【Java 】Java collection of high-frequency interview questions
Source
java - Java collection of high-frequency interview questions_个人文章 - SegmentFault 思否
This article catalog
- What are the common collections?
- The difference between List, Set and Map
- Do you understand ArrayList?
- What is the expansion mechanism of ArrayList?
- How to remove an element while traversing the ArrayList?
- The difference between Arraylist and Vector
- The difference between Arraylist and LinkedList
- HashMap
- What are the ways to resolve hash conflicts? What kind of HashMap is used?
- The hash algorithm used?
- Expansion process?
- Put method flow?
- The characteristics of red-black trees?
- Why use red-black trees instead of AVL trees?
- When resolving hash conflicts, why choose to use the linked list first, and then switch to the red-black tree?
- Why is the length of HashMap a power of 2?
- What is the default load factor of HashMap? Why is it 0.75?
- What is generally used as the key of HashMap?
- Why is HashMap thread unsafe?
- The difference between HashMap and HashTable?
- The underlying principle of LinkedHashMap?
- Tell me about TreeMap?
- The underlying principle of HashSet?
- What is the difference between HashSet, LinkedHashSet and TreeSet?
- What is fail fast?
- What is fail safe?
- Tell me about ArrayDeque?
- Which collection classes are thread safe? What is unsafe?
- What is Iterator?
- What is the difference between Iterator and ListIterator?
- Concurrent container
- ConcurrentHashMap
- Put execution flow?
- How to expand?
- The difference between ConcurrentHashMap and Hashtable?
- CopyOnWrite
- ConcurrentLinkedQueue
- Blocking queue
- Blocking queue provided by JDK
- principle
- ConcurrentHashMap
What are the common collections?
The Java collection class is mainly derived from two interfaces Collection and Map . Collection has three sub-interfaces: List, Set, and Queue.
List:List represents an ordered and repeatable collection, which can be accessed directly according to the index of the element;
Set:Set represents an unordered and non-repeatable collection, which can only be accessed according to the element itself
Image source【集合系列】- 初探 java 集合框架图 | Just Do Java


The difference between List, Set and Map
- List accesses elements by index, in order, elements are allowed to be repeated, and multiple nulls can be inserted;
- Set cannot store repeated elements, unordered, only one null is allowed;
- Map saves the key-value pair mapping;
- The bottom layer of List has two implementations: array and linked list; Set and Map containers have two implementations, based on hash storage and red-black tree.
- Set is implemented based on Map, and the element value in Set is the key value of Map.
Do you understand ArrayList?
ArrayList is a dynamic array, and its capacity can grow dynamically. Before adding a large number of elements, the application can use the ensureCapacity operation to increase the capacity of the ArrayList ArrayList inherits AbstractList and implements the List interface.
What is the expansion mechanism of ArrayList?
By default, the new capacity will be 1.5 times the original capacity. Take JDK1.8 as an example:
1 | public boolean add(E e) { |
The essence of ArrayList expansion is to calculate the size of the new expanded array and instantiate it, and copy the contents of the original array to the new array.
How to remove an element while traversing the ArrayList?
Foreach delete will cause fast failure problem, you can use the remove() method of the iterator.
1 | Iterator itr = list.iterator(); |
The difference between Arraylist and Vector
- When the memory is insufficient, ArrayList is expanded by 50% + 1 by default, and Vector is expanded by 1 times by default.
- Vector belongs to the thread-safe level, but in most cases, Vector is not used because it is relatively inefficient to operate on Vector.
The difference between Arraylist and LinkedList
- ArrayList is implemented based on a dynamic array; LinkedList is implemented based on a linked list.
- For the get and set methods of random index access, ArrayList is faster than LinkedList. Because ArrayList finds elements directly through the array subscript; LinkedList moves the pointer to traverse each element until it finds it.
- Adding and deleting elements, LinkedList is faster than ArrayList. Because ArrayList may expand and copy the array when adding and deleting elements; LinkedList needs time to instantiate objects, and only needs to modify the pointer.
HashMap
HashMap is implemented using array + linked list + red-black tree (JDK1.8 adds the red-black tree part). When the length of the linked list is greater than 8 (TREEIFY_THRESHOLD)(阈值), the linked list will be converted to a red-black tree, and the number of red-black tree nodes is less than 6 ( UNTREEIFY_THRESHOLD) is converted to a linked list to prevent frequent conversion.
What are the ways to resolve hash conflicts? What kind of HashMap is used?
Methods to resolve Hash conflicts include: open addressing, rehashing, and chain addressing. The chain address method is used in HashMap.
- The basic idea of open addressing method is that if
p=H(key)event of a conflict(冲突), placespbasis, hash again,p1=H(p), if p1 conflict again, places p1-based, and so on, until you find a hash address that does not conflictpi. Therefore, the length of the hash table required by the open addressing method must be greater than or equal to the elements that need to be stored, and because there is another hash, can only mark the deleted node, but cannot actually delete the node. - And then hashing a plurality(多个) of different hash function, when
R1=H1(key1)conflict occurs, then calculateR2=H2(key1), until there is no conflict. Although this is not easy to produce a pile, but it increases(增加) the calculation time. - The chain address method composes a singly linked list of synonyms with the same hash value, and stores the head pointer of the singly linked list in the i-th unit of the hash table. The search, insertion and deletion are mainly performed in the synonym linked list. The linked list method is suitable for frequent insertions and deletions.
The hash algorithm used?
Hash algorithm: take the hashCode value of the key, high-order operation, and modulo operation.
1 | h=key.hashCode() //Step 1. Get the hashCode value |
In the implementation of JDK1.8, the algorithm for high-order operations is optimized, which is implemented by the high-order 16-bit XOR of hashCode(): this can be done when the array is relatively small, and it can also ensure that both high and low bits are taken into account. In the calculation of Hash, conflicts can be reduced without too much overhead.
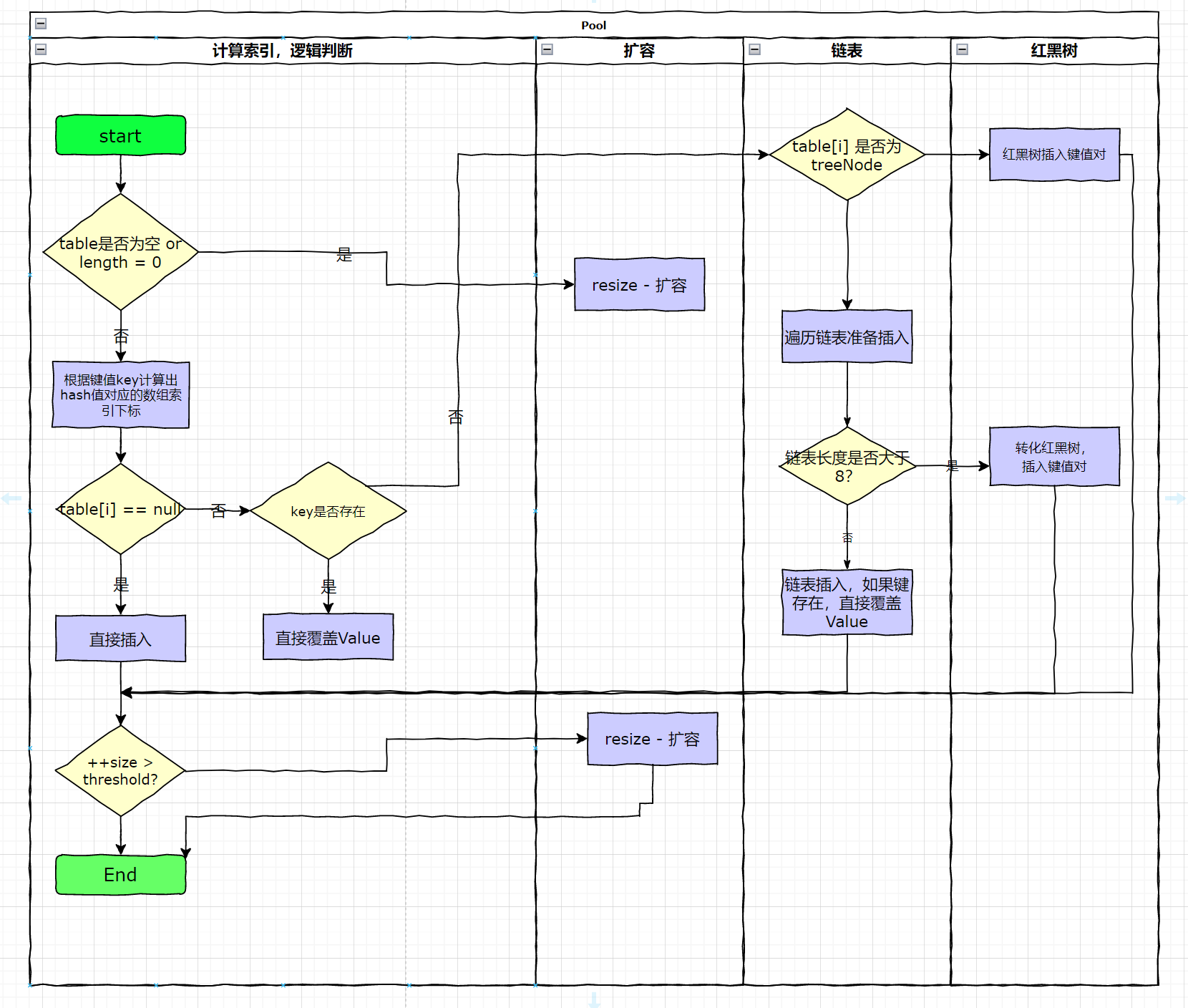
Put method process?
If the table is not initialized, the initialization process is performed firstUse the hash algorithm to calculate the index of the keyDetermine whether there is an element at the index, and insert it directly if notIf there is an element at the index, then traverse the insertion. There are two cases. One is the linked list form and the insertion is directly traversed to the end, and the other is the red-black tree and inserts according to the red-black tree structure.If the number of linked lists is greater than the threshold 8, it must be converted into a red-black tree structureAfter the addition is successful, it will check whether it needs expansion
The characteristics of red-black trees?
- Each node is either black or red.
- The root node is black.
- Each leaf node (NIL) is black.
- If a node is red, its child nodes must be black.
- All paths from a node to the descendants of that node contain the same number of black nodes.
Why use red-black trees instead of AVL trees?
ConcurrentHashMap will be locked when put, using the red-black tree to insert faster, which can reduce the time waiting for the lock to be released. The red-black tree is an optimization of the AVL tree. It only requires partial balance. The non-strict balance is used to reduce the number of rotations when adding and deleting nodes, which improves the performance of insertion and deletion.
When resolving hash conflicts, why choose to use the linked list first, and then switch to the red-black tree?
Because red-black trees need to perform left-handed(左旋), right-handed, and color-changing operations to maintain balance, singly linked lists do not.
- When the number of elements is less than 8, the linked list structure can guarantee query performance.
- When there are more than 8 elements, the search time complexity of the red-black tree is O(logn), while the linked list is O(n). At this time, the red-black tree is needed to speed up the query, but the efficiency(效率) of inserting and deleting nodes becomes slower. .
- If the red-black tree structure is used at the beginning, there are too few elements, and the efficiency of inserting and deleting nodes is slow, and performance is wasted.
Why is the length of HashMap a power of 2?
The Hash value has a relatively(比较) large range value. Before using it, you need to perform a modulo(模数) operation on the length of the array, and the remainder obtained (获得)is the location where the element is stored, which is the corresponding array subscript. The calculation method for the subscript of this array is (n - 1) & hash .
Set the length of HashMap to the power of 2, so that you can use (n - 1)&hash bit operation instead of% remainder operation to improve performance.
What is the default load factor of HashMap? Why is it 0.75?
First look at the default constructor of HashMap:
1 | int threshold; // Accommodates the maximum value of the key-value pair |
The initial length of the Node[] table is 16, and the default loadFactor is 0.75. 0.75 is a balanced choice for space and time efficiency. According to the Poisson distribution, loadFactor 0.75 is the smallest collision(碰撞). Generally, it will not be modified, except under special circumstances(情况) in time and space:
- If there is a lot of memory space and time efficiency is very high, you can reduce the value of Load factor(负载因子).
- If the memory space is tight and the time efficiency is not high, you can increase the value of the load factor, which can be greater than 1.
- In most cases it is recommended to set the initialization size as much as possible.
What is generally used as the key of HashMap?
Generally, immutable classes such as Integer and String are used as HashMap as the key. The String class is more commonly(通常) used.
- Because String is immutable, the hashcode is cached when it is created and does not need to be recalculated(重新计算) This is why the keys in HashMap often use strings.
- The equals() and hashCode() methods are used when obtaining objects, and the Integer and String classes have already rewritten the hashCode() and equals() methods, so you don’t need to rewrite these two methods yourself.
Why is HashMap thread unsafe?
Infinite loop of expansion under multi-threading. The HashMap in JDK1.7 uses the header insertion method to insert elements. In a multi-threaded environment, the circular linked list may appear when the capacity is expanded, forming an endless loop.
In JDK1.8, in a multithreaded environment, data will overwrite .
The difference between HashMap and HashTable?
- HashMap can accept null keys and values. Key-value pairs with null keys are placed in the linked list of the head node with subscript 0, while Hashtable cannot.
- HashMap is not thread-safe, HashTable is thread-safe. Jdk1.5 provides ConcurrentHashMap, which is a replacement for HashTable.
- Many methods of Hashtable are synchronous methods, which are slower than HashMap in a single-threaded environment.
- The use of hash value is different, HashTable directly uses the hashCode of the object. The HashMap recalculates the hash value.
The underlying principle of LinkedHashMap?
HashMap is unordered, and the order of the elements obtained by iterating the HashMap is not the order in which they were originally placed in the HashMap, that is, their insertion order cannot be maintained.
LinkedHashMap inherits from HashMap and is a fusion of HashMap and LinkedList, with the characteristics of both. Each put operation will insert the entry into the end of the doubly linked list.

Tell me about TreeMap?
TreeMap is a Map collection that can compare the size of elements, and sorts the incoming keys by size. You can use the natural order of the elements, or you can use a custom comparator in the collection to sort.
1 | public class TreeMap<K,V> |
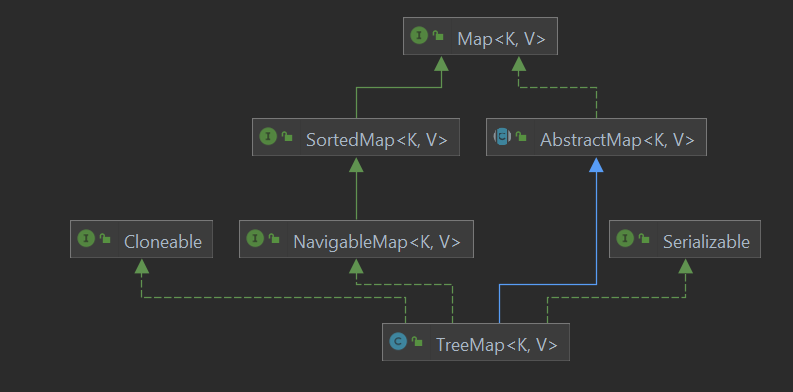
Inheritance structure of TreeMap:
TreeMap features:
TreeMap is an ordered set of key-values, implemented through red-black trees. Sort according to the natural order(自然排序) of the keys or according to the provided Comparator.
TreeMap inherits AbstractMap, implements the NavigableMap interface, and supports a series of navigation methods. Given a specific search target, it can return the closest match. For example, floorEntry() and ceilingEntry() return Map.Entry() objects that are less than or equal to or greater than or equal to a given key, respectively(各自的), and return null if they do not exist. lowerKey(), floorKey, ceilingKey, and higherKey() only return the associated key.
The underlying(根本) principle of HashSet?
HashSet is implemented based on HashMap. The elements put into the HashSet are actually stored by the key of the HashMap, and the value of the HashMap stores a static Object object.
1 | public class HashSet<E> |
What is the difference between HashSet, LinkedHashSet and TreeSet
HashSet is Set main interface implementation class, HashSet bottom is HashMap , thread-safe, a null value may be stored;
LinkedHashSet is HashSet , which can be traversed in the order of addition;
TreeSet uses a red-black tree at the bottom layer, which can be traversed in the order of adding elements, and the sorting method can be customized(自定义).
What is fail fast?
Fast-fail is an error mechanism of Java collections. When multiple threads operate on the same collection, fast-fail events may occur.
For example: when thread a is traversing the collection through iterator, another thread b modifies the content of the collection. At this time modCount (the number of modifications to the collection operation process) will increase by 1, which is not equal to expectedModCount, then when thread a accesses the collection, ConcurrentModificationException will be thrown.
For example2: Modifying the collection while traversing will also generate fast-fail events.
Solution:
Use the Colletions.synchronizedList method || add synchronized to the place where the content of the collection is modified.
Impact:block the traversal operation and affect performance(影响性能).
Use CopyOnWriteArrayList to replace ArrayList.
When the CopyOnWriteArrayList is modified, a new array is copied, the new array is operated, and the reference is moved to the new array after the operation is completed.
We can see the following code to confirm(Version JDK 1.8)
1 | public boolean add(E e) { |
What is fail safe?
The containers under the java.util.concurrent package are safe to fail, and can be used and modified concurrently in multiple threads.
Principle : Since the copy of the original collection is traversed during iteration, the modification of the original collection during the traversal process cannot be detected by the iterator, so Concurrent Modification Exception will not be triggered.
Disadvantages : The advantage(好处) of copying content is to avoid Concurrent Modification Exception, but similarly, the iterator cannot access the modified content, that is: the iterator traverses the copy of the collection obtained at the moment of traversal. During this period, the modification iterator of the original collection is not known.
Tell me about ArrayDeque?
ArrayDeque implements a double-ended queue(双端队列), using a circular array internally, and the default size is 16.
characteristics:
- more efficient to add and delete elements at both ends
- The efficiency of searching and deleting based on element(基于元素) content is relatively low.
- There is no concept(概念) of index position, and operations cannot be performed based on (基于)index position.
Both ArrayDeque and LinkedList implement the Deque interface. Both ArrayDeque and LinkedList are not thread-safe
We can be converted to thread synchronization using synchronizedXxx() in the Collections tool class.
For Example:java.util.Collections#synchronizedCollection(java.util.Collection<T>)
Hsow to choose them?
- If you only need to operate from both ends, ArrayDeque is more efficient.
- If you need to operate according to the index position at the same time, or often need to insert and delete in the middle , you should choose LinkedList
Which collection classes are thread safe? What is unsafe?
Thread safe collection class:
- Vector: It has more synchronization mechanism than ArrayList.
- Hashtable`
- ConcurrentHashMap: is an efficient and thread-safe collection.
- Stack: Stack is also thread-safe, inherited from Vector.
- ConcurrentHashMap
….(more java.util..current.*)
Thread unsafe collection class:`
- Hashmap
- Arraylist
- LinkedList
- HashSet
- TreeSet
- TreeMap
What is Iterator?
The Iterator pattern uses the same logic to iterate through collections. It can abstract the access logic from different types of collection classes.
With an iterator, you can traverse collection elements without knowing the internal implementation of the collection, using the interface provided by Iterator to unify traversal.
1 | public interface Collection<E> extends Iterable<E> { |
There are three main methods: hasNext(), next() and remove().
What is the difference between Iterator and ListIterator?
ListIterator is an enhanced(强化) version of Iterator.
- ListIterator traversal can be reversed, because there are previous() and hasPrevious() methods, but Iterator cannot.
- ListIterator has add() method, which can add objects to List, but Iterator cannot.
- ListIterator can locate(定位) the current index position because of the nextIndex() and previousIndex() methods, but Iterator cannot.
- ListIterator can realize the modification of the object, and the set() method can be realized. Iierator can only be traversed and cannot be modified.
- ListIterator can only be used to traverse List and its subclasses, and Iterator can be used to traverse all collections.
Concurrent container
Most of these containers provided by the JDK are in the java.util.concurrent package.
- ConcurrentHashMap:thread-safe HashMap
- CopyOnWriteArrayList: thread-safe List that performs(执行) very well in situations where more reads and less writes are performed, far better than Vector.
- ConcurrentLinkedQueue::efficient(高效) concurrent queue, implemented using a linked list. It can be seen as a thread-safe LinkedList, which is a non-blocking queue.
- BlockingQueue: blocking queue interface, which is implemented in the JDK through linked lists, arrays, etc(..等等). Very suitable for use as a data sharing channel.
- ConcurrentSkipListMap:The jump table. Use the data structure of the jump table for quick search.
ConcurrentHashMap
In a multi-threaded environment, using Hashmap for put operations will cause an endless loop, and ConcurrentHashMap that supports multi-threading should be used.
Why put operations will cause an endless?If you want to know the third case What mean is, I recommend the english article:
The Mailinator(tm) Blog: A Beautiful Race Condition
If you English is not so good, You also can see the article
疫苗:Java HashMap的死循环 | 酷 壳 - CoolShell
JDK1.8 ConcurrentHashMap cancels the segment lock, and uses CAS and synchronized to ensure concurrency safety.
The data structure adopts array + linked list/red-black binary tree. Synchronized only locks the first node of the current linked list or red-black binary tree.
Compared with JDK1.7 locking the HashEntry array, the lock granularity(颗粒度) is smaller and supports a higher amount of concurrency(并发性).
Put execution flow?
The segment needs to be locked during put to ensure concurrency safety.
The segment needs to be locked during put to ensure(确保) concurrency safety. When calling get, do not lock it because the node array member val and pointer next are modified with volatile and the modified values are immediately refreshed in main memory for visibility(可见), and the node array table is also modified with volatile to ensure that its running process is visible to other threads.
Here is the relevant code
1 | transient volatile Node<K,V>[] table; |
Put operation process:
- If the table is not initialized, the initialization process is performed first.
- Use the hash algorithm to calculate the location of the key.
- If this position is empty, CAS is inserted directly(直接), if it is not empty, then this node is taken out
- If the hash value of the retrieved node is MOVED(-1), it means that the array is currently being expanded and copied to the new array, and the current thread will also help copy
- If this node is not empty or expanding, it will be locked through synchronized to perform the addition operation. There are two cases here
- one is that the linked list is directly traversed to the end to insert or overwrite the same key,
- the other is If it is a red-black tree, insert it according to the red-black tree structure`
- If the number of linked lists is greater than the threshold 8, it will be converted into a red-black tree structure or expanded (table length is less than 64)
- After the addition is successful, it will check whether it needs expansion
Code:java.util.concurrent.ConcurrentHashMap#putVal
1 | Node<K,V> f; int n, i, fh; |
How to expand?
In the array expansion transfer method, a step size is set to indicate the length of the array processed by a thread, and the minimum value is 16. Only one thread will copy and move it in a step range.
The difference between ConcurrentHashMap and Hashtable?
Hashtable achieves(实现) multi-thread synchronization by using the synchronized modification method. Therefore, the synchronization of Hashtable will lock the entire array.
In the case of high concurrency, the performance will be very poor. ConcurrentHashMap uses more fine-grained locks to improve efficiency in concurrent situations(并发情况).
Note: Synchronized container (synchronized container) also achieves thread safety through the synchronized keyword, and locks all data when in use.
The default size of Hashtable is 11. When the threshold(阈值) is reached, the capacity is expanded according to the following formula(公式) each time: newCapacity = oldCapacity * 2 + 1. The default size of ConcurrentHashMap is 16, and the capacity is doubled when expanding.
CopyOnWrite
Copy-on-write. When we add elements to the container, we do not directly add to the container, but first copy the current container, copy out(导出) a new container, and then add elements to the new container, after adding the elements, then point the reference to the original container New container.
The advantage of this is that the CopyOnWrite container can be read concurrently without locking, because the current container will not be modified.
1 | public boolean add(E e) { |
Since JDK1.5, the Java Concurrency Package provides two concurrent containers implemented using the CopyOnWrite mechanism(机制). They are CopyOnWriteArrayList and CopyOnWriteArraySet.
When the add method in CopyOnWriteArrayList is added, it needs to be locked to ensure synchronization and avoid copying multiple copies when writing in multiple threads.
There is no need to lock when reading. If other threads are adding data to CopyOnWriteArrayList when reading, the old data can still be read.
这里有点像是模仿操作系统写时复制的理念。写操作在一份“虚拟空间”操作。
Disadvantages(缺点):
- Memory usage problem. Due to the copy-on-write mechanism of CopyOnWrite, the memory of two objects resides in the memory at the same time when the write operation is performed.
- The CopyOnWrite container cannot guarantee(保证) the real-time consistency of the data, and old data may be read.
ConcurrentLinkedQueue
Non-blocking queue. Efficient(高效) concurrent queues are implemented using linked lists. It can be seen as a thread-safe LinkedList, implemented through CAS operations.
If the cost of locking the queue is high, it is suitable(适合) to use a lock-free ConcurrentLinkedQueue instead. It is suitable for scenarios(场景) where the performance requirements are relatively high and there are multiple threads to read and write to the queue at the same time.
non-blocking queue
- add(E e): Insert element e to the end of the queue. If the insertion is successful, it returns true; if the insertion fails (ie, the queue is full), an exception will be thrown;
- remove(): Remove the element at the head of the queue. If the removal(移除) is successful, it will return true; if the removal fails (the queue is empty), an exception will be thrown;
- offer(E e): Insert the element e at the end of the queue, if the insertion is successful, it returns true; if the insertion fails (that is, the queue is full), it returns false;
- poll(): Remove and get the first element of the queue, if successful, return the first element of the team; otherwise, return null;
- peek(): Get the first element of the queue, if successful, return the first element of the queue; otherwise, return null;
For non-blocking queues, it is generally recommended(一般推荐) to use the three methods of offer, poll and peek, and it is not recommended to use the add and remove methods.
Because the three methods of offer, poll, and peek can be used to determine whether the operation is successful or not through the return value, but the use of add and remove methods cannot achieve this effect.
Blocking queue
The blocking queue is an important data structure under the java.util.concurrent package.
BlockingQueue provides a thread-safe queue access method: when the blocking queue is inserting data, if the queue is full, the thread will block and wait until the queue is not full; When the queue fetches data, there is no blocking. if the queue is empty, the thread will block and wait until the queue is not empty.
Many implementations of advanced(高级) synchronization classes under the Concurrency package are based on BlockingQueue, which is suitable for use as a data-sharing channel.
The difference between a blocking queue and a general queue is:
- (blocking queue)Multi-thread support, multiple threads can safely access the queue.
- Blocking operation. When the queue is empty, the consumer thread will block and wait for the queue to be not empty; when the queue is full, the production thread will block until the queue is not full.
| Method\Processing Method | Throw an exception | Return special value | Keeps blocking | Timeout exit |
|---|---|---|---|---|
| Insert method | add(e) | offer(e) | put(e) | offer(e,time,unit) |
| Removal method | remove() | poll() | take() | poll(time,unit) |
| Inspection Method | element() | peek() | unavailable | unavailable |
Blocking queue provided by JDK
JDK7 provides 7 blocking queues, as follows
ArrayBlockingQueue
Bounded blocking queue, the bottom layer is implemented by array. Once the ArrayBlockingQueue is created, the capacity cannot be changed. The concurrency control adopts(采用) reentrant(可重入) locks to control, whether it is an insert operation or a read operation, a lock must be acquired(获得) before the operation can be performed.
This queue sorts the elements according to the first-in-first-out (FIFO) principle.
By default, the fairness(公平性) of thread access to the queue is not guaranteed(保证). The parameter fair can be used to set whether the thread accesses the queue fairly. In order to ensure fairness, throughput is usually reduced.
1 | private static ArrayBlockingQueue<Integer> blockingQueue = new ArrayBlockingQueue<Integer>(10,true);//fair |
LinkedBlockingQueue
LinkedBlockingQueue is a bounded blocking queue implemented with a singly linked list, which can be used as an unbounded queue or a bounded queue.
Usually when creating a LinkedBlockingQueue object, the maximum capacity of the queue is specified. The default and maximum length of this queue is Integer.MAX_VALUE . This queue sorts the elements according to the first-in-first-out principle. Compared with ArrayBlockingQueue, it has higher throughput.
PriorityBlockingQueue
Support priority unbounded blocking queue. By default, the elements are arranged in ascending order(升序) in natural order.
You can also customize the class to implement the compareTo() method to specify the element sorting rules, or when you initialize the PriorityBlockingQueue, specify the construction parameter Comparator for sorting.
PriorityBlockingQueue can only specify the initial queue size. When inserting elements later, if there is not enough space, will automatically expand to.
A thread-safe version of PriorityQueue. No null value can be inserted. At the same time, the object inserted into the queue must be comparable in size (comparable), otherwise a ClassCastException will be reported. Its insert operation put method will not block, because it is an unbounded queue (the take method will block when the queue is empty).
DelayQueue
Unbounded blocking queue that supports delayed acquisition of elements. The queue is implemented using PriorityBlockingQueue. The elements in the queue must implement the Delayed interface. When creating the element, you can specify how long it takes to get the current element from the queue. Only when the delay expires can elements be extracted from the queue.
SynchronousQueue
In a blocking queue that does not store elements, each put must wait for a take operation, otherwise it cannot continue to add elements. Support fair access queue.
SynchronousQueue can be regarded(被视为) as a passer, responsible for passing the data processed by the producer thread directly to the consumer thread.
The queue itself does not store any elements, which is very suitable(适合) for transitive scenarios. The throughput of SynchronousQueue is higher than that of LinkedBlockingQueue and ArrayBlockingQueue.
LinkedTransferQueue
An unbounded(无界) blocking TransferQueue queue composed of(组成) a linked list structure. Compared with other blocking queues, there are more tryTransfer and transfer methods.
Transfer method: If there is currently a consumer waiting to receive an element (take or time-limited poll method), transfer can immediately transfer the element passed by the producer to the consumer.
If there is no consumer waiting to receive the element, put the element in the tail node of the queue, and wait until the element is consumed by the consumer before returning.
tryTransfer method: used to test whether the elements passed by the producer can be directly passed to the consumer. If no consumers are waiting, return false. The difference with the above method is that the method returns immediately regardless(不论如何) of whether the consumer receives it or not. The transfer method must wait until the consumer has consumed it before returning.
principle
JDK uses the notification mode(通知模式) to implement blocking queues. The so-called notification mode is that when the producer adds elements to the full queue, the producer will be blocked. When the consumer consumes(消費) the elements in a queue, the producer will be notified that the current queue is available.
ArrayBlockingQueue uses Condition to achieve:
1 | private final Condition notEmpty; |