【Activity】从零开始到掌握工作流开发业务代码
#Activity #工作流
目录
[Toc]
引言
本文算是自己从零边研究边实践捣鼓到业务上线后全方位补充的一个笔记,对于技术人员推荐直接从第七章技术选型开始阅读,前面的理论部分基本是个人搜集的一些网络资料和个人理解笔记,对于使用工作流实现功能没有任何影响。
再次强调,本文非常非常长,请读者按需观看。
一、工作流术语定义
1.1 基本定义
Georgakopoulos(乔治亚 * 科普洛斯) 给出的工作流定义是:工作流是将一组任务组织起来以完成某个经营过程,定义了任务的触发顺序和触发条件,每个任务可以由一个或多个软件系统完成, 也可以由一个或一组人完成,还可以由一个或多个人与软件系统协作完成。
工作流实现了一整套流程内部自动完成的技术,可以屏蔽掉一些繁琐流程的业务进行简化。如果你的业务中没有工作流技术应用,那么完全可以关闭本文然后去刷刷视频干点别的。
1.2 相关术语
下面工作流程的术语定义。
| 术语 | 含义 | 不恰当比喻 |
|---|---|---|
| 工作流 | 工作从开始到完成的过程。包含流程逻辑和路线规则,流程逻辑包含任务的执行顺序,路线规则代表任务执行过程中必须遵守的路线, | 一项工作或者任务整体过程 |
| 流程定义 | 图形的流程定义。代表工作流的流程逻辑元素和它们元素关系。 | 类似快递的传输路线 |
| 流程实例 | 也叫工作。流程定义的运行实例。 | 类似正在运行的汽车 |
| 工作流系统 | 存储流程定义,通过工作流引擎组件驱动流程定义进行工作。 | 类似汽车发动机 |
| 流程定义工具 | 创建和更改流程定义的工具。可以是一个软件的组件,也可以是独立的应用程序。流程定义的工具具备复用性。 | 绘制汽车设计图的工具或者软件,可以修改产品设计 |
| 参与者 | 参与者可以是抽象或者具体的,比如资源集、特定资源、组织单元、角色(一个人在组织内部的作用)、人或系统(自动代理)。 | 路线上每一个节点的行为 |
| 活动 | 组成流程定义中的一个逻辑步骤的任务。可以是自动的或人工的。常见的自动活动就是截止期限管理,如果到期未完成就自动发送提醒消息。手动则是需要人力驱动系统执行业务规则,比如我们日常生活的报销申请审批。 | 描述某一项任务的处理细节 |
| 活动所有者 | 有权宣布活动结束或者把工作流程推动到下一个活动参与者 | 快递运输过程中的每一个站点如何处理快递 |
| 工作所有者 | 有权参与实例执行过程的参与者。 | 类似会议的参与人员,有权参加但是不一定有执行权 |
| 工作项 | 流程实例中活动的参与者将要执行的工作 | 比如送货的最后一步需要快递员派送快递到用户手里 |
1.3 为什么被叫做流?
各个节点通过内外部驱动触发引起节点的推进,形成一个流式的状态达到业务终点。比如一次用户查看淘宝商品的费用、一次支付成功后的权益开通、一次用户注册、一次调度任务的运行等,都是可以是一个工作流。
1.4 通俗理解
通俗理解:工作流 抽取了流程(例如:请假、报销、岗位调整等流程)运转过程的共性,将业务处理和流程流转剥离,减少编码过程中的重复性(审批、驳回、转办、挂起、中止等管理工作)操作,并且实现流程流转去纸质化和可视化的技术。
1.5 生命周期
一个完整的工作流生命周期主要有5步:
1、定义:即流程的定义,所有的流程总是从定义开始。主要任务是收集需求并将其转化为流程定义。
2、发布:开发人员将资源打包后在系统平台中发布流程定义,主要任务流程定义文件/自定义表单/任务监听类等。
3、执行:具体的流程引擎按照上面定义的流程处理路线来执行业务。
4、监控:收集每个任务的结果,将根据不同结果来做处理。
5、优化:此时业务流程已经完成,需要的就是优化流程或重新设计等。
二、为什么需要工作流
2.1 工作流管理系统优势
1、快速、高效、稳定的流程引擎,引擎支持大并发访问。
2、兼具人工和自动流程,具有明显的“中国流程”特色的柔性。
3、灵活的部署方式,支持集中部署、分布式部署。
4、高效的流程集成、整合框架;同时支持流程开发。
5、国内数十个行业,拥有近千个成功的客户案例。
2.2 业务可视化
举个例子,退款本身非常复杂,运营、产品、技术、财务可能都无法从单一的角色来解释清楚到底退款的整个链路和关键环节,但是通过工作流的方式来呈现,则所有人能快速看到退款到底是个什么样的业务。
通过流程图,我们可以清晰的看到节点之间的变化。
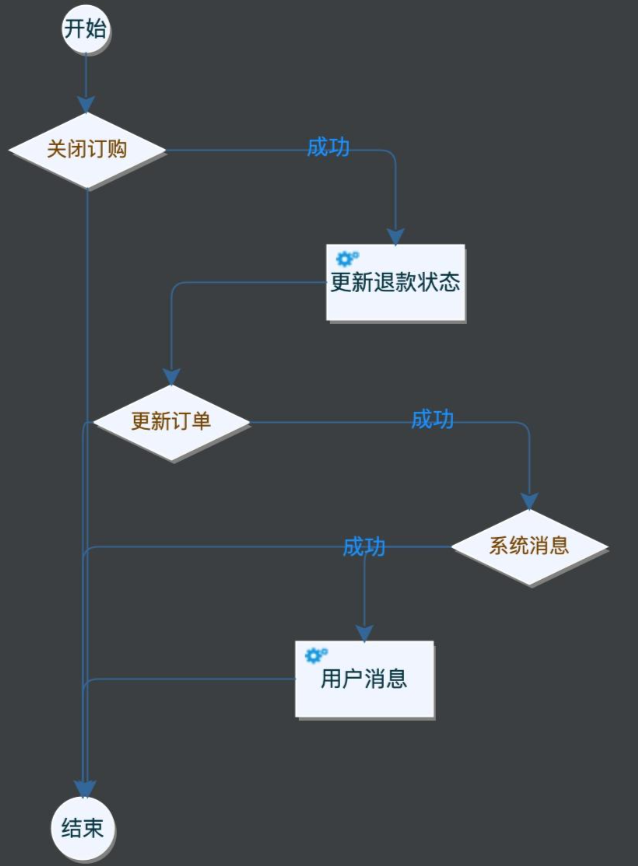
2.3 业务可编排
业务流程的编排在实际的运作过程中可能随时变化,工作流流程具备编排性,可以通过节点快速变化业务流程,可以灵活的增减节点,并且不会对于整个流程产生影响。
另一方面代码的可编排意味着代码复用性可以显著提高,比如上面的增加一个【关闭用户权益】的节点,或者删除【用户消息】,我们只需要修改流程而不需要调整业务代码。
2.4 自动重试
部分工作流支持持久化和自动重试能力。比如有时候需要在流程里面动态增删节点,但是动态增删节点可能会出现失败的情况,出现这种问题的时候可以通过部分节点重试解决问题。
三、常见开源工作流的对比(国外报告)
数据来源:Java Workflow Engines Comparison
| Feature | Workflow Server | Activiti | jBPM | Camunda | Copper |
|---|---|---|---|---|---|
| Workflow types(工作流类型) | State machine | State machine | State machine | State machine | State machine |
| Supported databases(支持数据库) | MS SQL Server, PostgreSQL, Oracle, MySQL, MongoDB | MS SQL, PostgreSQL, Oracle, MySQL, H2, DB2 | db2, derby, h2, hsqldb, mysql, oracle, postgresql, sqlserver | MS SQL, PostgreSQL, Oracle, MySQL, H2, DB2, MariaDB | PostgreSQL, Oracle, MySQL, H2, Apache Cassandra |
| Long-running operations(是否支持长期运作) | Yes | Yes | Yes | Yes | Yes |
| State persistence(状态持久化) | Serialization type is defined by Persistence Provider. You can easily control and change the settings saving process. | Activiti supports recovery in case of error, and will restart as a transactional state machine at the lowest level. | The runtime state of an executing process can be made persistent, for example, in a database. This allows to restore execution states of all running processes in case of unexpected failure. | Persistence Strategy based on the following concepts - Compact Tables, Deadlock Avoidance, Control Savepoints, Intelligent Caching, True Concurrency. | Not declared |
| Versioning & upgrading(版本管理和升级) | The processes that were created before the schema change, work under the old scheme, whereas the scheme of the specific process is updated after calling the appropriate command. | Versioning only | Both | With the use of additional converters | Yes, you can dynamically modify workflows at runtime. As soon as you save the changed code, Copper compiles it automatically and loads it. |
| Scheme format(底层存储格式) | The proprietary format based on XML. Import and export to BPMN2 starting with version 2.1. | BPMN2 | BPMN2 | BPMN2 | Process scheme is declared as Java-code |
| Installing the process in an arbitrary state(是否支持任意状态兼容工作流) | Yes, by calling a single method | Yes | Yes | Yes | Yes |
| Obtaining a list of available states for the current process(是否支持获得当前进程的可用状态列表) | Yes, by calling a single method | Yes, by calling a single method | No | No | Unknown |
| Built-in authorization of access to external actions (commands) for the workflow(是否允许外部访问内部流程) | Yes | No | No | No | No |
| Timers and delays(是否支持计时和延迟) | Yes | Yes | Yes | Yes | Yes |
| Obtaining a list of available external actions for the current process(获得当前进程的可用外部行动的列表) | Yes, by calling a single method | No | No | No | No |
| Simulated process execution(是否支持流程单元测试) | Yes, this mode is called Pre-Execution. | No | No | No | No |
| Modifying schemes at runtime(是否支持在运行时改变流程) | Yes, built in. | No | No | No | Yes |
| Obtaining process lists for Inbox and Outbox folders(获取收件箱和发件箱文件夹的进程列表) | Yes | No | No | No | No |
四、工作流使用场景
4.1 领域业务高复杂度
比如进销存、CRM、订单管理等具备一定的领域复杂度的业务,可以用工作流模式,来实现业务的可视化。
4.2 多节点、长链路
比如业务流转的过程要经过多个人,但是每个节点都需要独立,这种就比较适合无状态的内存工作流。
多节点比如一个审批任务需要同时转交给多个人审批并且同时通过才能进行下一步,长链路则是遇到审批过程需要多于5层以上的时候非常方便。
4.3 状态持久化和自动重试
例如订单支付成功后,驱动下游业务系统开通、发送用户提醒消息、扣减库存等异步流程节点,需要持久化每个节点的执行状态。
五、工作流分类
那么工作流该如何分类,如何抽象和归类自身的业务?
我们可以把工作流大致分类为:内存工作流、状态机工作流、人工工作流。
5.1 内存工作流
内存工作流是最简单的工作流,不需要持久化并且没有状态,类似代码的业务逻辑流转,因为所有的逻辑都是内存完成,业务本身是无状态的,所以不需要持久化。
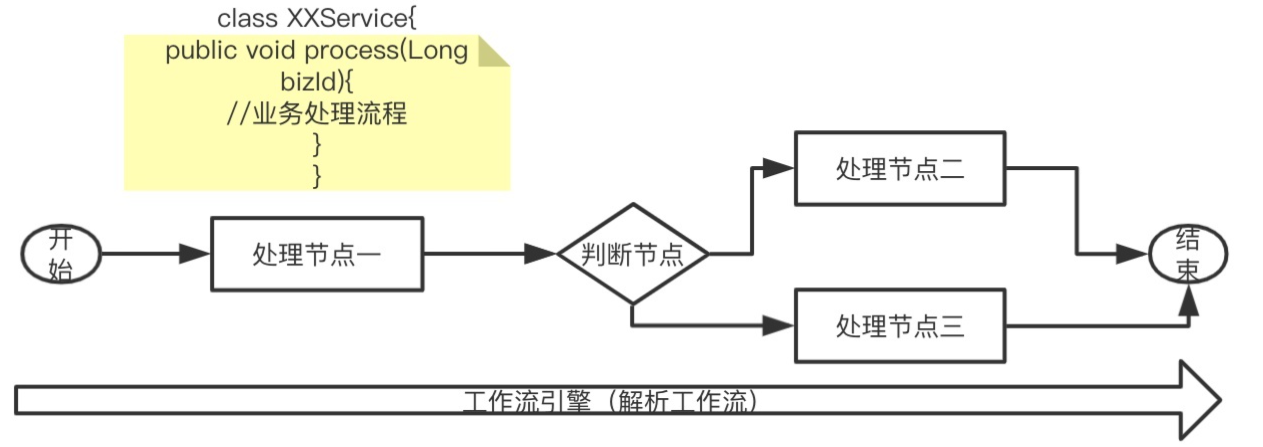
内存工作流也可以用业务编码完成,可以使得业务可视化,视图可以看出整个业务是如何流转的,业务工作流使的每个节点能够最大程度的复用。
5.2 状态机工作流
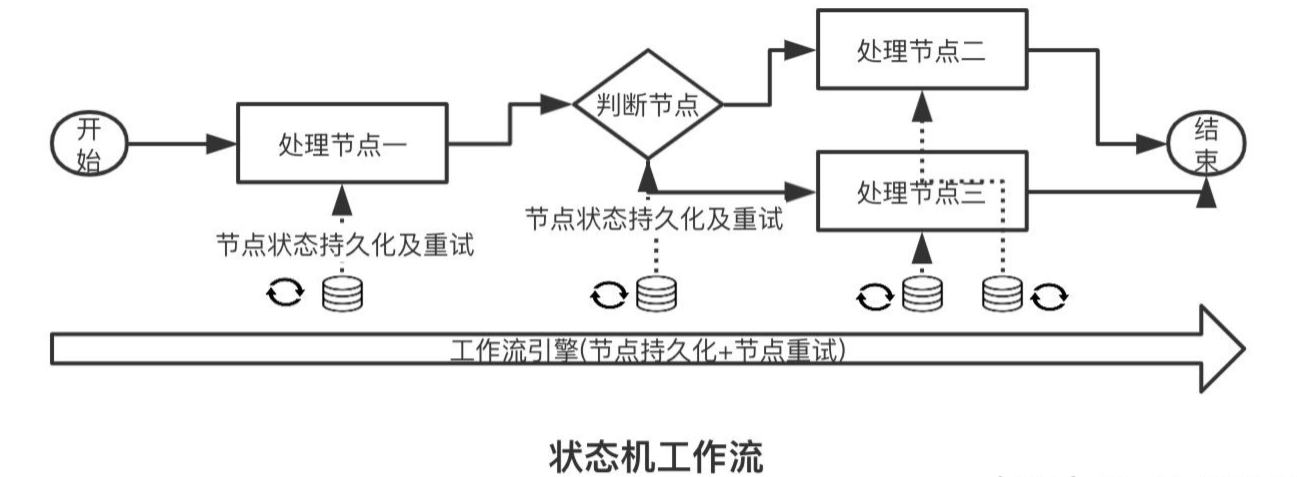
当需要自动重试节点操作的时候需要用到状态机,状态机可以看作是内存工作流的升级。一般的工作流引擎提供了默认集成的调度框架可以低成本的实现自动调度。
当某个节点处理失败后,节点置为异常状态,工作流调度模块会拉取失败的节点,继续按照工作流预定义的流程重试, 直到重试到指定的配置次数后,将整个流程置为执行失败,此时需要人工介入。
5.3 人工工作流
人工工作流使用场景最为广泛和频繁也最贴合实际生活。人工工作流也叫做外部触发驱动工作流,至少是存在一个或者多个节点是待外部确认才能推进整体业务流程。
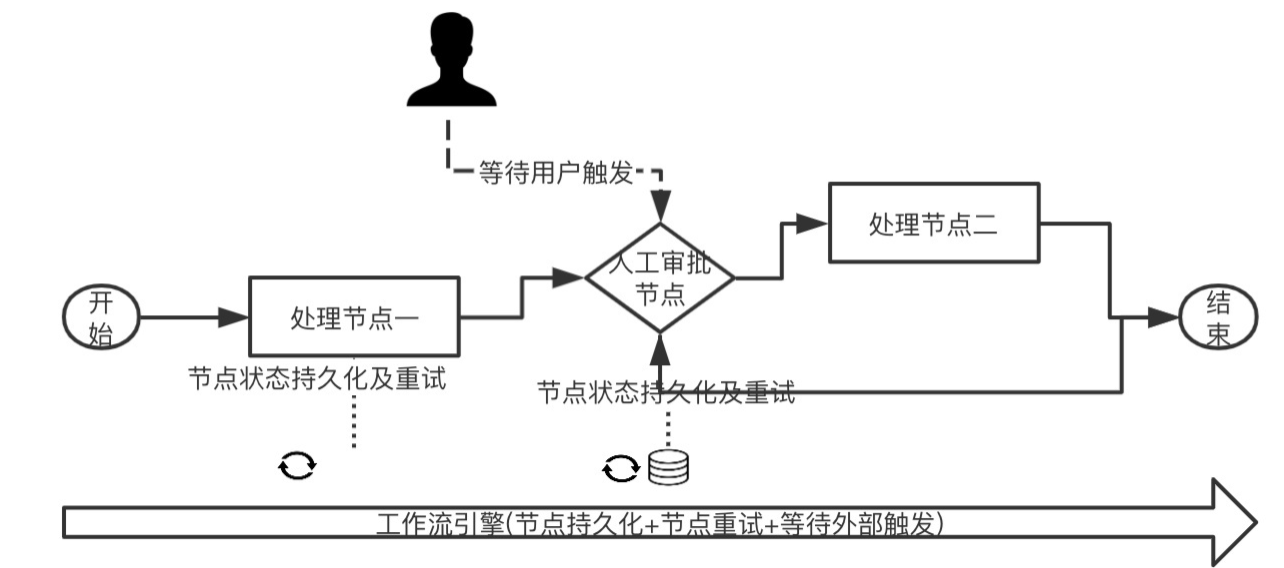
人工工作流最大特点是状态流转的手动触发机制,这种拦截触发到下一流程的机制可以适用于大部分业务。比如业务流程依赖审批的,比如退款流程,需要负责人审批通过后才能进行打款。
因为人工工作流需要手动触发才能进行下一步的流转,设计会稍微复杂一些,分了多个表。
- bpm_workflow_instance : 工作流实例表,表示一个具体执行的业务流;
- bpm_task_instance : 任务实例,将工作流的每个节点当做一个任务实例存储下来,描述一个工作流实例里 每个节点的具体状态;
- bpm_param_instance : 参数实例,工作流或者任务实例的上下文入参快照;
- bpm_timer_task:处理定时任务表,比如人工节点未审批自动超期等 bpm_sequence :生成上述四个表的主键ID表;
六、工作流设计准则
6.1 工作流设计准则
6.1.1 角色
- 发起人:发起人是一个流程的主要关系者,是最关心审批进展的人,发起人完成的主要是事务性、操作性的工作。从发起人的角度来说,在创建完审批事项后,还需要完善相关信息、催促审批人及时处理、跟进驳回修改意见、重新提交。
- 审批人:审批人需要完成流程中的决策性工作,因此在审批人的视角,内容和操作都应该尽量精简:只展现出最重要的信息,避免过多信息影响判断,只进行必要操作,不能有过多选择或操作,且需要保留审批历史,以便追溯。
6.1.2 内容:提炼最小集合
内容设计要点在于尽可能精炼内容,要注意保留必要内容,但凡是系统可自动获取的数据,就尽量避免发起人手动输入预置的常用内容,用选择的方式替代输入的,同时也能提高内容规范性。
6.1.3 根据业务设计流程
- 自主选定审批人流程:这是一种比较轻量、灵活的审批流程形式,适用没有标准化工作流程的业务场景。当流程发起人发起审批事项时,需要自动选择下一个环节的审批人,而下一个环节的审批人审批通过后,可以选择继续流转到再下一人,也可结束这个流程。
- 串行流程:只有当每个环节的审批人通过流程后,才会进入到下一环节。每个环节的驳回,可以根据业务需要,设计成驳回到发起人、驳回到上一环节或回到指定环节重新审批,或兼而有之,作为选项供审批人选择。
- 并行流程:并行流程是审批环节需要多人(角色)审批同意才算通过。任意一人审批通过即进入下一环节 & 必须所有人审批通过才进入下一环节。
- 条件触发流程:例如金额低于 1 万元由财务总监审批通过后即结束,金额在 1 万元以上则由副总裁审批通过后即结束。
- 混合流程:以上述金额审批为例,若金额低于 1 万元,由财务审批通过后即结束;金额在 1 万元到 10 万元的,需要先由财务审批,之后交由副总裁审批通过后即结束;金额高于 10 万元的,需要由董事长和总裁一同审批通过后才结束。
6.1.4 审批动作确定
- 通过。通过原因是否必填需要根据业务实际情况决定,通过之后流程会继续流转到下一个节点。
- 驳回修改。驳回原因一般需要设定成必填项,否则发起人或前一审批环节的参与者将无法获取被驳回的理由、和修改建议。驳回可以设计为三种:驳回到发起人 & 驳回上一环节 & 驳回到选定的之前的某个审批环节。
- 重新提交。通常审批人审批重新提交的内容时,需要附带上一次驳回的原因。
- 取消。可选操作,一般由发起人而不是审批人取消,原因是审批人只关心是否通过还是驳回,取消和驳回容易混淆。
6.1.5 权限
权限体系的设计是一个大工程,在审批流程中,采用基于角色的访问控制体系(RBAC)是一个不错的选择。基于角色的访问控制体系,包括用户、角色、目标、操作、许可权五个基本数据元素,具体内容分为可区分为功能权限和数据权限。
这里不过多扩展权限设计,在工作流设计中权限主要关注什么人可以发起审批,功能权限在拥有对应权限的角色可见,数据权限则通常是发起人和审批人共同可见。
6.1.6 配置和扩展性
一般针对企业开发后台系统的灵活性相对较少,而面向多个企业的商业化的系统则灵活性要求高。配置和扩展性通常和业务复杂程度成正比。
配置的灵活性体现在以下方面:
- 审批流程的类型
- 可修改具体的审批环节
- 可增删改的各个环节审批人/角色
- 可配置的审批相关的权限。
6.1.7 效率
工作流的核心目标是提高企业和组织的运行效率,如果线上审批流程效率还不如原来的纸质操作,那这个流程的设计就是失败的,也失去了意义。所以利用工作流提升审批流程效率,要注意尽可能精简审批的操作,做好流程操作的引导。
6.2 流程编排
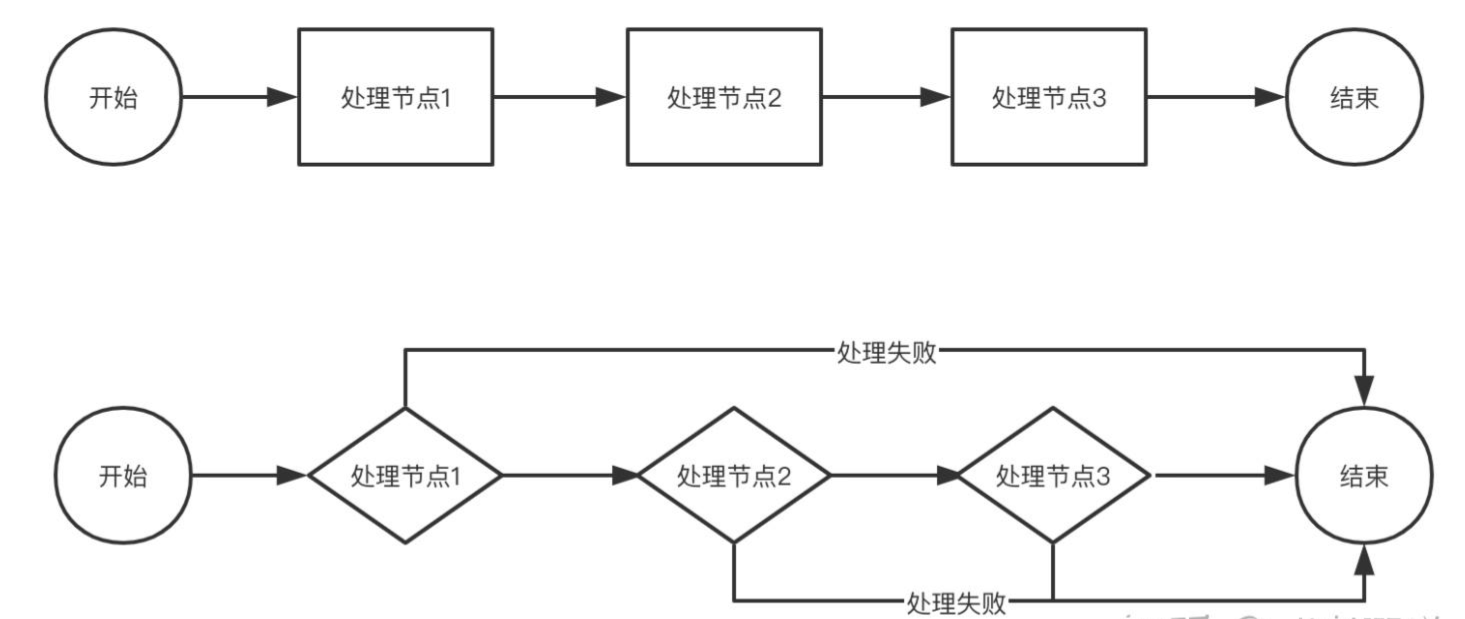
流程编码涉及到各个节点的跳转细节。
流程编排的时候需要考虑那些部分需要判断,哪些地方需要进行分支,需要注意失败节点的处理非常重要,同时也要考虑工作流无法往下进行的问题等。
6.3 异常处理
一般的工作流引擎工具中就设计了对异常的统一处理方式,下面的代码在也可以参考在日常开发过程中使用。
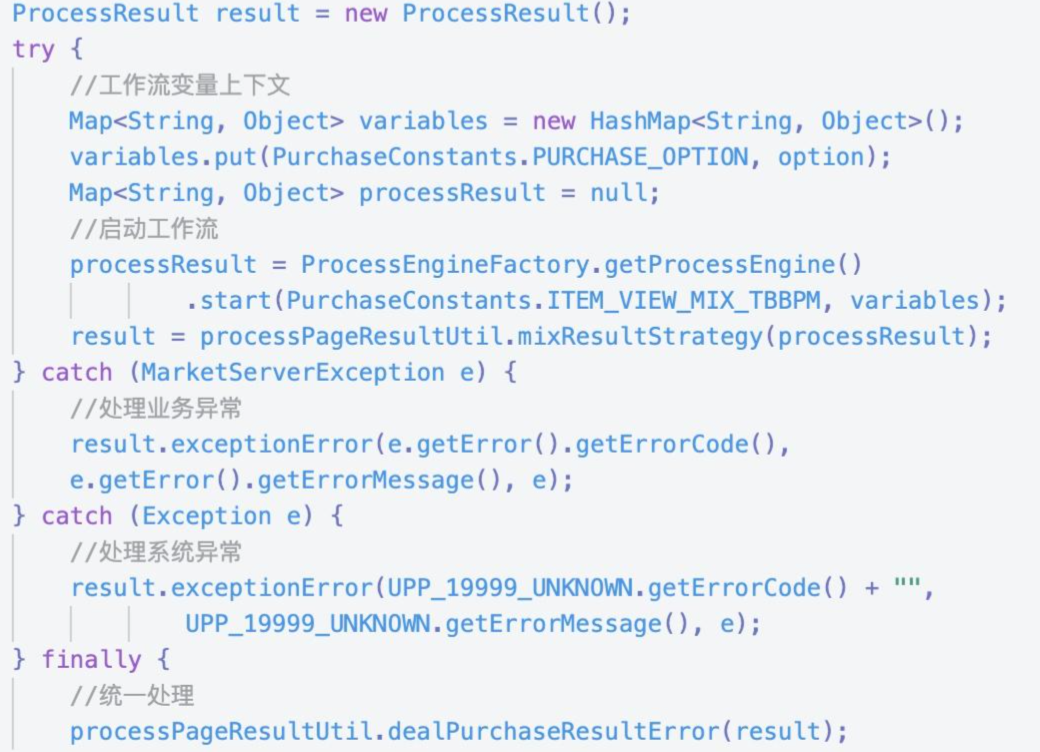
以上代码可以看出,工作流基本不处理异常,而是把异常收集到上层应用层进行统一处理。统一处理异常的优点是可以统一工作流节点错误处理方式,还可以打印错误提醒日志,方便快速定位工作流运行期间产生的异常问题。
6.4 工作流问题
- 常用的bmpn格式就存在较多的问题,底层格式为难懂的XML元素。
- 图形拖拽不美观、上下文变量设置麻烦、容易出异常未知问题。
- 始终没有一个非常极致体验的工作流引擎。
- 引入工作流本身会增加工程难度。
- 增加学习和使用成本。
6.5 不适用场景
- 简单的业务逻辑,几段代码搞定的,也无需考虑使用工作流。
- 比较简单的流程定义。
- 业务比较固定的场景。
6.6 工作流业务特点
特点 :
图形化、可视化设计流程图 。
支持各种复杂流程 。
组织结构级处理者指定功能 。
B/S结构,纯浏览器应用 。
强大的安全性特色 。
表单功能强大,扩展便捷 。
灵活的外出、超时管理策略 。
处理过程可跟踪、管理 。
丰富的统计、查询、报表功能 。
与MAIL系统集成。
6.7 工作流思想
只要采用流程模板+实例化思想都可以认为是工作流。
七、工作流技术选型
工作流如果是从零设计非常复杂,这里主要介绍介绍市面上常见的工作流引擎,市面上比较主流的工作流引擎为osworkflow、jbpm、activiti、flowable、camunda……
其中Jbpm4、Activiti、Flowable、camunda 四个框架同宗同源,祖先都是Jbpm4,开发者只要用过其中一个框架,基本上就会用其它三个。
7.1 Osworkflow
Osworkflow是一个轻量化的流程引擎,基于状态机机制,数据库表很少,Osworkflow提供的工作流构成元素有:步骤(step)、条件(conditions)、循环(loops)、分支(spilts)、合并(joins)等,但不支持会签、跳转、退回、加签等这些操作,需要自己扩展开发,有一定难度,如果流程比较简单,osworkflow是不错的选择。
文档地址:https://docs.huihoo.com/osworkflow/osworkflow-developer-guide.pdf

概括:轻量化流程引擎,基于状态机的机制进行工作,因为轻量级所以数据库内容比较少,比较适合简单的业务。
Osworkflow提供的工作流构成元素
- 步骤(step)
- 条件(conditions)
- 循环(loops)
- 分支(spilts)
- 合并
不支持的操作
- 回签
- 跳转
- 退回
- 加签
特点:因为轻量化,所以有些功能需要自己开发,针对一些简单流程的快速开发是比较好的选择。
7.2 JBPM
官网:jBPM - Open Source Business Automation Toolkit - jBPM Business Automation Toolkit
JBPM也是老牌软件,由JBoss公司开发,目前最高版本JPBM7,需要注意从JBPM5 开始就已经和前面的版本断层了(5开始基于Drools Flow,也叫做规则引擎),而大部分网络资料都是基于JBPM 4的,所以强烈不建议选择jBPM5以后版本,也不推荐用JBPM,比较容易踩坑。
JBPM 的规则引擎引入不仅没有降低工作流的理解和使用成本,反而导致结构设计混乱并且臃肿不堪。
7.3 Activiti
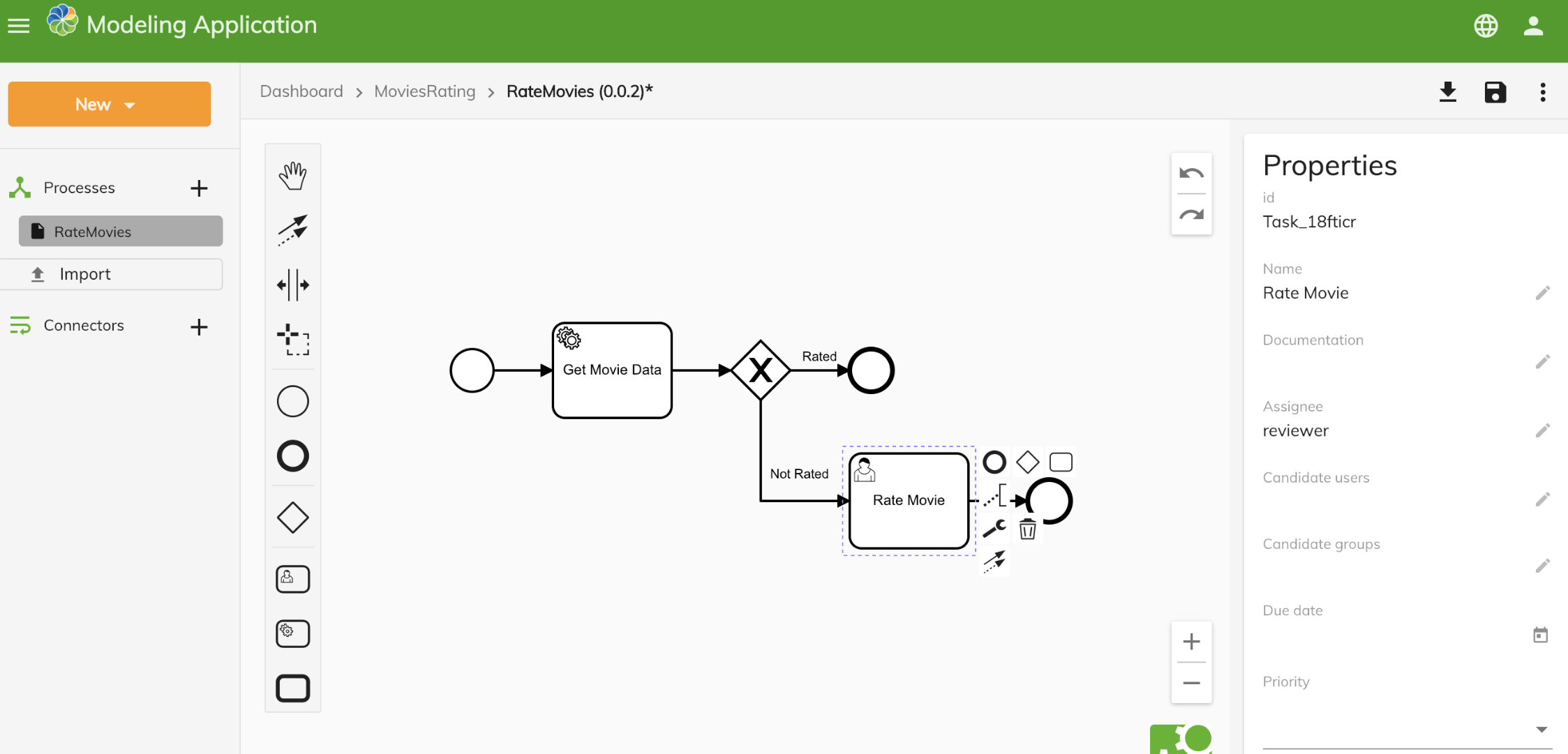
Activiti 是自带Spring官方集成支持的工作流引擎,如果是SpringBoot开发可以作为备选方案。
需要注意Activity的背景比较复杂,最高版本activiti 7,此外版本选择上比较复杂,有activiti5、activiti6、activiti7几个主流版本,需要谨慎考量。
我们借着Activity扩展下相关历史。
activiti5 和 activiti6 的核心leader是Tijs Rademakers(蒂亚斯-拉德梅克),由于团队内部分歧,在2017年时 Tijs Rademakers离开团队,创建了后来的 flowable, activiti6 以及activiti5 代码已经交接给了 Salaboy 团队, activiti6 以及 activiti5 的代码官方已经暂停维护了, 目前主流版本为Activiti7,但是activiti7内核使用的还是activiti6,并没有为引擎注入更多的新特性,更多是对于云服务的一系列支持。
根据上面所述,我们得知Activiti 有三个版本:activiti5、activiti6、activiti7。默认建议选择 Activiti7 的版本,Activiti 的独立起初是为了替代JBPM的,但是后来开发团队内部分歧,主创因为意见不和,离职之后加入其他团队捣鼓出了Flowable。由此可见Flowable必定把Activity以及JBPM带来的的历史遗留问题一一解决,所以也是比较推荐的工作流引擎选择。
说白了捣鼓来捣鼓去的都是同一帮人,和Java日志的历史有点像。
官网:Open Source Business Automation | Activiti
7.4 Flowable
Flowable 基于activiti6衍生出来的版本,目前最新版本是v6.6.0,开发团队是从activiti中分裂出来的,修复了一众activiti6的bug,并在其基础上研发了DMN支持,BPEL支持等等,相对开源版其商业版的功能会更强大。
2016 年 10 月,Activiti 工作流引擎的主要开发者离开 Alfresco 公司,并在 Activiti 分支基础上开启了 Flowable 开源项目。基于 Activiti v6 beta4 发布的第一个 Flowable release 版本为6.0 。
Flowable 也是目前比较主流的一种工作流引擎实现。
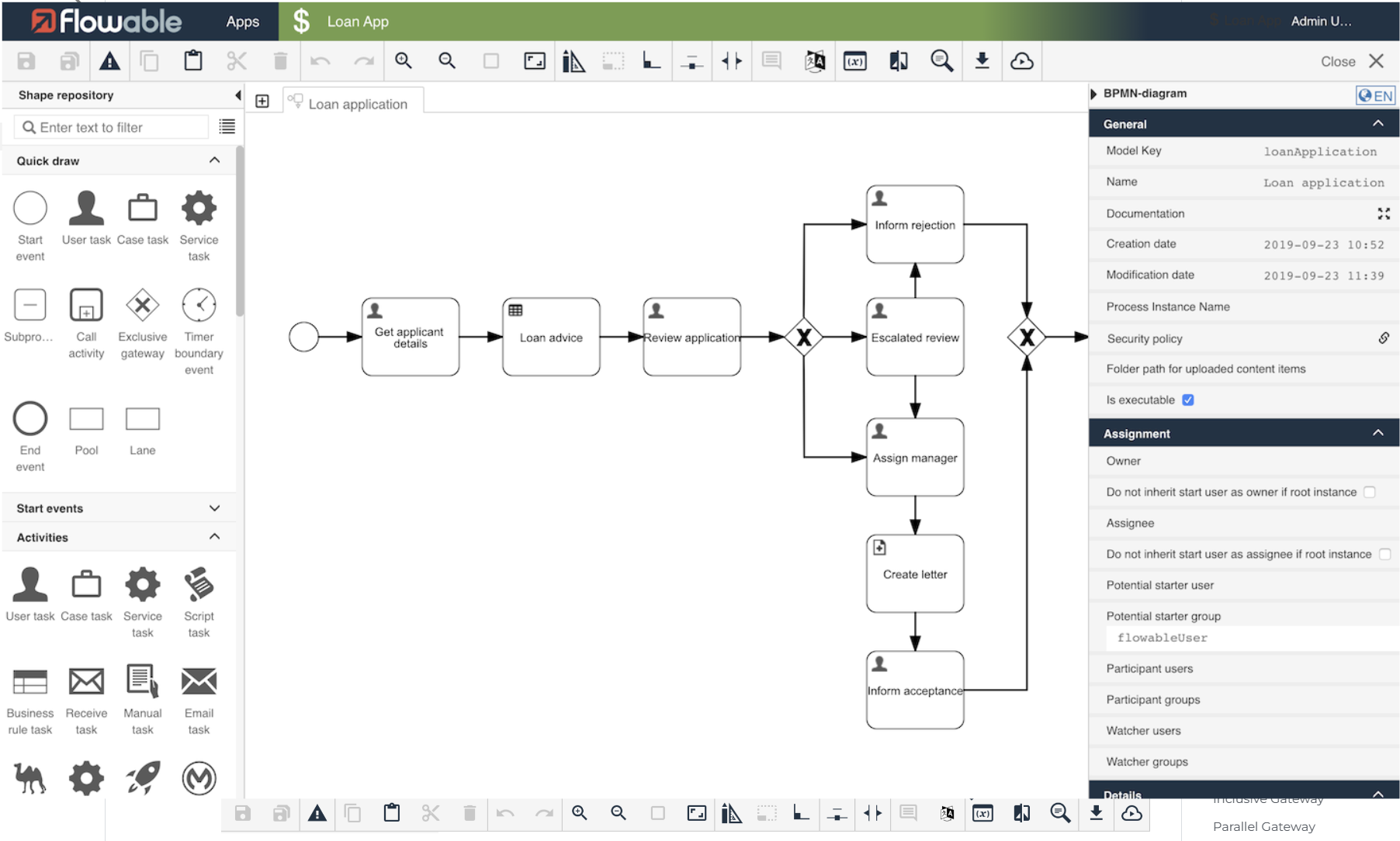
Flowable在后续极力发展商业化,导致开源版本的更新比较落后。
7.5 Camunda
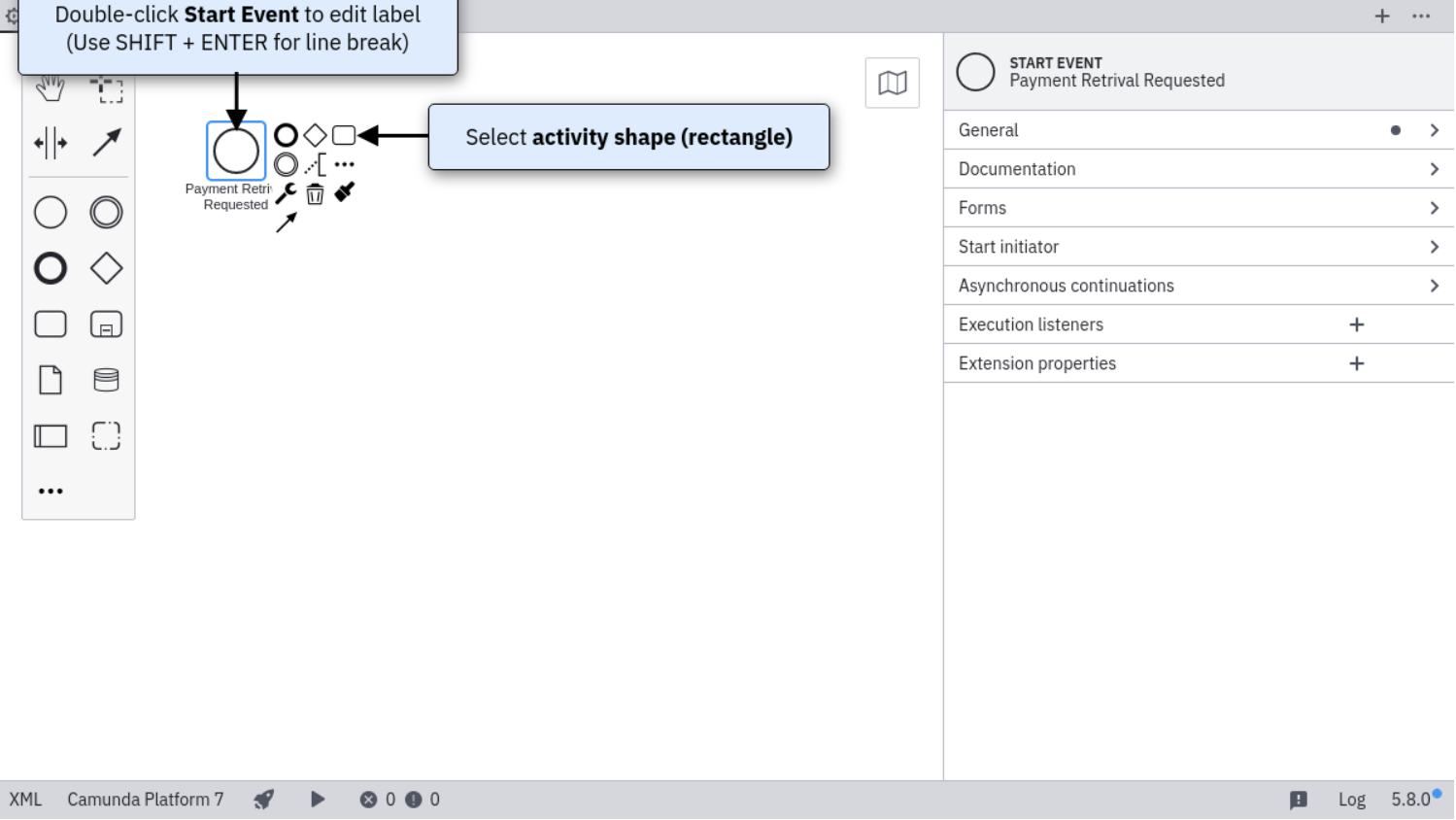
Camunda基于Activiti5,所以其保留了PVM,最新版本Camunda7.15,保持每年发布2个小版本的节奏,开发团队又是从activiti中分裂出来的,发展轨迹与Flowable相似,同时也提供了商业版,不过对于一般企业应用,开源版本也足够了。
黄埔军校:Activity
选择Camunda的理由
(1)通过压力测试验证Camunda BPMN引擎性能和稳定性更好。
(2)功能比较完善,除了BPMN,Camunda还支持企业和社区版本中的CMMN(案例管理)和DMN(决策自动化)。Camunda不仅带有引擎,还带有非常强大的工具,用于建模,任务管理,操作监控和用户管理,所有这些都是开源的。
官方网站:https://docs.camunda.org/manual/7.15/
7.6 Easy-flow
码云上开源的流程设计器,没有社区和用户使用反馈支持,不过多介绍。
如果是深入工作流引擎底层设计本身是一个不错的学习资料。
https://link.zhihu.com/?target=https%3A//gitee.com/xiaoka2017/easy-flow%3F_from%3Dgitee_search
7.7 compileflow
淘宝开源的工作流引擎之一。算是国内最大的开源工作流引擎,但是存在一些“致命伤”,compileflow原生只支持淘宝BPM规范,为兼容BPMN 2.0规范,做了一定适配,但仅支持部分BPMN 2.0元素,如需其他元素支持,可在原来基础上扩展。
github地址:alibaba/compileflow: 🎨 core business process engine of Alibaba Halo platform, best process engine for trade scenes. | 一个高性能流程编排引擎 (github.com)
下面是官方的README介绍:
compileflow IDEA 设计插件: https://github.com/compileflow/compileflow-designer-upgrade
compileflow是一个非常轻量、高性能、可集成、可扩展的流程引擎。
compileflow Process引擎是淘宝工作流TBBPM引擎之一,是专注于纯内存执行,无状态的流程引擎,通过将流程文件转换生成java代码编译执行,简洁高效。当前是阿里业务中台交易等多个核心系统的流程引擎。
compileflow能让开发人员通过流程编辑器设计自己的业务流程,将复杂的业务逻辑可视化,为业务设计人员与开发工程师架起了一座桥梁。
7.8 推荐组合
初学者个人比较推荐 Activity7 + IDEA 的插件组合,最方便上手,Activity 天然支持Spring框架,自动生成的表数量仅为28张,相比 Flowable 的 70多张表而言学习成本算是最低的,并且从上面的介绍可以看出,其他很多对标竞品的开发团队都是从Activity黄埔军校毕业的。

最为关键的是,这个组合网上还可以查到不少资料和实战…..
八、流程设计器选型
8.1 bpmn-js
bpmn-js 是 BPMN 2.0 渲染工具包和 Web 模型,bpmn-js 正在努力成为 Camunda BPM 的一部分。
官方网站:https://bpmn.io/

8.2 mxGraph
mxGraph是一个强大的JavaScript流程图前端库,可以快速创建交互式图表和图表应用程序,国内外著名的ProcessOne和draw.io都是使用该库创建的强大的在线流程图绘制网站。

8.3 Activiti-Modeler
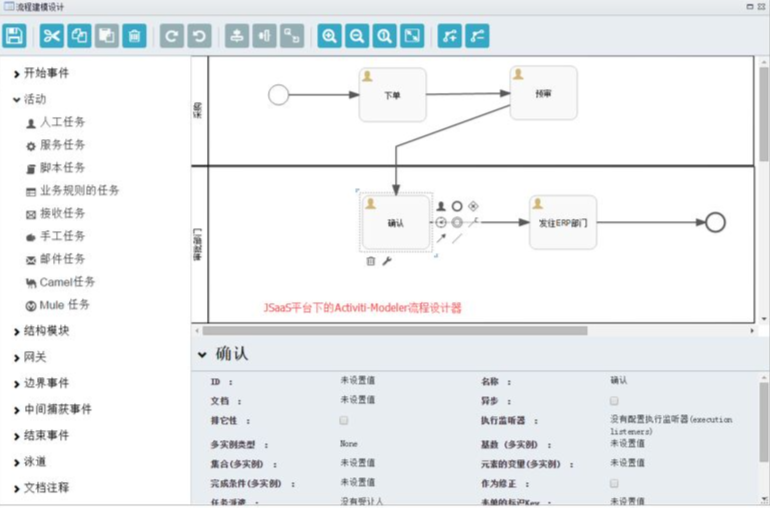
Activiti 的旧版本中存在web版流程设计器,名字叫做Activiti-explorer,优点是集成简单,开发工作量小,缺点是界面不美观,用户体验差。
8.4 Flowable-Modeler
Flowable 开源版本中带了web版流程设计器,展示风格和功能基本跟Activiti-Modeler一样,优点是集成简单,开发工作量小,缺点是界面不美观,用户体验差。

8.5 IDEA Activiti BPMN 插件
个人学习工作流模型图设计比较推荐使用 Idea 的插件,最新版本的插件已经被叫做activiti BPMN visualizer。开发人员可以借助此插件熟悉流程图的绘画过程。
PS:Activity 支持 BPMN2 规范,可以兼容大部分开源工作流框架使用。
8.6 logicFlow
滴滴开发的流程设计器:logicFlow,支持自定义优秀,并可以将bpmn-js以插件形式集成进去,但是不推荐生产使用,比较适合作为国内优秀学习资料的范本。
文档地址:https://github.com/didi/LogicFlow
九、Activity 详解
9.1 为什么要使用 Activity?
Activiti是一个轻量级的工作流和业务流程管理(BPM)平台,面向业务人员,开发人员和系统管理员,核心是用于Java的的BPMN 2流程引擎。
- 开源可参考项目比较多:github和gitee上有非常多的成熟案例可以学习。
- Activiti 支持启动引擎后随时热部署。JBPM存在一个软肋,RuntimeService只能在启动的时候指定bpmn资源,一旦启动后便不再能够去更新或者增加bpmn了,这会导致我们系统集成的困难
- Activity本身开源。开源意味着可以通过社区和其他人的实践案例解决使用问题上的疑难杂症。
- Activiti依赖的第三方jar包相对较少。
- Activiti拥有更友好的用户体验。Activiti则更贴近实际的应用场景,将流程设置为开始节点和结束节点,人工任务提供了表单设置,用户可以设置字段名称,字段类型。
- 自带Spring 集成 ,同时也集成了 Spring Security 框架,也可以认为是自带权限控制功能。
- API 简洁,开发人员可以快速上手。
- Activity 7 没有明显的进步,并且可参考实战案例较少。
1 | TaskQuery taskId(String taskId); |
Spring 集成 Activity 官方文档:Getting started with Activiti and Spring Boot
Activiti User Guide:Activiti User Guide
9.2 Activity 特点
1、数据持久化:Activiti设计思想是简洁与快速。
2、引擎Service接口:Activiti引擎提供了七大Service接口,都是通过ProcessEngine获取,同时支持链式API编程风格。
| Service接口 | 作用 |
|---|---|
| RepositoryService | 流程仓库Service,用于管理流程仓库,如:部署、删除、读取流程资源 |
| IdentifyService | 身份Service,可管理和查询用户、组之间的关系 |
| RuntimeService | 运行时Service,处理所有正在运行的任务和流程实例等 |
| TaskService | 任务Service,用于管理查询任务,如签收、办理、指派等 |
| FormService | 表单Service,用于读取和任务、流程相关的表单数据 |
| HistoryService | 历史Service,可查询所有历史数据 |
| ManagementService | 引擎管理Service,和具体业务无关,可用查询引擎配置、数据库、作业等 |
3、流程设计器:Activiti团队设计了基于BPMN2.0规范的设计器-Eclipse Designer,除此还有Signavio公司为Activiti定制的基于Web的Activiti Modeler流程设计器。
4、原生支持Spring:当前企业开发,基本上都会基于Spring去开发自己的系统,由于A ctiviti原生支持Spring,所以很轻松地进行Spring集成。
5、分离运行时与历史数据:运行与历史数据的分离,可以加快运行时数据的性能,当需要历史数据时,我们在去查询。
9.3 Activiti 应用
1、在系统集成方面:与ESB整合 / 与规则引擎整合 / 嵌入已有系统平台(也是本项目的需求)
2、在其他产品中应用:Alfresco公司的ECM产品在企业中应用,主要涉及文档管理 / 协作 / 记录管理 / 知识库管理 / Web内容管理等。
9.4 Activiti框架与组件
Activiti最重要的就是引擎,除此之外就是外部的工具和组件。
| Modeling | Runtion | Management |
|---|---|---|
| Activiti Modeler | Activiti Engine | Activiti Exproler |
| Activiti Designer | Activiti REST | |
| Activiti Kickstart |
下面对以上组件进行简单的说明:
1、Activiti Engine:最核心的模块,提供针对BPMN2.0规范的解析 / 执行 / 创建 / 管理(任务-流程实例) / 查询历史记录并生成相应报表等。
2、Activiti Modeler:模型设计器,非Activiti公司开发。用于将需求转换为规范流程定义。
3、Activiti Designer:设计器,与Activiti Modeler功能类似。
4、Activiti Exproler:用来管理仓库 / 用户 / 组,启动流程 / 任务办理等。
5、Activiti REST:提供REST风格的服务,允许客户端以JSON的方式与引擎的REST API交互,协议具有跨平台 / 跨语言。
9.6 Activity 工作流要点
9.6.1 Idea插件(学习)
IDEA插件用于Activity 画流程图使用,在2023 年IDEA中这个项目叫做 Activiti BPMN visualizer。可以直接在”Plugins”当中查到。
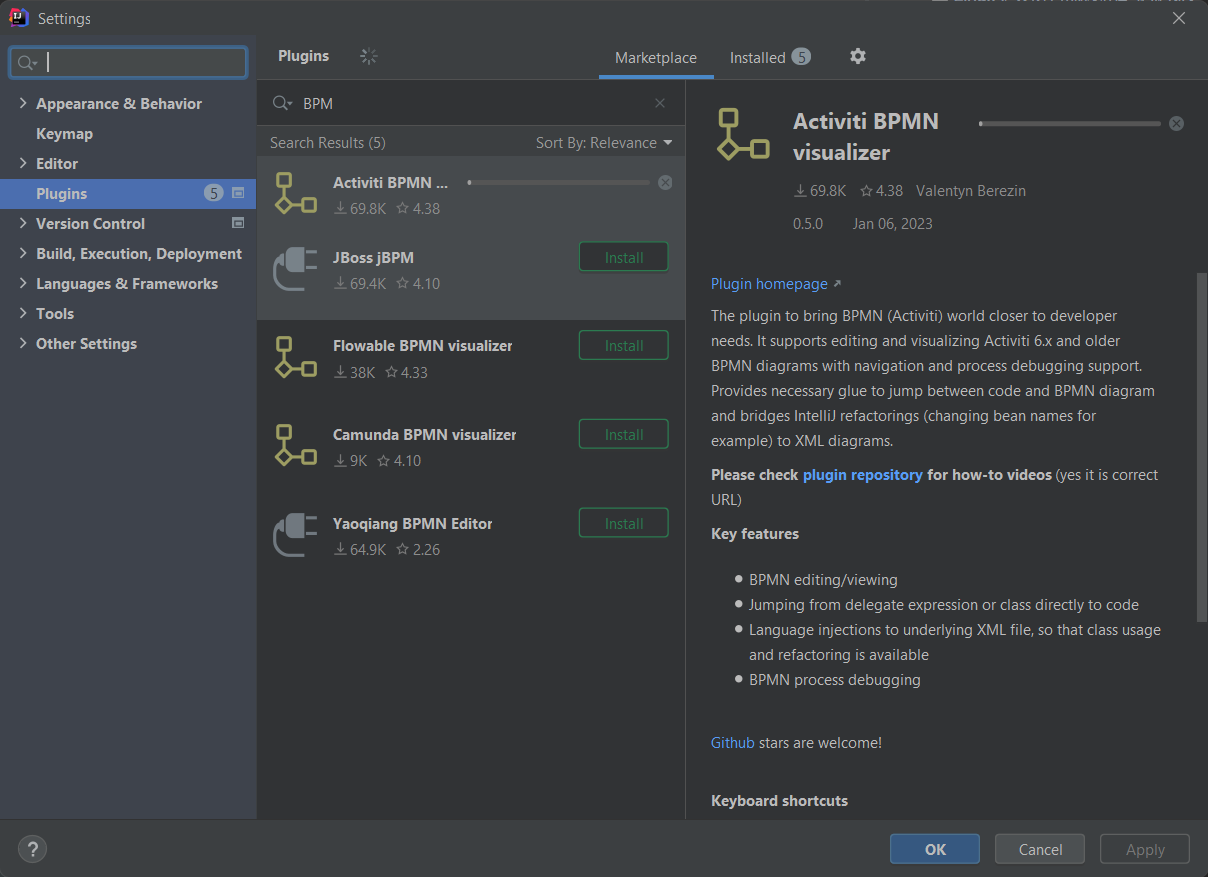
使用IDEA插件的好处是在入门Demo的时候可以不依赖开源流程设计器组件即可绘制一些简单流程,并且由于遵循bpmn2的规范,可以通用在大部分工作流引擎上。
9.6.2 常用 Service
Activiti 提供了几个 Service 类,用来管理工作流,常用的有以下四项:
1) RepositoryService:提供流程定义和部署等功能。比如说,实现流程的的部署、删除,暂停和激活以及流程的查询等功能
2) RuntimeService:提供了处理流程实例不同步骤的结构和行为。包括启动流程实例、暂停和激活流程实例等功能
3) TaskService:提供有关任务相关功能的服务。包括任务的查询、删除以及完成等功能
4) HistoryService:提供 Activiti 引擎收集的历史记录信息服务。主要用于历史信息的查询功能
还有以下两项:
1)ManagementService:job 任务查询和数据库操作
2)DynamicBpmnService:无需重新部署就能修改流程定义内容
而 Spring Boot 集成 Activiti 实现工作流功能,也主要是采用这些 Service 所提供的 相应的 API 来实现的。
9.6.3 ProcessEngine对象
ProcessEngine是Activity的工作引擎也是核心内容,作用是负责生成流程运行时的各种实例及数据、监控和管理流程的运行。实际使用过程一般会静态全局实例化这个对象,如果是Spring框架集成依赖则会由Spring帮我们完成对象创建和托管。
1 | ProcessEngine processEngine =ProcessEngines.getDefaultProcessEngine(); |
1 | ProcessEngine engine = ProcessEngines.getDefaultProcessEngine(); |
9.6.4 安全管理
前面介绍过 Activity 工作流 和 Spring Security 是可以进行绑定和兼容的,并且我们使用的项目不想要Security 也可以通过注解的方式禁用,比如实际项目中就通过下面的方式禁用Spring 的 SecurityAutoConfiguration 和Activity 的 SecurityAutoConfiguration:
1 | (exclude = {DataSourceAutoConfiguration.class, |
9.6.5 配置文件 activiti.cfg.xml
Activity 所需的配置文件也是Activiti核心配置文件,配置内容和我们平常配置JDBC连接类似。下面是参考的配置内容:
1 |
|
9.6.6 application.yml 配置文件
1 | spring: |
database-schema-update 配置为 true,即每次项目启动,都会对数据库进行更新操作,如果表不存在,则自动创建
db-history-used 配置为 true 由于默认是不生成历史表的,配置为 true表示需要生成。
history-level 配置 为 full,表示记录最完整的历史记录。
deployment-mode 配置为 never-fail ,即关闭掉 SpringAutoDeployment。如果不关闭,每次重新启动项目的时候,总是会在 ACT_RE_DEPLOYMENT 自动创建一个名为 SpringAutoDeployment 工作流记录。
- 影响:在开发阶段,需要经常重启项目,久而久之就会导致 ACT_RE_DEPLOYMENT 的记录越来越大了
9.7 表结构
如果配置了开启历史表的使用开关db-history-used: true。那么这里会额外创建历史表结构。项目启动之后会发现项目数据的会自动增加了 28 张 ACT 开头的表。
9.7.1 5 种数据库表
迁移Activity 需要导入所需的数据库表,这些表的特点是所有的表都以ACT_ 开头,第二部分表示对应的标识。
比如:
act_hi_*:’hi’表示 history,此前缀的表包含历史数据,如历史(结束)流程实例,变量,任务等等。
act_ge_*:’ge’表示 general,此前缀的表为通用数据,用于不同场景中。
act_evt_*:’evt’表示 event,此前缀的表为事件日志。
act_procdef_*:’procdef’表示 processdefine,此前缀的表为记录流程定义信息。
act_re_*:’re’表示 repository,此前缀的表包含了流程定义和流程静态资源(图片,规则等等)。
act_ru_*:’ru’表示 runtime,此前缀的表是记录运行时的数据,包含流程实例,任务,变量,异步任务等运行中的数据。Activiti只在流程实例执行过程中保存这些数据,在流程结束时就会删除这些记录。
9.7.2 所有数据表简介
| 表名 | 表注释 |
|---|---|
| act_ge_bytearray | 二进制数据表,存储通用的流程定义和流程资源。 |
| act_ge_property | 系统相关属性,属性数据表存储整个流程引擎级别的数据,初始化表结构时,会默认插入三条记录。 |
| act_re_deployment | 部署信息表 |
| act_re_model | 流程设计模型部署表 |
| act_re_procdef | 流程定义数据表 |
| act_ru_deadletter_job | 作业死亡信息表,作业失败超过重试次数 |
| act_ru_event_subscr | 运行时事件表 |
| act_ru_execution | 运行时流程执行实例表 |
| act_ru_identitylink | 运行时用户信息表 |
| act_ru_integration | 运行时积分表 |
| act_ru_job | 运行时作业信息表 |
| act_ru_suspended_job | 运行时作业暂停表 |
| act_ru_task | 运行时任务信息表 |
| act_ru_timer_job | 运行时定时器作业表 |
| act_ru_variable | 运行时变量信息表 |
| act_hi_actinst | 历史节点表 |
| act_hi_attachment | 历史附件表 |
| act_hi_comment | 历史意见表 |
| act_hi_detail | 历史详情表,提供历史变量的查询 |
| act_hi_identitylink | 历史流程用户信息表 |
| act_hi_procinst | 历史流程实例表 |
| act_hi_taskinst | 历史任务实例表 |
| act_hi_varinst | 历史变量表 |
| act_evt_log | 流程引擎的通用事件日志记录表 |
| act_procdef_info | 流程定义的动态变更信息 |
这里再分类了解一下:
全局通用数据(ACT_GE_*)
| 表名 | 解释 |
|---|---|
| ACT_GE_BYTEARRAY | 二进制数据表,存储通用的流程定义和流程资源。 |
| ACT_GE_PROPERTY | 系统相关属性,属性数据表存储整个流程引擎级别的数据。 |
静态信息表(ACT_RE_*)
| 表名 | 解释 |
|---|---|
| ACT_RE_DEPLOYMENT | 部署信息表 |
| ACT_RE_MODEL | 流程设计模型部署表 |
| ACT_RE_PROCDEF | 流程定义数据表 |
运行数据(ACT_RU_*)
| 表名 | 解释 |
|---|---|
| ACT_RU_DEADLETTER_JOB | 无法执行工作表: 如果一个任务执行了很多次,都无法执行,那么这个任务会写到此表 |
| ACT_RU_EVENT_SUBSCR | 运行时事件 throwEvent、catchEvent 时间监听信息表 |
| ACT_RU_EXECUTION | 运行时流程执行实例 |
| ACT_RU_IDENTITYLINK | 运行时流程人员表,主要存储任务节点与参与者的相关信息 |
| ACT_RU_INTEGRATION | 运行时积分表 |
| ACT_RU_JOB | 运行时定时任务数据表 |
| ACT_RU_SUSPENDED_JOB | 暂停的工作,流程中有一个定时任务,如果把这个任务停止工作了,这个任务会在act_ru_suspended_job中写入数据 |
| ACT_RU_TASK | 运行时任务节点表 |
| ACT_RU_TIMER_JOB | 运行时定时器作业表 |
| ACT_RU_VARIABLE | 运行时流程变量数据表 |
历史数据(ACT_HI_*)
| 表名 | 表注释 |
|---|---|
| act_hi_actinst | 历史节点表 |
| act_hi_attachment | 历史附件表 |
| act_hi_comment | 历史意见表 |
| act_hi_detail | 历史详情表,提供历史变量的查询 |
| act_hi_identitylink | 历史流程用户信息表 |
| act_hi_procinst | 历史流程实例表 |
| act_hi_taskinst | 历史任务实例表 |
| act_hi_varinst | 历史变量表 |
其它表
| 表名 | 解释 |
|---|---|
| ACT_EVT_LOG | 事件日志 |
| ACT_PROCDEF_INFO | 流程定义的动态变更信息 |
简单了解Activity的结构之后,下面介绍项目如何集成 Activity。
十、项目集成 Activity
万事开头难,集成Activity到项目可能是整个学习过程最难的一步,下文会将个人集成过程中遇到的问题一并罗列。
10.1 版本选择
可以参考网络资料选择合适的版本。实际工作中由于可参考案例权衡、时间原因和经验不足等种种原因,个人没有选择资料和成功案例比较少的 Activity7 的版本,而是使用了网上可供参考资料比较多的 6 的版本。
如果要集成Activity 7,可以使用下面的依赖。
根据网络反馈和个人实际尝试,发现集成 Activity 7 同样会因为自带依赖版本冲突导致各种问题。
1 | <dependency> |
实际学习过程个人选择了下面的依赖 选择低版本的根本原因是网上有的代码抄:
- Activity的相关组件依赖,比如将JSON数据转化为Activity的模型的编码依赖,bpmn文件转为数据库以及逆向转化依赖,还有前前端WEB组件需要的一部分依赖。
1 | <!-- Activity 依赖 --> |
- 引入Activity依赖,注意Activity6 使用的是还是ORM的查询方式,自带的mybatis依赖可能和SpringBoot不兼容,所以需要排除依赖附带的低版本Mybatis依赖。
1 | <dependency> |
添加以上依赖之后,启动项目检查是否可以正常启动。
10.2 集成 Activity web 编辑器
由于实际工作需求中要把Activity的 Web 版本组件(Activiti Explorer)集成到项目当中,时间紧迫关系,个人选择参考网上资料最终选择从成熟的项目中拷贝前端依赖学习。
Activity 6.0 之后默认不再集成任何 Expolorer 的组件内容,但是可以从 Activity 5 当中找到相关依赖。参考链接:
- https://github.com/pcharoen/activiti-web/blob/master/wars/activiti-explorer.war
从官方的war包中进行集成比较麻烦,更为快捷的方式是利用网络开源项目直接拷贝前端依赖,兼容到其他项目会稍微好一些。
- RuoYi-activiti: 打造最好用的OA数字化解决方案,基于Activiti6.0,集流程设计、流程部署、流程执行、任务办理、流程监控于一体的开源工作流开发平台。 (gitee.com)
如果觉得成熟项目代码看起来比较复杂难以搜索,可以参考下面这个项目,它基于SpringBoot实现非常简单易懂:
https://github.com/juzhizhang/springboot2-activiti-design
以Ruoyi的项目为例,我们需要拷贝下面的内容:
- src / main / resources / static / diagram-viewer(建议放到 static 目录)
- src / main / resources / static / editor-app(建议放到 static 目录)
- src / main / resources / templates / modeler.html (建议放到 templates 目录下)
- stencilset.json 文件(放到 resources 下)
注意这个组件使用的前端框架为国外比较热门的 angular,比较少见。
注意拷贝完成只是集成第一步,这时候前端是无法正常使用,我们还需要定义控制器,并且给前端提供必要API的接口。
10.3 提供Activity web 编辑器必要API接口
要正常使用 Activity web 编辑器,项目中必须要提供几个必要的API接口。
10.3.1 editor 跳转集成
为了能够进入到编辑流程模型的页面,首先需要提供一个接口跳转到对应html文件。html 文件对应 modeler.html。
1 | ("/editor") |
当我们打开WEB编辑器进行流程模型编辑页面(modeler.html),我们有可能会看到白板,这是因为页面还缺少数据。简单来说就是内部需要结合上下文获取模型资源和组件JSON资源。
接口请求URL请求格式可以通过改前端脚本或者直接修改源码的方式调整。
上面主要包含了后缀分别是sterncliset和json的接口。
10.3.2 sterncliset 接口提供
stencilset.json的大致内容如下,根据英文单词描述,很容易猜测出负责管理前端的组件展示。
案例:
activiti-explorer/editor/stencilset?version=1676012813897。
提供/editor/stencilset控制层接口,通过service层调用获取 json文件内容。
1 | (value = "/editor/stencilset", method = RequestMethod.GET, produces = "application/json;charset=utf-8") |
service中利用了Class类加载器机制,因为 json 文件是放到 resources下面的,可以直接从“根路径” 获取到文件。
1 | public String getStencilset(String resource) { |
10.3.3 加载指定模型数据
json 接口需要对应下面的控制器。
repositoryService:流程仓库Service,用于管理流程仓库,如:部署、删除、读取流程资源。
1 |
|
10.3.4 保存模型接口
模型绘制完成之后,我们需要保存数据接口,下面接口对应保存模型的操作。
1 | (value = "/model/{modelId}/save", method = RequestMethod.PUT) |
saveModel方法代码如下:
1 |
|
10.3.5 关闭页面
根据实际项目情况,有可能需要调整点击关闭请求地址。
1 | closeEditor: function(services) { |
10.3.6 去除Activity logo
搜索.navbar-header,并且修改为下面的内容。
1 | .navbar-header { |
在 moderler.html文件中,删除logo图片展示:
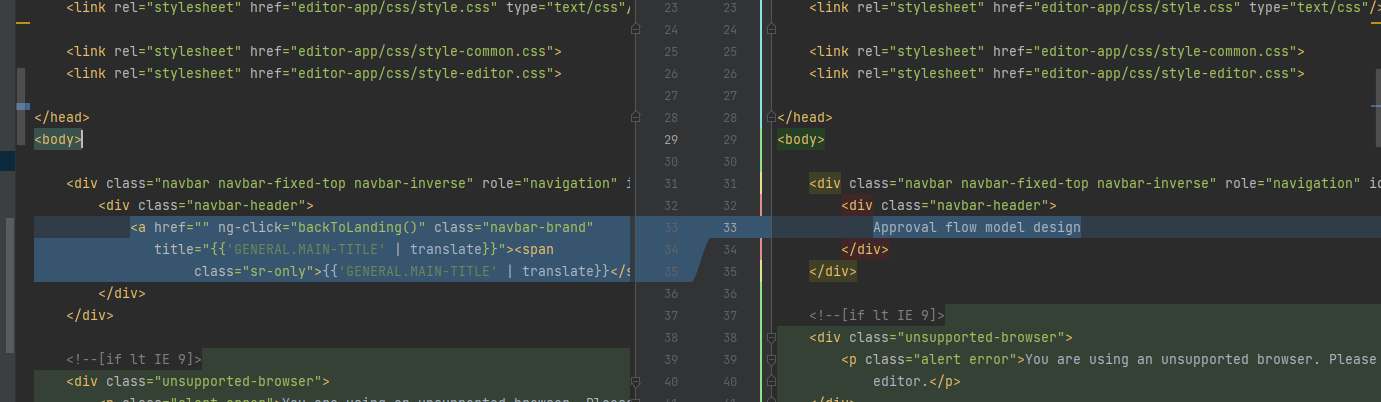
10.3.7 不必要组件流程组件
可以全局搜索下面的注释,或者搜索stencil-controller.js文件找到下面的内容。
1 | // Add the stencil item to the correct group |
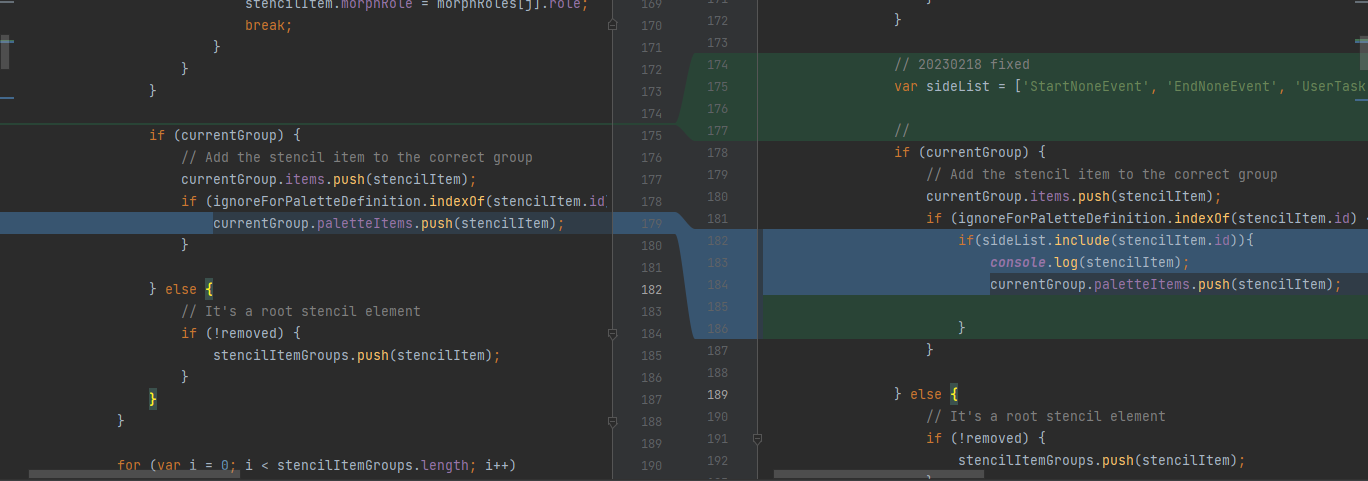
修改下面的代码,代码内部维护一个List,表示前端需要展示的内容,currentGroup用于过滤出符合的组件即可。
这部分功能是要去掉不需要的功能按钮,减少误操作的可能性。
1 | // 20230218 fixed |
10.3.8 隐藏不必要的底部编辑窗口
底部编辑窗口也需要隐藏掉不需要的内容,隐藏思路和7点类似。
搜索selectedItem.properties.push(currentProperty);,或者找到文件stencil-controller.js找到下面的内容。
1 | selectedItem.properties.push(currentProperty); |
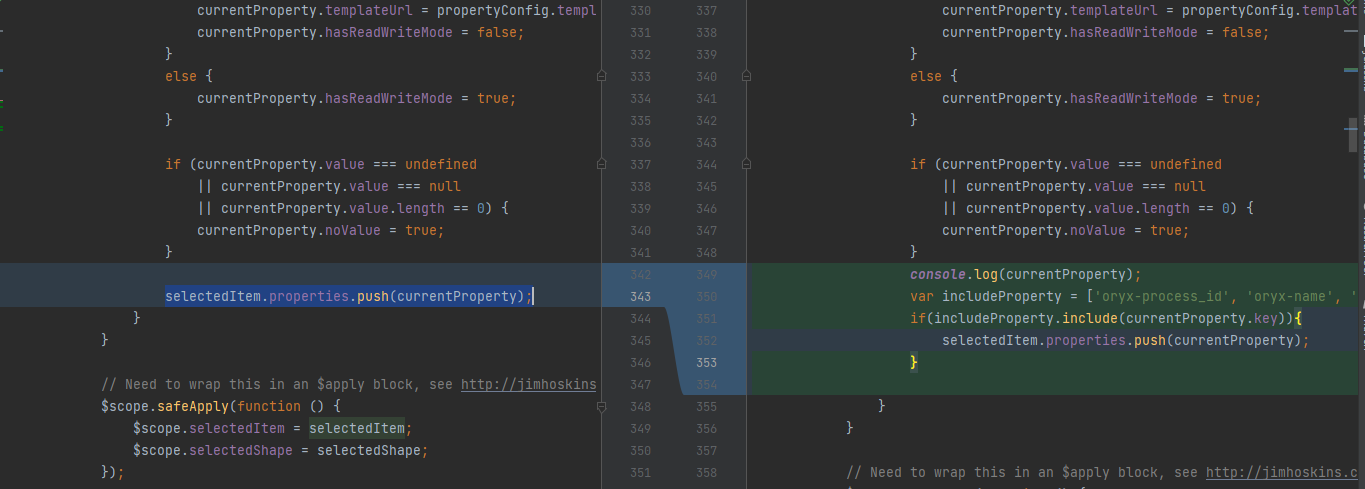
依葫芦画瓢,这里也添加一个数组:
1 | var includeProperty = ['oryx-process_id', 'oryx-name', 'oryx-documentation', 'oryx-usertaskassignment']; |
这时候你可能会好奇,这些啥 stencilset.json,实际上结合前端展示的数据标签以及stencilset.json可以找到相关内容,当然仔细阅读源代码也是种办法。
1 | 'oryx-process_id', 'oryx-name', 'oryx-documentation', 'oryx-usertaskassignment |
10.3.9 分配负责人转为下拉框
实际应用中个人对于源码进行调整,把Assignee原本的流程变量表达式控制节点流转功能(下文会补充这个用法),转为选择固定的下拉系统角色,等于说是阉割灵活性使得非开发人员也可以正常上手(这部分完全是业务需要)。
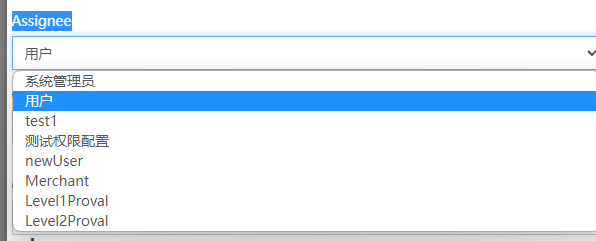
实现这样的效果要查找到Activity这部分的源码,查找需要花不少时间这里就直接说答案了,找到assignment-popup.html文件,在开头第十行左右的位置。
1 | <div class="row row-no-gutter"> |
被注释掉的部分就是原本的Input text输入框。这里修改为是用下拉框,并且后台提供接口查询当前系统的所有角色数据。
1 | (value = "/editor/systemRoleNames", method = RequestMethod.GET, produces = "application/json;charset=utf-8") |
10.3.10 最终检查
最后访问/editor 接口查看是否正常。
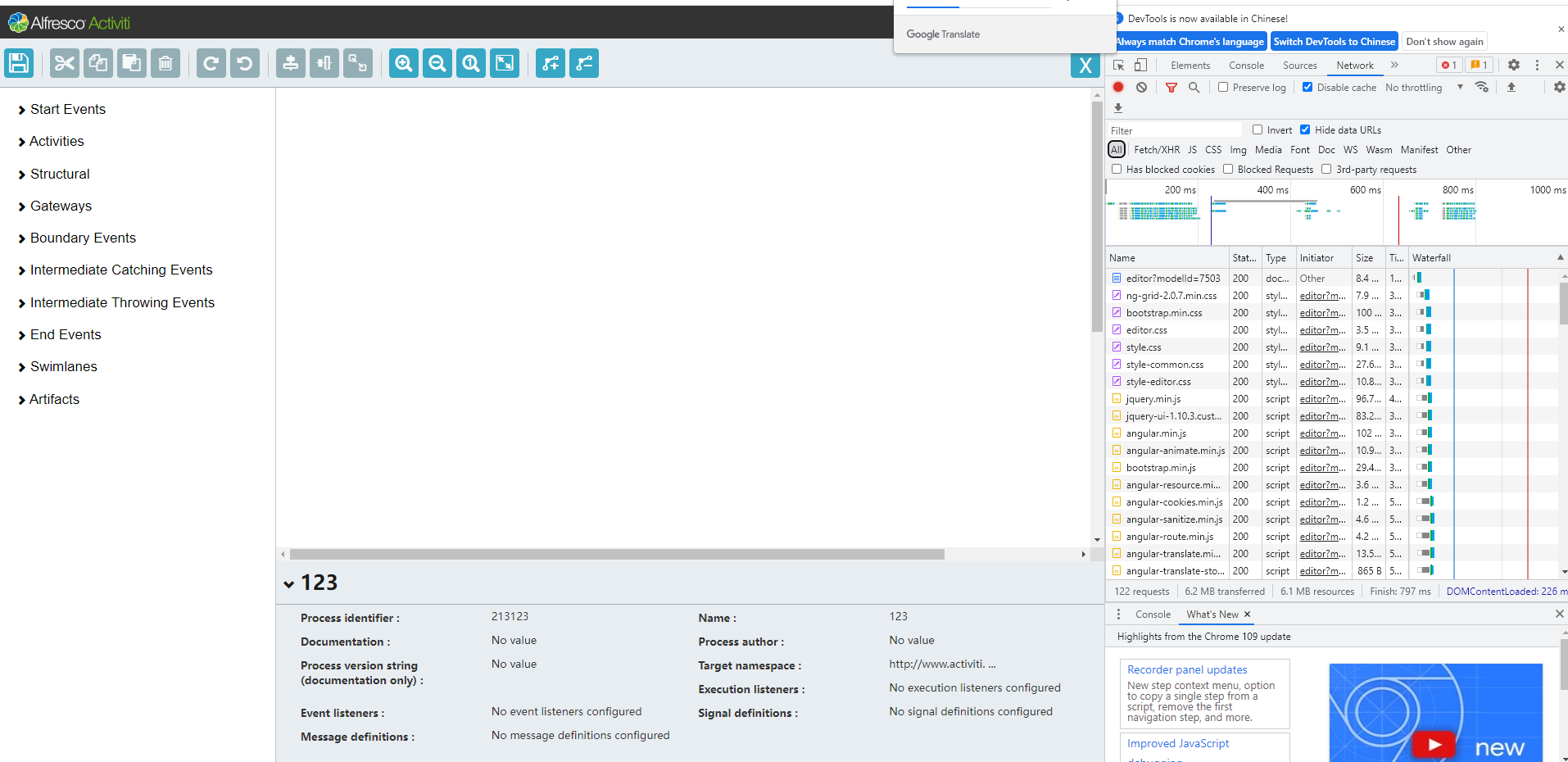
完成上面那一套之后,如果出现如上页面,说明web编辑器集成成功。
毋庸置疑,这里截图为未隐藏不必要菜单版本。
10.4 可能遇到的问题
10.4.1 Factory method ‘springProcessEngineConfiguration’ threw exception; nested exception is java.io.FileNotFoundException: class path resource [processes/] cannot be resolved to URL because it does not exist
其实英文已经说的很明显了,需要添加一个processes文件夹在resources的目录。可以通过在yml配置当中将check-process-definitions: false 去除强制检查。process-definition-location-prefix可以修改模型图的存储位置。
1 | # Spring配置 |
10.4.2 application.yml 配置
Activity 6 的参考配置如下:
1 | activiti: |
10.4.3 java.lang.IllegalArgumentException: Could not find class [org.springframework.boot.autoconfigure.security.SecurityAutoConfiguration]
这个报错很简单,意思是说找不到Spring的安全管理类。通常情况下只需要把SpringBoot的Security排除或者Activity的Security排除即可。
比如下面的方式排除Activity的依赖。(个人建议)
1 | (exclude = { |
但是如果项目中没有使用Spring Securrity,那么规避此问题请继续看下一个解决方案。
10.4.4 Failed to process import candidates for configuration class [com.sa.SaAdminImplApplication]; nested exception is java.io.FileNotFoundException: class path resource [org/springframework/security/config/annotation/authentication/configurers/GlobalAuthenticationConfigurerAdapter.class] cannot be opened because it does not exist
这个报错是在加入Activity之后,Activity旧版本的安全管理类和SpringBoot的安全管理产生的冲突。如果出现类似报错,请检查是否存在下面的依赖。
1 | <dependency> |
如果项目中并没有用Security的任何依赖,那么排除依赖的处理方式启动还是报错,由于集成的项目使用了Shiro,于是决定在SaAdminWebApplication中进行如下设置:
1 | (exclude = { |
如上配置之后最后项目成功启动。
10.4.5 可视化编辑器的页面白板问题处理
集成在线可视化流程图编辑器的时候,首次跳转modeler.html 页面可能会出现下面的错误,整个页面都是一块“白板”。

这是初学者集成比较容易犯的错误,遇到这样的画面,可以在modeler.html页面的浏览器中打开F12,在“Network”当中可以看到有几个请求报错爆红。这几个接口的获取分别是 获取模型JSON信息以及 获取模型自身JSON数据。关键问题是集成WEB版本的流程编辑器之后,访问开源的modeler.html的编辑器页面,页面会自动发送请求。为了节省读者时间,这里省略了查找请求接口调用脚本的过程。
我们可以阅读 ${项目路径下的static文件夹}$\model\manage\editor-app\app-cfg.js这里的配置,文件内容如下,这里的contextRoot对应上下文信息activiti-explorer在请求中出现了。
app-cfg.js
1 | ; |
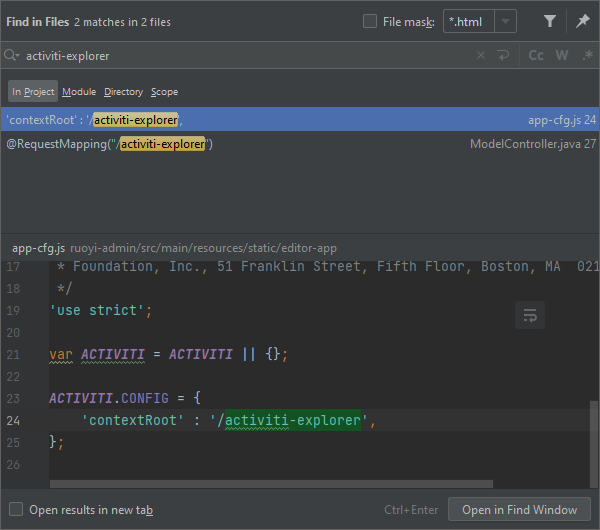
这个 contextRoot 的设置又有什么含义?举个例子,这里访问到编辑器的请求为/activiti-explorer/model/7503/json,7503 对应模型的唯一ID通过数据库可以查询出来,/activiti-explorer则对应了上下文部分。
这里可能会问了,上下文是知道了,但是怎么知道脚本在哪里发送请求的。这里介绍一下IDEA搜索技巧,我们全局搜索contextRoot,最终可以找到名为url-config.js的文件的相关配置。
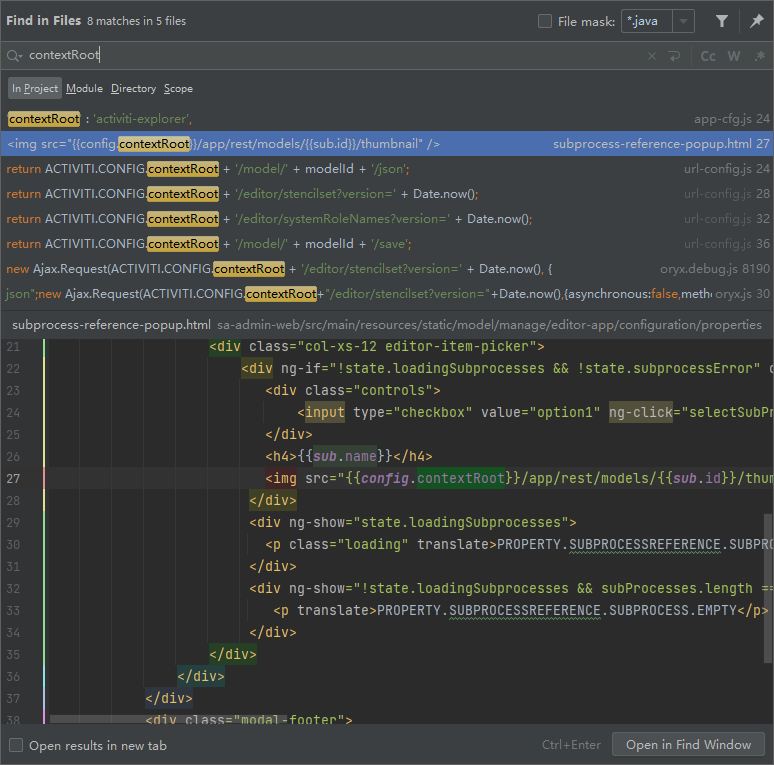
文件开头有一大段注释,根据代码内容可以看到这里就是整个Activity前端需要的调用接口的全局配置。
getRoleNames为业务需求添加。
url-config.js 文件内容如下:
1 | var KISBPM = KISBPM || {}; |
10.4.6 补充:集成到实际项目的注意事项
最为推荐的方式建议找一个能正常跑的SpringBoot项目,对照项目一个个添加Activity的相关依赖,遇到报错根据错误去搜索解决。这种方式也可以节省下大量的试错而浪费的时间。
什么意思呢?这里回到依赖部分,比如下面的依赖我们可以先只添加一个,打包依赖之后直接部署项目查看是否和已有的依赖存在冲突,也可以利用IDEA工具来解决依赖冲突问题。
1 | <!-- Activity 依赖 --> |
至此我们把Activity 成功集成到项目当中,下面开始了解Activity的具体细节。
十一、Activity 设计流程图(各种组件,如连线、用户任务、网关)
我们将Activity的web版本流程设计编辑器集成之后,前后端此时就可以完成基本的模型新增和编辑操,在介绍具体的代码增删改查之前,我们先了解如何使用Activity 流程设计器。
下面介绍最简单的基础的模型绘制和使用。
注意演示版本为最为简单的工作流版本,更为复杂的工作流程设计可以将所有组件展示之后自行了解。
11.1 各种组件
注意下面的图中个人隐藏掉大部分按钮,篇幅有限,这里只介绍几个最简单和基础的功能。
11.2.0 主界面
主界面分为四个部分:左侧为功能按钮区域,顶部是一些针对流程图设计的快捷功能,比如剪切,粘贴,复制,还有放大和缩小等。右边空白区域为绘制流程图的区域,我们需要从左侧菜单拖拽节点到右侧绘制流程图,最后是底部的节点描述区域,其中可以设置节点的名称,节点的文档描述,对于连线或者用户活动,则可以设置流程变量或者分配责任人等操作。
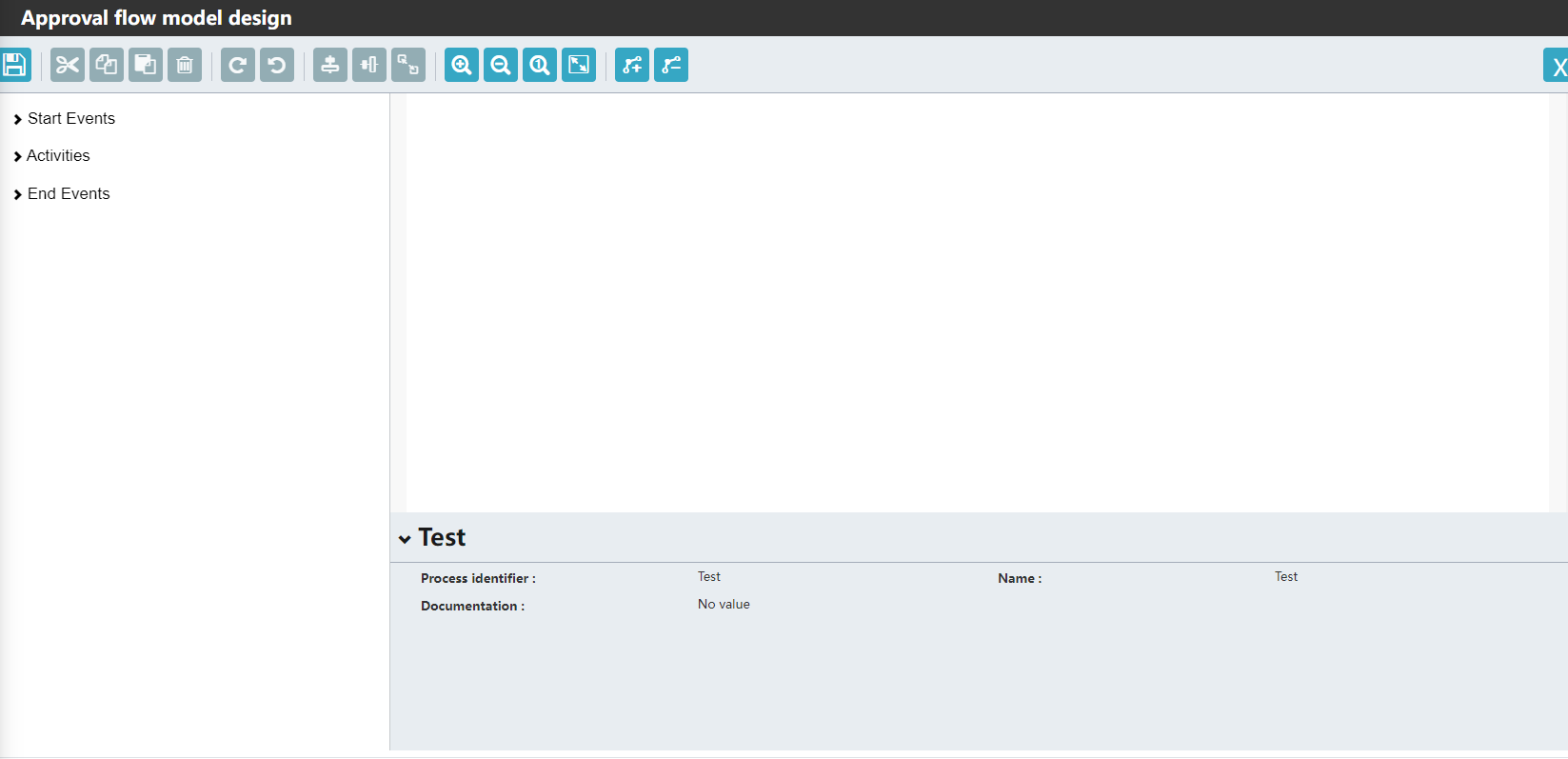
回到左侧菜单,这里先介绍必备的开始节点和结束节点这两个组件。
11.2.1 Start Events
开始事件:开始事件并不是一个活动,它仅仅代表一个节点的开始。也是一个流程实例的起点开始节点,仅仅可以设置节点名称以及节点的备注和文档描述(对应底部部分)。开始事件多数情况下仅有一个。
11.2.2 EndEvents
结束事件:结束事件不一定和开始事件一样一一对应的,在复杂的工作流模型中,可以根据不同的分支进入出现多个结束节点。
11.2.3 插曲:最简单的工作流
Activity最简单的工作流实际上是像下面这样,直接把开始节点连接到结束节点,虽然它没有任何实际意义,但是它确实可以正确部署(不会产生报错和异常),并且成功部署为一个可以运作的工作流。
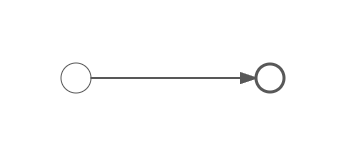
下面是保存操作,save之后即可保存,修改过程可以编辑名称和唯一标识。

11.2.4 User Task
用户任务是最为简单也是最常用的的一种活动节点,对应我们日常工作的业务流转或者任务流转,用户任务同样可以设置节点名称和文档描述。

除此之外,用户活动作为活动节点,可以设置负责人:
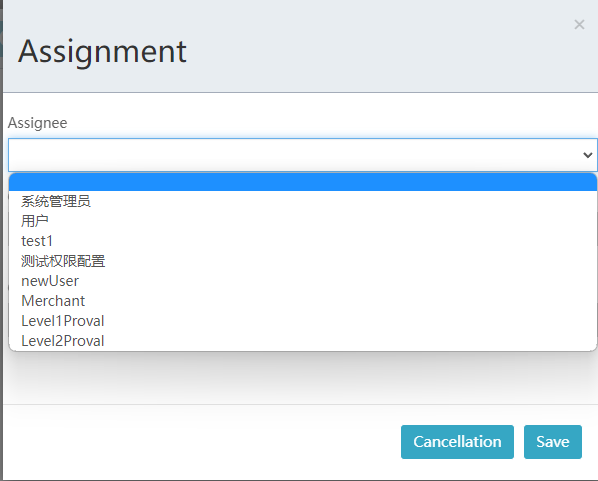
这里assignment 下拉选择对应的负责人即可。
11.2 连线
连线目前项目仅仅使用箭头连线,箭头连线基本可以覆盖99% 的使用场景,所以其他两种连线方式这里就忽略了。
注意:连线实际上输入流程变量条件表达式,实现同一个“出口”进入不同下一个活动节点功能,通过连接的表达式也可以实现各种细节判断。
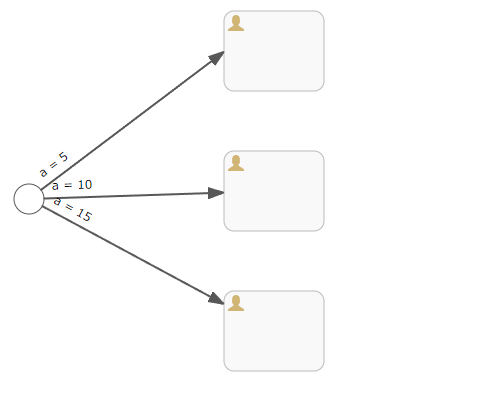
后续此部分可以补充和完善。
11.3 用户任务
User Task只是活动分类的一个细节分支,实际上除开用户任务之外很多用户任务。同样因为项目需求暂时没有更多设计流程上更为复杂的需求,所以一并忽略了。
后续此部分可以补充和完善。
11.4 网关
虽然项目中并没有用到任何网关组件,但是网关是实现复杂组件的前提这里一并补充介绍。
11.4.1 什么是排他网关?
排他网关,用来在流程中实现决策。 当流程执行到这个网关,所有分支都会判断条件是否为true,如果为true则执行该分支,否则执行另外的条件分支。
注意:排他网关只会选择一个为true的分支执行。如果有两个分支条件都为true,排他网关会选择id值较小的一条分支去执行,当然不建议实际使用过程中去“碰瓷”这个条件。
为什么要用排他网关?
不用排他网关也可以实现分支,但是在连线设置condition条件的缺点如果条件都不满足,流程就异常结束了(或者说看起来像是永远挂起)。
如:在连线的condition条件上设置分支条件。
在下面的案例当中,排他网关起到了分支 if/else 判断的作用。
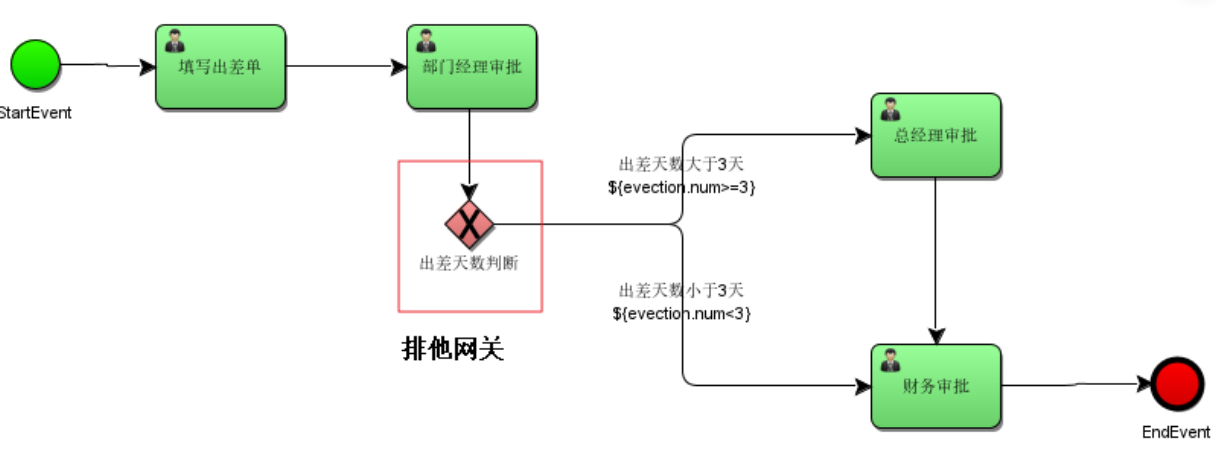
需要注意,如果从网关出去的线所有条件都不满足则系统抛出异常。
1 | org.activiti.engine.ActivitiException: No outgoing sequence flow of the exclusive gateway 'exclusivegateway1' could be selected for continuing the process |
排他网关的图标通常是一个 X。

11.4.2 并行网关ParallelGateway
并行网关允许将流程分成多条分支,也可以把多条分支汇聚到一起,并行网关的功能是基于进入和外出顺序流的。
分支汇聚的术语叫做 fork/join,和 Java的 fork / join 概念类似。
fork分支:并行之后的所有外出顺序流,为每个顺序流都创建一个并发分支。
join汇聚:所有到达并行网关,在此等待的进入分支, 直到所有进入顺序流的分支都到达以后, 流程就会通过汇聚网关。
与其他网关的主要区别是,并行网关不会解析条件。 即使顺序流中定义了条件,也会被忽略。
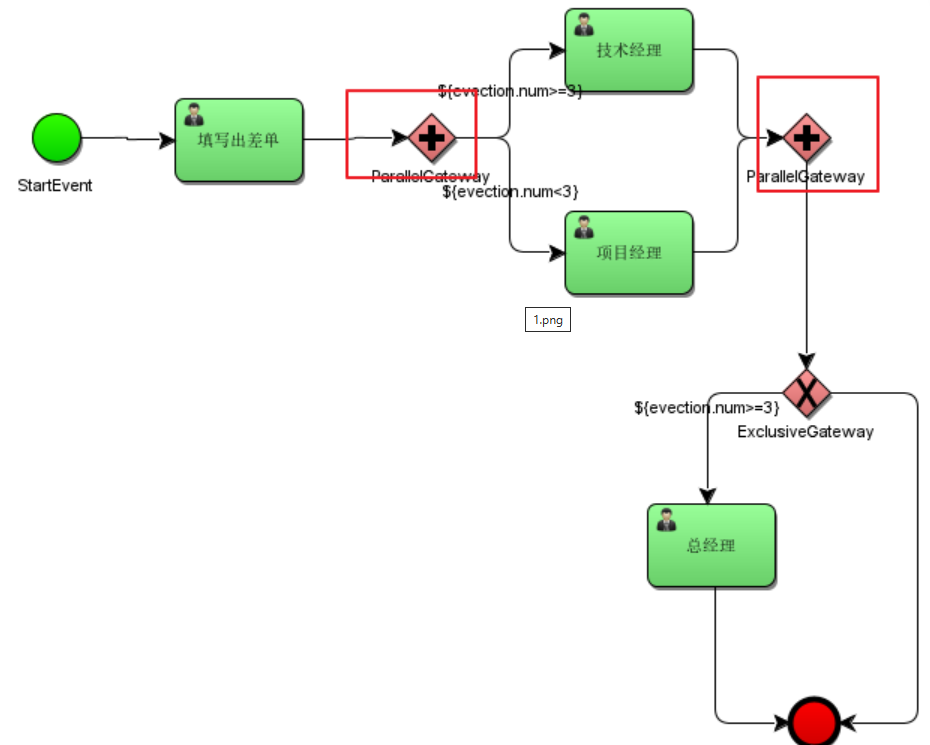
技术经理和项目经理是两个execution分支,在act_ru_execution表有两条记录分别是技术经理和项目经理,act_ru_execution 还有一条记录表示该流程实例。
待技术经理和项目经理任务全部完成,在汇聚点汇聚,通过parallelGateway并行网关。
fork/join 的工作模式经常用在多个人共同完成一个任务的时候使用,比如一个方案要两个人都完成签字审批之后才能进入到下一步。
并行网关的图案是十字架样式。
11.4.3 什么是包含网关
包含网关可以看做是排他网关和并行网关的结合体。包含网关和排他网关一样,可以在外出顺序流上定义条件,包含网关会解析它们。
包含网关和排他网关的主要区别是包含网关可以选择多于一条顺序流,这和并行网关一样。包含网关的功能是基于进入和外出顺序流的:
分支:所有外出顺序流的条件都会被解析,结果为true的顺序流会以并行方式继续执行, 会为每个顺序流创建一个分支。
汇聚:所有并行分支到达包含网关,会进入等待状态, 直到每个包含流程token的进入顺序流的分支都到达。 这是与并行网关的最大不同。换句话说,包含网关只会等待被选中执行了的进入顺序流。 在汇聚之后,流程会穿过包含网关继续执行。

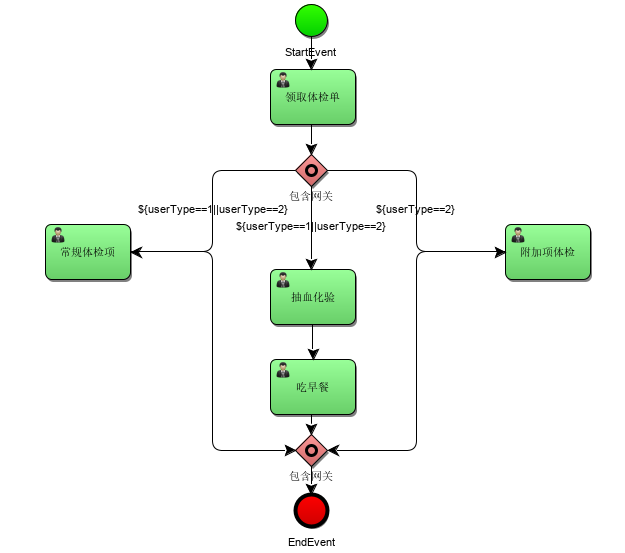
11.4.4 事件网关 EventGateway
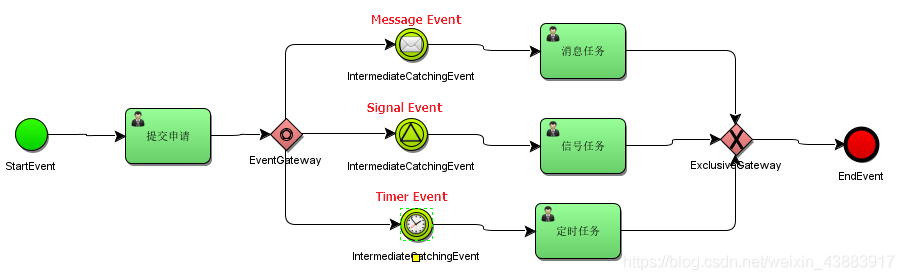
事件网关必须有两条或以上外出顺序流;
事件网关允许根据事件判断流向。网关的每个外出顺序流都要连接到一个中间捕获事件。 当流程到达一个基于事件网关,网关会进入等待状态:暂停执行。与此同时,会为每个外出顺序流创建相对的事件订阅。
事件网关的外出顺序流和普通顺序流不同,这些顺序流不会真的”执行”, 相反它们让流程引擎去决定执行到事件网关的流程需要订阅哪些事件。 要考虑以下条件:
使用事件网关要考虑以下条件:
- 基于事件网关必须有两条或以上外出顺序流;
- 基于事件网关后,只能使用intermediateCatchEvent类型(activiti不支持基于事件网关后连接ReceiveTask。);
- 连接到事件网关的中间捕获事件必须只有一个入口顺序流。

intermediateCatchEvent 类型选择如下:
intermediateCatchEvent支持的事件类型:
- Message Event: 消息事件
- Singal Event: 信号事件
- Timer Event: 定时事件
使用事件网关定义流程:
十二、如何使用 Activity 进行开发
当Activity集成到项目并且了解了如何利用WEB的模型编辑器绘制模型之后,我们下面要正式开始Activity工作流的开发工作。
涉及具体的业务之前,我们先介绍所有业务都能够通用部分。
12.1 流程定义增删改查
流程定义增删改查包含两个部分,一个是模型设计,另一个是部署流程。这部分内容涉及到纯粹的代码。通过了解增删改查Activity的审批流模型代码,可以帮助我们熟悉API使用。
12.1.1 添加新模型代码
新增模型我们需要传输下面几个变量:
- modelName 模型名称:因为实际存储为xml,所以不能有特殊字符,建议只允许大小写字母。不允许重名
- modelFlag 模型标识:类似模型的唯一标识,同样监狱不要有特殊字符,建议只允许大小写字母。
- classify:模型分类,可选,用于使用过程中对于业务模型进行分类
- description:描述信息,可选。
- version:每次新部署的模型就是一个新的版本,初始部署的模型版本为1,之后每部署一次都将会+1。类似乐观锁
1 |
|
简单理解是将数据封装为Hashmap,最后通过jackson转为字节数据写入到Activity的数据表即可。数据库的最终表现形式如下:
act_re_model
| id_ | rev_ | name_ | key_ | category_ | create_time_ | last_update_time_ | version_ | meta_info_ | deployment_id_ | editor_source_value_id_ | editor_source_extra_value_id_ | tenant_id_ |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 22547 | 11 | QAZX | QAZX | QAZX | ######## | ######## | 4 | {“name”:”QAZX”,”description”:”QAZX”,”revision”:null} | 22548 | 22549 | ||
| 15001 | 7 | MerchantFreeze | MerchantFreeze | MerchantFreeze | ######## | ######## | 2 | {“name”:”MerchantFreeze”,”description”:”MerchantFreeze”,”revision”:null} | 112501 | 15002 | 15003 | |
| 135043 | 5 | RiskRulesSetting | RiskRulesSetting | RiskRulesSetting | ######## | ######## | 2 | {“name”:”RiskRulesSetting”,”description”:”RiskRulesSetting”,”revision”:null} | 135046 | 135044 | 135045 | |
| 155044 | 5 | MerchantFee | MerchantFee | MerchantFee | ######## | ######## | 2 | {“name”:”MerchantFee”,”description”:”MerchantFee”,”revision”:null} | 155047 | 155045 | 155046 | |
| 127544 | 9 | IP | IP | IP | ######## | ######## | 4 | {“name”:”IP”,”description”:”IP”,”revision”:null} | 175044 | 127545 | 127546 | |
| 220001 | 5 | MerchantVaRefund | MerchantVaRefund | MerchantVaRefund | ######## | ######## | 2 | {“name”:”MerchantVaRefund”,”description”:”MerchantVaRefund”,”revision”:null} | 220004 | 220002 | 220003 | |
| 202592 | 5 | MerchantOpenAccount | MerchantOpenAccount | MerchantOpenAccount | ######## | ######## | 2 | {“name”:”MerchantOpenAccount”,”description”:”MerchantOpenAccount”,”revision”:null} | 202595 | 202593 | 202594 |
12.1.2 查询所有流程模型
1 | public List<Model> listModelAll() { |
12.1.3 分页查询流程模型
1 |
|
12.1.4 删除流程模型
1 |
|
12.1.5 导出模型
有时候需要导出model文件,我们可以用下面的代码实现,.bpmn20.xml这个20并不是写错了,而是bpmn2.0规范要求的后缀,IDEA插件也会根据此后缀进行智能识别。
换句话说就是后缀写错了识别不了。
1 |
|
12.1.6 部署流程
部署模型首先需要在资源库中找到对应的模型,转化为BpmnModel,之后需要创建部署工具设置相关参数之后执行部署。
1 |
|
之后是保存数据库当中。数据库的最终表现形式如下:
act_re_deployment
| id_ | name_ | category_ | key_ | tenant_id_ | deploy_time_ | engine_version_ |
|---|---|---|---|---|---|---|
| 22550 | QAZX | QAZX | QAZX | ######## | ||
| 27501 | QAZX | QAZX | QAZX | ######## | ||
| 112501 | MerchantFreeze | MerchantFreeze | MerchantFreeze | ######## | ||
| 135046 | RiskRulesSetting | RiskRulesSetting | RiskRulesSetting | ######## | ||
| 155047 | MerchantFee | MerchantFee | MerchantFee | ######## | ||
| 165001 | regist | regist | regist | ######## | ||
| 175044 | IP | IP | IP | ######## | ||
| 180047 | regist | regist | regist | ######## | ||
| 202595 | MerchantOpenAccount | MerchantOpenAccount | MerchantOpenAccount | ######## | ||
| 220004 | MerchantVaRefund | MerchantVaRefund | MerchantVaRefund | ######## | ||
| 225091 | regist | regist | regist | ######## |
12.1.7 业务绑定
业务绑定实现了工作流和业务标识的绑定操作,在具体的编码过程中可以通过业务绑定标识找到指定模型,并且根据部署的模型构建不同的流程实例。
1 |
|
12.2 启动流程实例
构建流程增删改查之后,接下来将介绍如何构建和启动一个流程。
12.2.1 什么是流程实例
流程实例(ProcessInstance)代表流程定义的执行实例。一个流程实例包括了所有的运行节点。我们可以利用这个对象来了解当前流程实例的进度等信息。
例如:我们部署了一个请求的工作流模型,定义了请求流程,现在要按照流程提交一个请求申请,就是启动流程实例。

12.2.2 启动实例和添加Businesskey(业务标识)
流程定义部署在activiti后,就可以在系统中通过activiti去管理该流程的执行,执行流程表示流程的一次执行。启动流程实例时如果指定 businesskey,就会在 act_ru_execution 流程实例的执行表中存储businesskey。
Businesskey:业务标识,通常为业务表的主键,业务标识和流程实例一一对应。业务标识来源于业务系统。存储业务标识就是根据业务标识来关联查询业务系统的数据。
1 | /** * 启动流程实例,添加businessKey */ |
businessKey对应的就是部署流程表中的 key_ 这个字段,name则对应我们流程模型的名称:
| id_ | name_ | category_ | key_ | tenant_id_ | deploy_time_ | engine_version_ |
|---|---|---|---|---|---|---|
| 22550 | QAZX | QAZX | QAZX | ######## | ||
| 27501 | QAZX | QAZX | QAZX | ######## | ||
| 112501 | MerchantFreeze | MerchantFreeze | MerchantFreeze | ######## | ||
| 135046 | RiskRulesSetting | RiskRulesSetting | RiskRulesSetting | ######## | ||
| 155047 | MerchantFee | MerchantFee | MerchantFee | ######## | ||
| 165001 | regist | regist | regist | ######## | ||
| 175044 | IP | IP | IP | ######## | ||
| 180047 | regist | regist | regist | ######## | ||
| 202595 | MerchantOpenAccount | MerchantOpenAccount | MerchantOpenAccount | ######## | ||
| 220004 | MerchantVaRefund | MerchantVaRefund | MerchantVaRefund | ######## | ||
| 225091 | regist | regist | regist | ######## |
构建之后,从Activiti的act_ru_execution中存储业务标识,启动流程实例,操作如下数据库表:
1 | #流程实例执行表,记录当前流程实例的执行情况 |
流程实例执行。如果当前只有一个分支,一个流程实例只有一条记录,且执行表的主键id和流程实例id相同,如果当前有多个分支正在运行则该执行表中有多条记录,存在执行表的主键和流程实例id不相同的记录。
不论当前有几个分支,总会有一条记录的执行表的主键和流程实例id相同。
查询流程实例
流程在运行过程中可以查询流程实例的状态,当前运行结点等信息。
1 |
|
关联BusinessKey
在activiti实际应用时,查询流程实例列表可能要显示出业务系统的一些相关信息。在查询流程实例时,通过businessKey(业务标识 )关联查询业务系统。通过下面的代码就可以获取activiti中所对应实例保存的业务Key。
1 | String businessKey = processInstance.getBusinessKey(); |
在activiti的act_ru_execution表,字段BUSINESS_KEY就是存放业务KEY的。
12.3 任务流转
启动流程实例之后,接下来就是任务的增删改查,每一个Task对应了工作流中的活动,我们可以通过下面的方式查询任务负责人的待办任务:
1 | // 查询当前个人待执行的任务 |
我们可以通过组合查询条件,实现特定人员查询特定的业务内容。任务流转给下一个人需要先获取任务ID,然后调用taskService的complete方法完成当前审批人的代办任务。
1 | /** |
12.4 完成任务
注意:在实际应用中,完成任务前需要校验任务的负责人是否具有该任务的办理权限 。完成任务的模板代码和任务流转类似,但是需要额外判断当前节点是否为最后一个待办节点。
1 | /** |
12.4.1 如何知道当前节点是否为最后一个待办节点?
具体可以阅读com.sa.impl.utils.ActivityUtils#getNextNode(java.lang.String, java.lang.String, java.util.Map<java.lang.String,java.lang.Object>)这一部分。
1 | public List<UserTask> getNextNode(String procDefId, String taskDefKey, Map<String, Object> map) { |
整体思路是找到当前节点的所有连线,然后判断当前连线的下一个节点是否是一个“结束节点”,如果是则证明当前节点已经到达最后一步。
PS:建议设计流程图仅仅为结束节点配一个前置节点和连线。
12.5 流程变量
12.5.1 什么是流程变量
流程变量在 activiti 中十分重要, 比如我们在流程变量当中维护一个“观察者角色列表”,将记录的所有可见角色到流程变量中存储,流程变量在流程控制中主要是控制流程流转的细节控制。
注意:虽然流程变量中可以存储业务数据,也可以通过activiti的api查询流程变量实现查询业务数据,但是实际上不建议这样使用,因为业务数据查询由业务系统负责,activiti设置流程变量是为了流程执行需要而创建。
12.5.2 流程变量类型
数据来源:Table 10. Variable Types。
https://www.activiti.org/5.x/userguide/#apiVariables
| Type name | Description |
|---|---|
| string | Value is threaded as a java.lang.String. Raw JSON-text value is used when writing a variable. |
| integer | Value is threaded as a java.lang.Integer. When writing, JSON number value is used as base for conversion, falls back to JSON text. |
| short | Value is threaded as a java.lang.Short. When writing, JSON number value is used as base for conversion, falls back to JSON text. |
| long | Value is threaded as a java.lang.Long. When writing, JSON number value is used as base for conversion, falls back to JSON text. |
| double | Value is threaded as a java.lang.Double. When writing, JSON number value is used as base for conversion, falls back to JSON text. |
| boolean | Value is threaded as a java.lang.Boolean. When writing, JSON boolean value is used for conversion. |
| date | Value is treated as a java.util.Date. When writing, the JSON text will be converted using ISO-8601 date format. |
| binary | Binary variable, treated as an array of bytes. The value attribute is null, the valueUrl contains an URL pointing to the raw binary stream. |
| serializable | Serialized representation of a Serializable Java-object. As with the binary type, the value attribute is null, the valueUrl contains an URL pointing to the raw binary stream. All serializable variables (which are not of any of the above types) will be exposed as a variable of this type. |
12.5.3 流程变量作用域
流程变量的作用域可以是一个流程实例(processInstance),或一个任务(task),或一个执行实例(execution)。
globa变量
流程变量的默认作用域是流程实例。当一个流程变量的作用域为流程实例时,可以称为 global 变量。
注意:
Global变量:userId(变量名)、zhangsan(变量值)
global 变量中变量名不允许重复,设置相同名称的变量,后设置的值会覆盖前设置的变量值。
local变量
任务和执行实例仅仅是针对一个任务和一个执行实例范围,范围没有流程实例大, 称为 local 变量。
Local 变量由于在不同的任务或不同的执行实例中,作用域互不影响,变量名可以相同没有影响。Local 变量名也可以和 global 变量名相同,没有影响。
12.5.4 流程变量的使用方法
可以在 assignee 处设置 UEL 表达式,表达式的值为任务的负责人,比如: ${assignee}, assignee 就是一个流程变量名称。
Activiti获取UEL表达式的值,即流程变量assignee的值 ,将assignee的值作为任务的负责人进行任务分配。
12.5.5 在连线上使用UEL表达式
可以在连线上设置UEL表达式,决定流程走向。比如:${price<10000}。price就是一个流程变量名称,uel表达式结果类型为布尔类型。
如果UEL表达式是true,要决定 流程执行走向。
12.5.6 启动实例设置流程变量
1 | /** * 启动流程实例,设置流程变量的值 */ |
需要注意,流程变量作用域是一个流程实例,流程变量使用Map存储,同一个流程实例设置变量map中key相同,后者覆盖前者。
12.5.7 通过当前任务设置流程变量
1 | String operateNow = DateHelper.getNowByNew(DateHelper.yyyyMMdd_hhmmss); |
关键代码在下面这一串:
1 | taskService |
第二个参数可以传递流程变量,如果Key在当前流程实例已经存在就会覆盖。
12.6 历史信息查询
每个参与者在完成当前节点的“活动”之后,都会在历史信息中留下记录。
1 | HistoricProcessInstanceQuery condition = historyService.createHistoricProcessInstanceQuery(); |
我们可以通过 “ act_hi_* “开头的的表阅读所有有关审批流的历史记录和操作信息。
| 表名 | 表注释 |
|---|---|
| act_hi_actinst | 历史节点表 |
| act_hi_attachment | 历史附件表 |
| act_hi_comment | 历史意见表 |
| act_hi_detail | 历史详情表,提供历史变量的查询 |
| act_hi_identitylink | 历史流程用户信息表 |
| act_hi_procinst | 历史流程实例表 |
| act_hi_taskinst | 历史任务实例表 |
| act_hi_varinst | 历史变量表 |
十三、学习参考资料汇总
13.1 技术选型部分
开源流程引擎哪个好,如何选型? - 知乎 (zhihu.com)
常见的工作流方案对比
13.2 activiti6.0在线流程设计器
activiti6.0在线流程设计器,可以从代码中找到对应的WEB版本Activity流程设计器。
juzhizhang/springboot2-activiti-design: activiti6.0在线流程设计器 (github.com)
13.3 最简洁的入门DEMO教程
# 21年最新版activiti7保姆教程
个人fork仓库: https://github.com/lazyTimes/ActivityStudy
13.4 Activity使用讲义资料
# Activiti工作流引擎进阶【收藏可做笔记系列】
13.5 工作流设计准则
企业工作流设计原则及多项目整合开发注意事项_敏捷开发_Marilyn_InfoQ写作社区
13.6 开源项目
# 推荐 2 个基于 SpringBoot 的工作流项目,有用!
# RuoYi-activiti
13.7 视频教程
activiti-5-流程初体验
对应笔记:# Activiti工作流引擎进阶【收藏可做笔记系列】
13.8 其他教程
SpringBoot系列——Activiti7工作流引擎
13.9 官方快速开始
# Quick Start Guide
# Activiti User Guide
13.10 参考PPT
https://slideplayer.com/slide/10527039/
13.11 Camunda
javascript - 常见的工作流方案对比 - 技术博客,人生所思 - SegmentFault 思否
十四、总结
- 工作流实践优于理论,概念比较复杂,但是有很多十分成熟并且稳定的框架。
- 本着“最少知识”的原则,工作流的业务编码应该尽可能的简化和易于理解。
- 流程图规划非常重要,每一个流程设计出错都有可能实际运行的时候无法进行。
- 工作流技术十分稳定,更新迭代非常缓慢。
- Talk is cheap. Show me your code。不要害怕未知领域。
十五、写在最后
授人以鱼不如授人以渔,本次内容是在用工作流实现实际生产业务之后补充整理而成,个人认为作为从零了解工作流入门开发的一个比较好的教程和参考,希望通过本次内容让读者可以了解到如何在碰到业务需要工作流的时候如何快速学习和上手开发。