点考虑:
- 很久之前存放的文档一般不会更改,所以留在缓存很安全,10%估计值的比率尚且可以接受(?)。
- 频繁更新的内容通常缓存收益很小,使用估计值10%可以尽可能减少缓存时间,尽可能的返回最新内容。
更新频率不同长短的资源都能收益,这样看起来这处理方式是不是很不错呀?但是
想法是好的,现实是这样做会带来更多麻烦,这点放到下面讨论。
总而言之,不满足缓存优先级判断,浏览器通常会用 Last-Modified字段值 计算一个合适的参考值作为缓存过期时间存在,最终的计算公式为:
Last-Modified Time - Date * 0.1 (10%)`
当存储的响应中存在显式过期时间时,缓存不得使用启发式缓存时间来确定新鲜度。不能使用此算法。官方这话是在暗示你要尽量给资源设置缓存过期时间,因为我建议的这东西不是特别靠谱。
目前多数浏览器使用 LM-factor 算法(也就是上面的公式),使用的也是RFC协议建议的比例 10 %,20% 这个说法现在来看已经过时。

10%以及悲观估计依据:
This specification does not provide specific algorithms, but does impose worst-case constraints on their results.
本规范未提供具体算法,但对其结果施加了最坏情况约束,所谓的最坏情况约束就是 10%。
113 响应状态码
这里有个偏门的 113 响应状态码,表示如果缓存使用了超过24小时的有效时间并且响应时间大于24小时,不应该采取任何操作。1XX状态码需要后续的确认操作。
但是实际上很多浏览器压根没有搭理过这个建议,也没有做响应措施,这一点需要注意。
如果Last-Modified都没有怎么办?
乖乖,如果这都没有的话,缓存通常会为没有任何新鲜周期线索的文档,分配一个默认的新鲜周期(通常是一个小时或一天)。
有时比较保守的缓存会将这种试探性新鲜生存期设置为 0,强制缓存在每次将其提供给客户端之前验证一下这些数据是否仍然是新鲜的。
启发式缓存时间坏处
凡事都有例外,启发式缓存时间本意是好的,但是存在明显的弊端。
假如一个文件超过一个月没设置过期时间,并且已经经过一个月的时间,这时候发现文件存在严重问题,需要立刻修复。
这时候一旦修改,会导致上个版本3天之后才过期(1个月的10%=3天左右),意味着更新一个文件需要至少3天(20%就是将近一周),请求才会传新文件。如果使用CDN,这个时间还会更长。
当然这种问题解决方案也很多,比如在设置文件的时候带上版本号或者编号,比如对外进行 302 临时重定向到另一个位置并且设置过期时间,或者先删文件再后重新添加,并且手动强制同步。
综上所述,尽量不要使用启发式缓存,尽量给每个请求设置过期时间,但是也不要设置过长时间,长时间的强缓存会因为CDN等缓存服务器的关系导致一个资源迟迟难以更新(哪怕没有启发式缓存时间)。
新协议对RFC2616的改动
注:[RFC2616] 第13.9节禁止缓存计算带有查询组件的URI的启发式新鲜度(即包含“?”的URI)。此项在实践中,这并没有得到广泛推广。
综上所述,如果源服务器希望排除缓存,则鼓励它们发送显式指令(例如,缓存控制:无缓存)。
新响应的计算方式
下面这个公式是判断依据:
response_is_fresh = (freshness_lifetime > current_age)
判断依据十分简单,新鲜度的时间是否超过寿命,超过寿命就需要丢弃缓存重新请求。也正是因为这种简单粗暴的手法,使得缓存既能够提供便利的同时,不至于对于用户访问造成过多影响。
响应表头设置建议
因为启发式缓存时间的存在,强烈建议重要的文件资源都加上缓存有效期。针对缓存有效期的响应头设计,通常有下面的几点建议:
版本化URL
比如针对CSS文件设置了长达一年的缓存过期时间,如果出现临时更改,有的用户如果刚好清除缓存可以看到最新的内容,而没有清除缓存的可能拿到本地旧版本文件。这样可以有更好的用户体验,旧缓存数据的用户在刷新缓存之后就可以看到新内容。
通常情况下,在文件名中嵌入文件的版本号来执行此操作,例如style.x234dff.css。
无版本化URL
如果是没有版本化的URL很久突然要进行更新,则需要尽量添加头部。
Cache-Control值可以帮助我们微调未版本化 URL 的缓存位置和方式:
- no-cache:缓存请求当前URL的版本数据之前需要和服务器进行验证。
- no-store:屏蔽中间代理服务器的缓存行为,不存储缓存文件。
- private:浏览器可以缓存文件,但是中间代理缓存服务器不能缓存。
- public:响应可以被任何缓存进行存储。
协商缓存
缓存生效的情况下,浏览器会返回304状态码。协商缓存是在强制缓存失效之后,需要重新对比缓存,由服务器决定是否失效的一种机制。
304:请求的资源没有改变,但是被重定向到已缓冲的文件,所以也叫做缓存重定向,这个子弹主要是用于缓存处理。
协商缓存的请求步骤通常分为两步。
初次访问:
客户端请求依然需要发送到服务端,但是服务端会通知浏览器缓存请求响应信息,浏览器这时候会偷偷缓存请求。
第二至更多次访问:
1. 假设客户端请求资源已经过期,则在请求中携带Etag 访问服务器。
2. 服务器比对Etag进行校验,比较是否和本地一致。
3. 如果一致返回304,浏览器可以继续使用资源。
4. 如果不一致就需要重新返回请求结果,再次进行缓存。
协商缓存实际上就是浏览器和服务器进行协商通过协商的结果判断是否使用本地缓存。
主要涉及的请求头部
注意这里一共有两组四个字段进行判断,ETag和If-None-Match(一组), If-Modified-Since 字段与 Last-Modified 字段(一组),前者优先级比后者高,同时出现会出现“短路效应”。
ETag和If-None-Match
两者的值都是资源的唯一标识符(实际为文件资源的哈希散列值)。
判断过程如下:
- 浏览器请求资源,原始服务器返回报文中加入
Etag值,资源更新则Etag值也会更新。 - 浏览器再次请求资源,此时请求报文会加入
If-None-Match,值为上一次响应报文的Etag值。 - 服务器比对报文的
If-None-Match和当前的Etag是否一致,不一致则更新Etag并且返回,下一次浏览器请求Etag将传输新的值。如果一致表示资源没有更新,状态码返回304,浏览器从本地缓存获取,此时响应头会同时返回Etag值。(虽然没有变化)
If-Modified-Since 字段与 Last-Modified 字段
位于请求头部的If-Modified-Since 字段以及位于响应头部中的 Last-Modified 字段。
- 响应头部中的
Last-Modified字段:表示资源的Last-Modified( 最后修改时间)。 - 请求头部的
If-Modified-Since字段:资源过期并且接收响应头部出现Last-Modified(最后修改时间)声明,会发送此字段,并且此字段值等于Last-Modified( 最后修改时间)。
判断流程如下:
- 浏览器第一次向服务端请求之后,服务端响应中加入
Last-Modified字段,表示资源最后一次修改时间。 - 浏览器再次请求,在请求报文中会加入
If-Modified-Since字段,字段值等于上一次浏览器返回的Last-Modified(最后一次修改时间)。 - 服务器比对
Last-Modified和If-Modified-Since字段,如果不一致则接受请求并且返回更新之后的资源,如果一致表示资源没有更新,返回304状态码,此时浏览器会从本地缓存获取资源文件。值得注意的是,本地请求如果是304,此时响应头中不会再添加Last-Modified字段。
协商缓存和强制缓存流程图
这个图来自参考文章的第一篇,画的很棒,为作者点个赞:
注意:If-None-Match 和 If-Modified-Since 的关系是:
If-None-Match && If-Modified-Since。
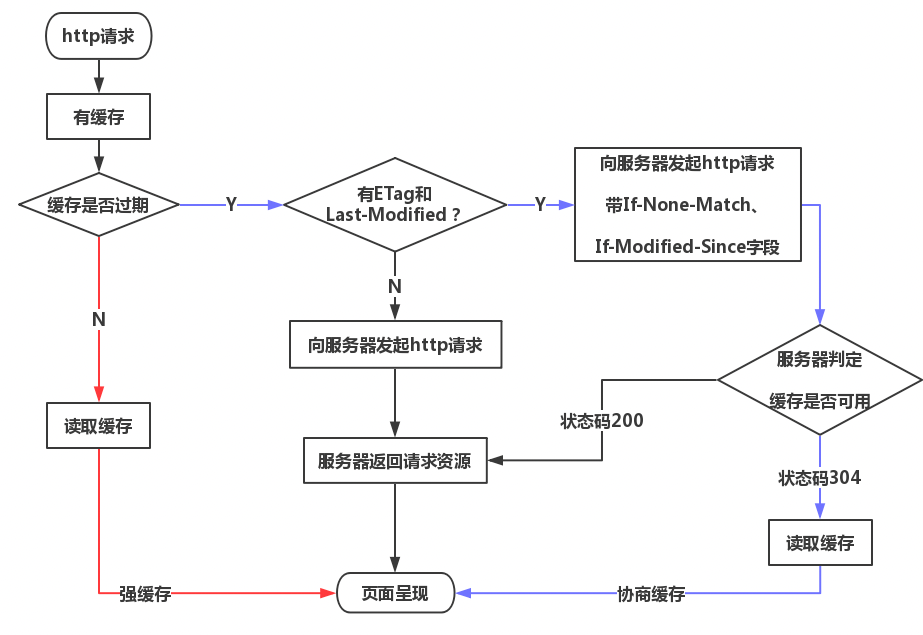
下面的图和上面类似,不过把If-None-Match和 If-Modified-Since丰富了一下:

如果同时发送If-None-Match 、If-Modified-Since字段怎么处理
此时服务器只要比较If-None-Match和ETag的内容是否一致即可,内容一致则返回304并且依然使用,不一致则返回新的请求结果,并且重新缓存。
If-None-Match判断优先级总是要高一些,IETF同样如此建议。
Etag 和 Last-Modifed 对比
Etag和Last-Modifed效果是相同的,为什么相同的功能需要两个字段控制?
首先说一下结论,Etag 实际上更为推荐并且更常使用,因为它的细粒度更小,下面我们举个例子,再进行总结。
我们先来举个栗子,假设一个资源从资源请求开始到当前请求过去了120秒接近过期节点,并且浏览器启用了同一个资源的新请求,此时HTTP刚好卡在过期节点之前找到缓存。虽然查到的缓存在获取那一刻是没有过期的,但是他不能这么干,因为此时在浏览器看来响应已经过期了,浏览器需要重新发一个新请求获得完整响应。
上面的例子本意是好的,但是如果资源没有出现改变,就没有必要下载已经在缓存本地的信息,这么做明显是浪费服务器资源。如果很多个请求都在这个临界点访问,这样会加大服务器资源的浪费。
所以基于时间的判断是不可靠的,Etag标头负责检查文件内容的哈希码,浏览器不需要知道哈希算法,只需要拿客户端请求的Etag值和当前本地缓存比对即可,如果Etag值一致,哪怕此时请求资源响应已经过期了,依然可以用本地缓存文件返回,跳过下载步骤。
有了上面的案例,下面我们知道了为什么要引入Etag,下面是相关结论。
结论
- 有时候文件仅仅是改了日期(比如重新传了一份一模一样的覆盖),我们可以认为文件内容是没有改变的,依然可以用本地缓存而不是GET请求。
- 文件如果改动非常频繁但是内容没有改变,
Last-Modifed是S(秒)级,控制粒度大,很容易出现请求响应过期,并且频繁的重新下载。 - 某些服务器不能精确表示最后修改时间,只能给出笼统的日期。
总的来说就是基于时间的判断是不可靠的,使用Etag值可以更加精确控制缓存,所以引入服务器自动生成Etag校验码作为唯一标识符,如果资源频繁改动会重新生成Etag值,但是如果资源只是频繁的刷新修改日期,则Etag不变。
在默认的情况下这两个值可以一起使用,但是牢记优先校验ETag(原因请看上面的栗子)。
用户行为对缓存影响
这里直接用了网上的一张图,主要记住几个无效的项即可。
下面是日常用户操作
- 大部分网站打开网页通常优先检查disk cache,有就使用,没有就发送请求。
- F5刷新,因为此时TAB没有关闭,使用memory cache 是可用的,会被优先使用,而disk cache 会被滞后使用。
- 强制刷新 (Ctrl + F5):浏览器不使用缓存,因此发送的请求头部均带有
Cache-control: no-cache(为了兼容,还带了Pragma: no-cache),此时返回200状态码和最新内容。

缓存策略建议
因为缓存是作用于文件的,而文件资源基本情况有两种:频繁改动的资源和长久不变化的资源。
频繁变动的资源:
- 首先需要使用
Cache-Control: no-cache使浏览器每次都请求服务。 - 配合
ETag或者Last-Modified来验证资源是否有效。
这样的处理方法可以显著的减少响应内容的大小。
长久不变的资源:
直接给一个Max-age=31536000 一年的时间让浏览器强制使用缓存,所以通常建议在文件名中加入哈希码和版本号等信息,防止长久缓存文件突然需要更新的时候能及时反馈给客户端。
参考文章
一张图理解Http缓存 - SegmentFault 思否
RFC7234 中文翻译 中文RFC RFC文档 RFC翻译 RFC中文版 (rfc2cn.com)
【第1398期】一文读懂前端缓存 (qq.com)
Prevent unnecessary network requests with the HTTP Cache (web.dev)
# 深入理解浏览器的缓存机制