【Spring】Spring 事务机制的个人总结
一、引言
Spring的事务机制虽然已经有非常多的资料介绍了,但是实际使用的时候还是常常栽坑里,相信这是大部分程序员的目前或者曾经的使用感受,所以这篇文章将会做一个完整的总结,用理论结合实际的代码实战的方式来弄懂Spring事务的机制到底应该如何使用以及内部是如何进行设计的。
在介绍正文之前,希望这篇教程不单单是能让读者避开Spring事务的陷阱,更多的是希望能够从Spring的事务设计上锻炼自己的架构思维,如果你一开始完全不懂,可以像我一样进行一比一复刻用在自己的开源工具或者项目上,不要管为什么这么设计,只管模仿再去思考,多想想自己用起来有什么便利性,然后再反推思考。
另外如果你完全不懂JDBC或者数据库的话,这篇文章可能就不太适合你看了,笔者也并不想浪费读者时间,可以看看下面这本老外写的JDBC入门文档,粗略翻了一下发现还是挺适合新手的,顺带磨练下英语阅读水平(实在不行还有谷歌娘兜底不是):
《jdbc》(简单粗暴的名字)
链接:https://pan.baidu.com/s/1COVisy9DyJR5uj9hsB4WoQ
提取码:x5tz
–来自百度网盘超级会员V7的分享
如果觉得文章写得不错,欢迎点赞收藏支持一波。
最好的资料
最好的博客永远是官方文档,建议了解Spring事务事务之前多读几遍:(版本 5.3.14)
https://docs.spring.io/spring-framework/docs/current/reference/html/data-access.html#spring-data-tier
另外官方文档在事务这一节的最后推荐了两个扩展资料,这里也一并推荐:
有关 Spring Framework 的事务支持的更多信息,请参阅:
Spring 中的分布式事务:分布式事务极具影响力的一篇文章,也是了解分布式事务一篇必读文,带和不带 XA 的一个 JavaWorld 演示,其中 Spring 的
David Syer将指导您了解 Spring 应用程序中分布式事务的七种模式,其中三种带 XA,其他四种不带。这里还找到一篇翻译:distributed-transactions-in-spring-with-and-without-xa.md
Java Transaction Design Strategies 是 InfoQ 提供的一本书,它对 Java 中的事务提供了节奏明快的介绍。 它还包含有关如何通过 Spring Framework 和 EJB3 配置和使用事务的并行示例。
书籍资源链接: https://pan.baidu.com/s/1Z1VdTZxO9LLrolXxKLa3LA 提取码: hads
二、事务介绍
首先我们需要大致了解什么是事务,一句话概括就是:一组操作要么全部一起执行,要么全部的不执行。
(1)事务特性(ACID )

事务通常有下面的四种特性:
- 一致性:一致性保证事务的操作前后数据都正确的。
- 原子性:事务是操作的最小单位,每一个事务要么全部成功,要么全部失败。
- 隔离性:隔离性需要保证不同的事务之间不会互相干扰。
- 持久性:事务提交之后数据将会永久生效并且保存。
这四种特性虽然简单但是真要记住确实有些难,为了方便记忆我们用一些案例进行联想记忆,也可以按照自己容易记忆的方式联想记忆:
首先,数据需要保证操作前的结果和操作后的结果一致,比如银行卡余额有1000元要往银行卡充值2000,充值完成之后我们看到的数据就是3000否则就还是1000元,所以一致性是首先需要保证的。
然后假设此时余额还是1000元,此时扣除500元,充值1000元,如果成功最后余额一定是1500元,需要保证两个操作同时完成,要么同时不完成,这就是原子性,原子性可以看做是保证多次连续操作的一致。
接下来是隔离性,隔离性比较好理解,你在ATM机器操作的时候如果进行充值,这中间的所有数据都是只有你可以见的,1000块钱存进去看到的结果一定是2000块钱而不是最后变成500块钱(不然这你绝对要报警了)。
最后事务一定是需要保证安全的,所以所有的事务只要成功就能永久生效,不受突然断电任何情况的影响,但是持久性依赖具体数据库的实现,当这是多数数据库的主要保证。
(2)并发事务的存在的问题
并发事务存在几个常见的问题,那就是脏读,不可重复读,幻读,丢失回滚(第一类事务丢失),丢失修改(第二类事务丢失),这里需要小心区分不可重复读和幻读这两种情况差异。
1. 脏读:最简单的话理解就是读到了其他事务没有提交的数据,也就是读到了未提交的数据,所以这个数据不管是否正确,其执行结果可能是不正确。
2. 不可重复读:不可重复读针对当前事务读取到其他事务修改或者删除的数据,比如当前事务之前读取数据行为20,但是后一次读取却变成了30,数据和之前不重复了,所以就是不可重复读,但是需要注意不可重复读并不是一个十分严重的问题,这取决于数据库所以这也是为什么有不少数据库不设置默认级别为这个级别其中一个原因。
- 幻读:幻读和不可重复读最大的区别是读到了其他事务提交的新增数据,就好像当前事务读取数据出现了幻觉,之前读取出来的值和后一次读出来的值的内容不一致。
- 丢失修改(第二类事务丢失):有一种情况丢失修改,丢失修改指的是两个事务同时提交事务覆盖同一份数据的情况,不管事务A成功还是事务B成功,最后总会有一方修改的数据是失效的。
- 丢失回滚(第一类事务丢失):丢失回滚指A事务提交了,但是B事务事务回滚了,当A提交成功但是B因为回滚事务回滚了A的数据,这时候对于A来说事务就算是丢失了。
(3)事务的隔离级别
事务的隔离级别就是来解决并发事务问题的,需要注意的是下面介绍的内容并不是所有的数据库都支持(也可能支持但是只支持一部分),如果无特殊说明默认为Mysql。
- READ UNCOMMITTED(读未提交):对应脏读的模式,会读到其他事务没有提交的数据,几乎无数据安全和可靠性的保证。
- READ COMMITTED(读已提交):事务会读取已提交的数据,也是大多数数据库的默认隔离级别。但是读到已提交的数据存在读到其他事务提交的新增数据的情况,所以会存在可重复读的情况。
- PEPEATABLE READ(可重复读):这个级别是MySQL的默认隔离级别,它解决了脏读的问题,同时也保证了同一个事务多次读取同样的记录是一致的,但这个级别还是会出现幻读的情况。幻读是指当一个事务A读取某一个范围的数据时,另一个事务B在这个范围插入行,A事务再次读取这个范围的数据时,会产生幻行。特别说明:InnoDB和XtraDB存储引擎通过多版本并发控制(MVCC,Multiversion Concurrency Control)解决了幻读问题,它使用间隙锁(next-key locking)锁定查询涉及的行和索引中的间隙,防止幻影行的插入。
- SERIALIZABLE(可串行化):这个事务是最高的隔离级别,它强制事务串行执行,避免了幻读问题。简单来说,SERIALIZABLE会在读取的每一行数据上都加锁,所以可能会导致大量的超时和锁竞争
(4)设置和回滚到保存点
注意保存点和事务的隔离级别一样,依赖于具体的数据库是否支持。保存点使用方式是在当前事务中通过Connection.setSavepoint设置一个Savepoint对象,利用Connection.rollback方法进行回滚,同时接受一个Savepoint参数。可以理解为一个存档,存档之后,可以回滚到指定存档点,这里用一个网上的sql案例简单理解,下面的案例重点关注:ROLLBACK TO SAVEPOINT s1;和SAVEPOINT s1;和SAVEPOINT s2;这几条语句:
1 | 回滚事务到保存点。 |
三、Spring事务介绍
(1)Spring事务是啥?
Spring的事务可以看做是在spring对于不同数据库的操作细节的一种封装和掩盖,通过三个核心的组件来完成整个事务的控制,这三个组件分别是:
- PlatformTransactionManager: (平台)事务管理器
- TransactionDefinition: 事务定义信息(事务隔离级别、传播行为、超时、只读、回滚规则)
- TransactionStatus: 事务运行状态
spring事务在进行操作的时候通过自定义了七种不同的事务等级来完成事务提交回滚等一系列的操作,这里先卖个关子。
(2)事务设计
我们稍微扩展介绍一下上面三个组件的内容:
- PlatformTransactionManager: (平台)事务管理器,定义了事务的通用接口,最主要的实现抽象类为:AbstractPlatformTransactionManager,如前面所说,他定了事务操作的模板方法,由子类实现具体的事务细节,比如回滚,提交事务,设置参数等操作。
- TransactionDefinition: 事务定义信息,可以看作是一个事连接务的属性和配置,事务属性分为下面五种:
- 事务隔离级别:事务隔离几倍并不是所有的数据库都支持,并且部分数据库由于存储引擎的不同也可能不支持。
- 传播行为:传播行为有七种,默认级别为:PROPAGATION_REQUIRED。
- 事务超时:指一个事务所允许执行的最长时间,如果超过该时间限制但事务还没有完成,则自动回滚事务。
- 回滚规则:规定了当前的事务会在什么情况下进行回滚,默认情况是按照运行时异常进行回滚,也可以设置指定某些异常不进行回滚,但是需要注意指定异常类必须是Throwable的子类。
- 是否只读:事务的只读属性是指对事务性资源进行只读操作或者是读写操作
- TransactionStatus: 事务运行状态,可以看做是一个新的事务对象,此接口包含了下面的内容
1 | public interface TransactionStatus{ |
(3)实现形式
Spring事务有两种实现形式,关于实现形式将会在后文进行详细的讲解:
- 编程式模式:硬编码,也可以称之为手动模式,其实可以看作对于jdbc做了一层封装,一般使用 TransactionTemplate 模板对象进行事务的相关操作。
- 声明式模式:特点是使用@Transactional 注解完成切面的事务注入。其底层使用的是aop和动态代理。
spring的事务是对于aop和动态代理的设计模式的教科书实现,如果对于Spring源代码比较棘手的可以从Spring的事务开始了解,如果看不懂那就需要补补aop和动态代理的功课了。
下面我们分别来看看编程式事务和声明式事务的实现方式。
(4)事务的传播级别
Spring的事务传播级别主要是下面的七种,关于事务传播的部分细节会在声明式事务的“理解事务传播级别”介绍,同时实战部分会通过一些简单的案例来看一下不同传播级别的效果,这里可以先大致浏览一遍,关于事务传播的具体案例操作将会在实战部分进行详细的阐述。
| 特点 | 传播级别 | 说明 |
|---|---|---|
| 支持当前事务的情况: | TransactionDefinition.PROPAGATION_REQUIRED | 如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务。 |
| 支持当前事务的情况: | TransactionDefinition.PROPAGATION_SUPPORTS | 如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务的方式继续运行。 |
| 支持当前事务的情况: | TransactionDefinition.PROPAGATION_MANDATORY | 如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常。(mandatory:强制性) |
| 不支持当前事务的情况: | TransactionDefinition.PROPAGATION_REQUIRES_NEW | 创建一个新的事务,如果当前存在事务,则把当前事务挂起。 |
| 不支持当前事务的情况: | TransactionDefinition.PROPAGATION_NOT_SUPPORTED | 以非事务方式运行,如果当前存在事务,则把当前事务挂起。 |
| 不支持当前事务的情况: | TransactionDefinition.PROPAGATION_NEVER | 以非事务方式运行,如果当前存在事务,则抛出异常。 |
| 其他情况 | TransactionDefinition.PROPAGATION_NESTED | 如果当前存在事务,则创建一个事务作为当前事务的嵌套事务来运行;如果当前没有事务,则该取值等价于TransactionDefinition.PROPAGATION_REQUIRED。 |
(5)Spring事务和传统的区别
Spring事务和传统事务区别如下:
- 不需要捕获SQLException,Spring会自动捕获异常并且转为相关的RuntimeException并且进行回滚。
- 通过Spring事务管理,可以极大化的减少配置,并且可以将事务委托为Spring进行管理。
- 传统事务会产生大量的侵入式代码,并且切换数据库对系统也是毁灭性打击。
(6)设计思路(个人理解)
设计思路部分是个人看完了Spring事务之后的一些思考补充,可以跳过。
上面简单的介绍了spring事务的大致特点,以及介绍了传统事务的特性以及并发事务的问题。
下面来看一下Spring是如何设计自己的事务的,这里读者可以停留下来思考一下,如果你是Spring事务的设计者,你会如何设计?这有利于你更深入的了解和巩固关于Spring事务的相关知识,这里大致说下个人的思考思路:
首先操作层面来看根据事务的特性,由于事务是多个连续的原子操作,所以肯定需要开启和提交事务这两个步骤。这是第一点。
然后我们在中途肯定需要对事务设置一些自己设置的属性,并且通过这些属性控制事务是否是只读的,不允许修改,控制是否允许使用事务等等,这是第二点。
我们需要考虑不用的数据库要如何兼容,也就是数据源要如何进行管理? 这时候肯定会想肯定分发给不同的数据源通过抽象事务管理器进行控制,同时会发现无论是回滚还是提交事务这些方法都是通用的,只是在数据库供应商底层的实现方式不同的而已,所以这里可以使用策略模式把事务的操作分发给具体的数据源实现,这是第三点。
有共同的方法所以需要使用 模板方法的模式控制抽象和模板方法的不同细节,提高代码复用性,这是第四点,模板方法并不算特别难。
如何实现嵌套事务的回滚,多线程访问的时候如何保持线程的隔离呢?这里我们最常想到的是ThreadLoacal,但是TheadLocal本身有点弱,我们是不是应该封装一下?这是第五点
所以最后我们从最顶层的抽象来看,完成一个事务其实只需要三个操作:1. 根据配置获取事务,2.执行操作,3. 提交或者回滚事务。其实归根结底,一个事务的底层抽象就是这三个动作,我们所有的事务设计都是围绕这三步来展开,这是最后一点,但是确实最复杂和抽象的。
看到这里你当然会说Spring的事务设计肯定怎么会才这么点,肯定比这个复杂多了,真正设计的时候肯定还会出现新的问题,并且有更加完善的架构。
我只能说在学习源码之前,脑子一定要有一套自己的思路,哪怕是错的也无所谓,静下心来看看设计者是如何思考的对照自己的思路进行纠正,否则很容易会被代码细节牵着走。
四、编程式事务
编程式事务仅仅作为声明式事务的底层实现了解,现在基本不会用直接使用编程式事务,我们需要重点了解的部分在于核心的事务组件事务管理器。
(1)实现方式
为了理解事务管理器,我们不得不啰嗦一下编程式事务的实现和使用方式,在代码中通常有下面两种实现方式:
- 第一种:使用TransactionTemplate的模板类进行相关操作。
- 第二种:使用PlatformTransactionManager 控制事务的处理。
那么哪一种方式更常用的?
其实两种方式都什么人用(嘿嘿,被我带进去了吧),因为声明式事务和他们相比方便一万倍,但是编程式事务是声明式事务的实现基础,所以我们不得静下心来不好好聊聊他是如何实现的。
(2)配置方式
配置方式一般不怎么需要记忆,但是有时候会有奇葩的面试官会问这个东西看你有没有实际用过,其实多数情况都是不熟悉,所以这里列一个大致的模板:
配置方式只有很老的项目才会这么干,强烈不建议去使用这种方式做配置。
1 | <!-- 配置c3po连接池 --> |
小贴士:注意和声明式的配置方式区分。
(3)PlatformTransactionManager
集成方式
这里最快的处理方式是构建一个Spring boot web项目进行引入和直接使用,因为Spring在4.2版本之后SpringBoot项目可以不加任何注解添加事务支持(默认配置),如果不知道如何操作,可以参考下面的步骤:
快速搭建一个SpringBoot项目:
Spring Boot快速搭建项目 - 知乎 (zhihu.com)
1 | <!-- MYSQL --> |
为了观察事务的操作,这里构建一张实验表:
1 | CREATE TABLE `admin` ( |
快速编写一个单元测试来验证事务是否生效:
1 | // 单元测试 |
上面的代码看起来和我们编写模板代码操作没什么区别,其实spring 为我们做好了不少的准备和繁琐的基础工作,下面我们对spring事务的核心代码分析一波。
源码解析
下面是从网络上找到的一张关于编程式事务的接口图,比较形象的说明了Spring事务的整体设计,后续声明式事务和各种模板操作类其实都是基于下面这个结构的扩展:
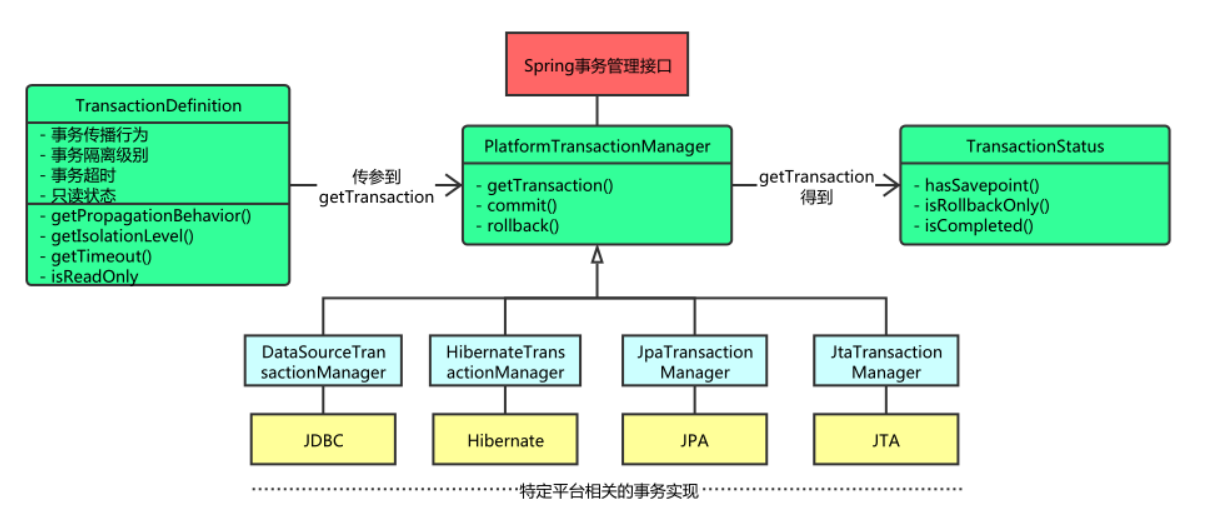
PlatformTransactionManager 事务管理器
首先我们来看下事务管理器接口的结构图,这里需要注意的是TransactionManager 这个接口是一个标记接口,标记为Spring的事务管理接口,其他所有的对象要介入spring的事务必须实现此标记接口(当然通常是实现PlatformTransactionManager接口,或者扩展抽象的默认事务管理器实现)。
提示:不同spring版本类图可能会有区别。

下面是PlatformTransactionManager 事务管理器接口,也是spring事务管理机制的核心接口。
1 | public interface PlatformTransactionManager extends TransactionManager { |
从类图可以看到,这里存在许多的实现类,这里我们挑几个比较常见的类进行介绍:
- JtaTransactionManager :jta事务管理器,继承自一个抽象的事务管理实现,如果你需要使用分布式的事务管理进行操作,可以使用这个事务管理器,当然多数情况它派不上用场。
小贴士:
JPA是啥玩意?JPA本身是一个规范,基于此规范实现的产品有:Hibernate, Eclipselink, Toplink, Spring Data JPA, etc等,其中最典型的实现是ORM的鼻祖Hibernate。如果想要更多了解JPA,可以看看这篇客:什么是JPA?Java Persistence API简介。
JTA又是啥玩意?注意不要和JPA搞混了,JTA指的是允许应用程序执行分布式事务管理 ,在两个或多个网络计算机资源上访问并且更新数据,JDBC驱动程序的加入JTA支持极大地增强了数据访问能力,如果对于JTA细节和规范了解,可以看文章最开头的博客,这里不再过多介绍。
- DataSourceTransactionManager :如果使用了数据源进行操作,比如使用了jdbcTemplate,mybatis这种框架的时候需要使用此事务管理器。
- CciLocalTransactionManager :CCI (Common Client Interface)是应用程序用来与连接器交互并与EIS通信的接口。同样还为本地事务划界提供了API,Spring提供CCI的支持主要是为了同价通用的资源和事务管理工具,但是其实用的十分少。
Spring是如何获取事务的?
如何让Spring获取不同数据源的事务的呢?核心在于事务管理器的一个默认实现AbstractPlatformTransactionManager 类,默认实现了获取事务的抽象逻辑,将具体的获取逻辑分发到,下面为方法org.springframework.transaction.support.AbstractPlatformTransactionManager#getTransaction方法的执行流程:
- 检查是否传递事务属性TransactionDefinition,如果没有则使用默认配置。
- 以DataSourceTransactionManager数据源为例,通过
DataSourceTransactionManager#doGetTransaction()方法,构建一个事务对象,同时设置相关的属性,通过TransactionSynchronizationManager#getResource() 同步获取ConnectionHolder(连接器)对象 ,TransactionSynchronizationManager.getResource()方法比较关键,Spring将连接器统一配置在一个NamedThreadLocal的全局线程共享资源当中,同时由于key有可能是一个动态的代理对象,所以key的获取会尝试解包动态代理来获取实际目标对象或者直接使用透明代理两种形式,当NamedThreadLocal中配置的连接器被获取到则进行返回(此时会额外检查当前线程是否还存在连接器存在于全局变量中,如果不存在则移除当前的线程资源释放内存)。 - 之后到代码逻辑较为简单,通过事务属性对象TransactionDefinition 进行事务的传播机制判断,然后便是熟悉的开启事务和执行sql以及返回结果等等一系列操作的模板代码,这里结合了策略和模板的设计模式,代码都比较好懂。
- 在提交事务最后有一步比较特殊,在事务提交之后如果发现当前的连接是一个新的连接,则会调用TransactionSynchronizationManager#bindResource 将当前的连接器进行绑定,这样可以保证同一线程内传播的是同一个事务。
下面是获取事务的抽象方法,下面是关于获取事务方法的细节:
1 |
|
最后我们把上面的描述简化为伪代码的形式进行解释:
DataSource 事务对象,代表一个ConnectionHolder,用作 DataSourceTransactionManager 的事务对象。
小知识:如果Springboot没有配置数据源,默认会使用一个叫做 HikariPool的数据源,这个配置在2.0之后为默认值。
1 | // 使用threadlocal 绑定一个全局共享的全局变量 |
再一次强调整个spring事务的核心部分是AbstractPlatformTransactionManager,它定义了spring获取事务的绝大多数的公用逻辑,而具体关于获取,提交,回滚等等细节则需要由子类的具体事务管理器进行实现。
最后,编程式事务在以前使用还是十分常见的(因为也没有别的工具),只不过spring推出注解式的声明式事务太好用了才逐渐淡出了视野,但是学习这些内容有助于更好的理解spring是如何实现注解式事务的,因为核心实现还是通过事务管理器来完成。
小贴士:看到这里建议休息一下整理一下思路,出去倒杯水回来慢慢接着看。
(4)TransactionTemplate
现在我们来看下第二种方式TransactionTemplate,第二种方式其实是对于纯手动形式的进一步封装,我们可以发现事务管理器的模板代码其实可以省出开启事务和提交事务和回滚的步骤,这些步骤依然会出现大量的模板代码,并且客户端也不喜欢手动开启和关闭事务,Spring针对此进行改进出现了TransactionTemplate 事务的模板方法类,下面我们根据一个实际的运行代码来讲解一下它的用法:
使用方式
1 | public void update(){ |
可以看到,使用TransactionTemplate 的方式缩减了很多代码,我们不需要关心事务开启和提交的细节,只需要关心事务的处理操作即可。
源码解析
下面按照同样源码来解释一下这个操作的大致处理流程,这里可能会感觉我擦这么神奇,不用事务管理器,也不需要设置属性了,那要怎么设置属性? 其实只不过是把所有的工作交给TransactionTemplate 去做了,为了验证我们可以对比DefaultTransactionDefinition 和TransactionTemplate 中的方法,可以发现他们的方法基本一致。(其实TransactionTemplate 就是继承了DefaultTransactionDefinition )。多数情况下我们通过@Configuration注入Bean的方式,为全局的TransactionTemplate设置一些默认配置。
其实从个人角度来看这里使用继承的方式实现spring相关的事务配置并不是很好,而是使用一个配置构造器完成配置的中转或者使用组合TransactionDefinition的方式比较恰当。
DefaultTransactionDefinition :

TransactionTemplate :

下面我们再来看下它的类图,可以看到他在扩展事务属性类的基础上实现了新的接口:TransactionOpration,这也是一个关键接口,另外TransactionTemplate 可以进行事务的各种操作的原因是它内部组合了PlatformTransactionManager的对象,所以所有的事务管理实际上还是通过PlatformTransactionManager对象进行管理的,换汤不换药:

下面是TransactionOperations的方法签名,注意Spring5对于这个接口做过改动和扩展,旧版本的包可能内容不同:
1 | class TransactionOperations{ |
再来看一下TransactionTemplate ,代码相对简单,相信读者只要了解原始的事务操作模板方法就可以看懂:
1 |
|
了解带返回值execute方法之后,我们来了解一下不带返回值的方法executeWithoutResult(),它的实现代码就更为简洁了,从最新版本的代码可以看到其实后续的版本有做函数式表达式重构,所以如果jdk版本比较低可能出现不兼容的情况:
1 | /** |
(5)小结
最后我们来小结一波上面的内容,这一节开始我们了解了传统编程式事务的操作,可以看到虽然Spring已经封装开启和关闭事务的细节,也封装了关于JDBC操作的模板代码,但是我们如果使用编程式事务还是会产生大量的侵入式代码,这也不符合单一职责的原则。
编程式事务实现的几个特点:
- 事务的传播机制基于
AbstractPlatformTransactionManager#getTransaction()方法,通过不同的事务传播等级设置进行事务的管理。 - 为了保证同一个线程使用的连接资源的一致性,Spring使用了
ThreadLocal作为全局共享变量的存储,实现线程之间的事务隔离,同时防止并发事务的问题。 - TransactionTemplate 可以看作是对于
PlatformTransactionManager事务管理器的二次封装并且扩展了回调式的事务操作。
再次强调花费大量篇幅介绍并不是说推荐大家使用,而是使用编程式事务更有助于我们了解声明式事务的使用,下面我们来了解一下声明式事务的使用。
五、声明式事务
声明式事务的使用就十分简单易懂了,就是我们熟悉的@Transactional注解,做到了不侵入的添加和去除事务管理支持,声明式事务的实现使用了AOP,本质其实就是在执行被注解的事务方法前进行拦截操作,声明式事务有如下的优缺点:
优点: 简单快速注入事务,无需改动任何业务代码。
缺点:和spring aop的缺点一致,只能针对方法级别进行事务控制 ,并且只能通过Spring代理对象才能使用声明式事务,如果自己new对象接入事务这样做是不会生效的(切记),具有一定的局限性。
(1)如何使用?
不同的项目配置方式不同,需要针对具体的项目环境使用,目前主流是使用微服务,这里其实更加推荐使用@Bean类配置的方式注入事务管理的相关功能,比如配置事务管理器。如果你是SpringBoot并且版本比较新,那就非常简单了,直接加注解使用即可。
小贴士:如果你使用的是springboot2.0之后的项目,并且如果在依赖里面有spring-data-*或者 spring-tx事务有关的依赖,则默认会开启声明式事务。
1 |
|
但是如果Spring Boot的版本比较低或者一些比较旧的项目,则需要手动开启一下:
1 |
|
顺带一提,如果我们想要在注解的方法里面使用编程式的TransactionAspectSupport类里面的方法手动回滚事务,可以使用下面的方法进行回滚(但是建议不要这么使用):
1 | public void createCourseDefaultRatingProgramatic(Course course) { |
@Transactional注解介绍
我们来看一下关于@Tralsactional拥有哪些配置:
- value:别名,指定使用的事务管理器的Bean
- transactionManager:指定事务的限定符值。可用于确定目标事务管理器,匹配特定 TransactionManager bean 定义的限定符值(或 bean 名称)。
- propagation:用于指定事务的传播级别,核心和常用属性
- isolation:事务的隔离级别,如果没有特殊指定,则默认按照数据库的级别
- timeout:代表当前事务的超时时间(以秒为单位),默认为底层事务系统的默认超时时间(注意代码给了1秒的默认值)。专为与
Propagation.REQUIRED或Propagation.REQUIRES_NEW一起使用而设计,需要注意的是仅适用于新启动的事务。 - readOnly:默认为false,如果设置为true,则只运行执行非update操作,如果碰到Update的操作反而会抛出异常。此配置方式有利于提高事务执行效率,如果不需要update相关事务,可以将此设置为true。
- rollbackFor:根据指定的Class异常类进行回滚,如果没有设置,默认为运行时异常,但是需要注意必须是able的子类。
- rollbackForClassName:必须是able的子类完全限定类名的子字符串,目前不支持通配符。例如,
ServletException的值将匹配javax.servlet.ServletException及其子类。 - noRollbackFor:和rollbackFor刚好相反。
- noRollbackForClassName:和rollbackForClassName刚好相反。
如果在多个地方使用了相同的注解,但是我们又不想总是复制粘贴大量的重复注解配置的时候,有一种方式是使用自定义注解的方式,这里简单了解即可。
1 | ({ElementType.METHOD, ElementType.TYPE}) |
监听器绑定事件
监听器事务绑定事件需要Spring4.2以上才支持,需要Spring4.2以上才支持,需要Spring4.2以上才支持,很重要,所以特意强调三遍。通常情况下使用@EventListener注解注册常规事件侦听器。如果需要将其绑定到事务也可以用@TransactionalEventListener,这样可以实现监听器的事务操作。
下面是官方提供的案例:
1 |
|
@TransactionalEventListener这个注解有个比较特殊的熟悉就是phase这个属性:
1 | TransactionPhase phase() default TransactionPhase.AFTER_COMMIT; |
这个属性支持事务绑定到指定的阶段,包含下面几个级别:
BEFORE_COMMIT
AFTER_COMMIT(默认)
AFTER_ROLLBACK
AFTER_COMPLETION
监听器使用事务的场景个人目前没有碰到,所以这里仅仅根据官方文档简单翻译介绍了一番。
JTA的集成
如果需要集成JTA,那么配置文件不能使用某一特定的资源,而是需要配合JNDI同时配合JtaTransactionManager事务管理器进行全局的事务管理,下面我们来看一下配置的方式。
1 |
|
和 JPA/Hibernate 的集成
注意不要眼花了,上节说的是JTA,这一节讲述的是ORM相关的JPA,关于他们的概念这里不再赘述,如果你的数据库使用的是JPA,使用声明式事务可以避免一个比较核心的问题,下面是代码的案例:
1 | public class UserService { |
这样的代码会出现下面两个严重的问题:
- Hibernate 不知道 Spring 的
@Transactional注释。 - Spring 的
@Transactional对 Hibernate 的事务一无所知。
如果我们使用声明式事务就不会出现上面的情况,Spring会在事务启动的时候,会自动切换到HibernateTransactionManager 或JpaTransactionManager(如果通过 JPA使用 Hibernate),HibernateTransactionManager 会确保这两种会话形式合并为同一个,这里也体现了一个非常常见的适配器模式的思路。
响应式事务
响应式事务目前依然属于一个比较新颖的东西,也是Spring的未来主攻方向,极限编程的思想比较有意思,但是从目前环境来看使用频率比较低,所以此文就不再进行扩展讲述。
还有更多的集成和使用方式可以参阅官方的文档,文章篇幅有限不能面面俱到。
(2)配置方式
声明式事务的配置方式有四种,其中最常使用的是注解的方式进行事务处理。
- TransactionInterceptor :使用TransactionInterceptor 拦截器的方式,这种方式虽然不推荐使用,但是对于理解spring事务是有一定帮助的,感兴趣可以阅读一下这个类。
- 基于AspectJ的XML方式(<tx>和<aop>标签):不需要改动类,在XML文件中配置好即可,比如下面提供了一个事务的配置模板,同样是基于切面aop进行拦截增加事务的。
1 | <!-- 事务管理器 --> |
- 基于事务代理工厂的Bean进行配置:比如下面配置了一个代理工厂的Bean - TransactionProxyFactoryBean,这种方式在以前是Spring推荐的方式,配置方式也比较古老,并且早在Spring2.0就不推荐使用了。
1 | ..... |
- 最后就是常见使用@Transactional注解的方式进行配置,如果SpringBoot可以配合
@EnableTransactionManagement直接引入事务,@Transactional可以配置在某个类上,也可以配置在方法上,但是同样依赖AOP同时只支持方法级的事务控制而不支持代码块级的事务控制。
1 | (isolation=Isolation.DEFAULT,propagation=Propagation.REQUIRED,rollbackFor=BuyStockException.class) |
(3)理解事务传播级别
在上文我们提到了通过事务属性对象TransactionDefinition 进行事务的传播机制判断,这里我们接着来看一下事务的传播机制的类型,事务的传播级别在前文已经提到过了这里我们再回顾一下:
| 特点 | 传播级别 | 说明 |
|---|---|---|
| 支持当前事务的情况: | TransactionDefinition.PROPAGATION_REQUIRED | 如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务。 |
| 支持当前事务的情况: | TransactionDefinition.PROPAGATION_SUPPORTS | 如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务的方式继续运行。 |
| 支持当前事务的情况: | TransactionDefinition.PROPAGATION_MANDATORY | 如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常。(mandatory:强制性) |
| 不支持当前事务的情况: | TransactionDefinition.PROPAGATION_REQUIRES_NEW | 创建一个新的事务,如果当前存在事务,则把当前事务挂起。 |
| 不支持当前事务的情况: | TransactionDefinition.PROPAGATION_NOT_SUPPORTED | 以非事务方式运行,如果当前存在事务,则把当前事务挂起。 |
| 不支持当前事务的情况: | TransactionDefinition.PROPAGATION_NEVER | 以非事务方式运行,如果当前存在事务,则抛出异常。 |
| 其他情况 | TransactionDefinition.PROPAGATION_NESTED | 如果当前存在事务,则创建一个事务作为当前事务的嵌套事务来运行;如果当前没有事务,则该取值等价于TransactionDefinition.PROPAGATION_REQUIRED。 |
理解 PROPAGATION_REQUIRED:
PROPAGATION_REQUIRED 如果不存在事务,就新建事务,如果出现嵌套的事务就会参与外层的事务而不会再新建。 这是同一线程内公共调用的十分方便的默认设置(例如委托给多个存储库方法的服务外观,其中所有底层资源都必须参与服务级别事务),同时基本能对付绝大多数的业务系统。
讨论:这里讨论一下Spring官方文档和源码说明的“冲突”,默认情况下,如果出现嵌套事务,会默认采用已有事务,这样针对内部新建的事务会默认忽略事务隔离级别、超时值或只读标志(如果有)。 如果希望在内部事务采用不同隔离级别时候被外部事务拒绝并且抛出异常,可以考虑将事务管理器上的 validateExistingTransactions 标志切换为 true。
其实这种说法和源代码来看其实不是特别吻合,实际上如果设置validateExistingTransactions为false,会发现事务将继续执行,即使隔离级别与请求的不同,会按照外部事务的优先级执行,这样其实就导致了事务配置只看一份文件的情况,具体可以参考下面这一段代码:
2
3
4
5
6
7
8
9
10
11
12
13
if (definition.getIsolationLevel() != TransactionDefinition.ISOLATION_DEFAULT) {
I
}
// 如果设置了只读但是当前事务没有只读,则抛出异常
if (!definition.isReadOnly()) {
if (TransactionSynchronizationManager.isCurrentTransactionReadOnly()) {
throw new IllegalTransactionStateException("Participating transaction with definition [" +
definition + "] is not marked as read-only but existing transaction is");
}
}
}
// 没有则同步构建一个空事务
最后再补一张官方的图:

理解 PROPAGATION_REQUIRES_NEW:
PROPAGATION_REQUIRES_NEW与 相比PROPAGATION_REQUIRED,始终为每个受影响的事务范围使用独立的事务,从不参与外部范围的现有事务。每一个事务资源都是独立的,因此可以独立提交或回滚,外部事务同样不受内部事务回滚状态的影响,内部事务的锁在完成后立即释放。这样一个独立的内部事务也可以声明自己的隔离级别、超时和只读设置,而不继承外部事务的特性。

理解 PROPAGATION_NESTED:
PROPAGATION_NESTED使用了保存点的方式。嵌套事务意味着可以实现部分事务的回滚,但是嵌套的内部事务不会影响外部事务的执行。注意这个设置仅适用于 JDBC 资源事务,源码里面也有解释,可以参阅 Spring 的DataSourceTransactionManager。
(3)源码解析
声明式事务要比编程式事务复杂不少,这一部分的代码不会深入讲解AOP的部分,同时由于使用了SpringBoot自动注入的特性这里也尽量不过度深入讲述,下面我们从两个部分来分析声明式式的内部操作流程:
- 自动配置注入
- 注解拦截解析
自动配置注入
首先来啃啃第一块大骨头。我们先从一个SpringApplication的注解开始开始,上文提到过SpringBoot新版本中如果碰到事务的相关依赖,会自动接入Spring的事务控制,我们可以通过注解@EnableTransaction进行排查,发现内部存在一个@EnableAutoConfiguration,Spring启动的时候,会扫描源代码包根路径下面一个叫做spring.factories的文件,在大约127行位置有一个org.springframework.boot.autoconfigure.transaction.TransactionAutoConfiguration的配置,在这个配置下面中有一个TransactionAutoConfiguration的配置,当容器启动的时候会自动根据配置扫描相关的包载入相关的bean。最后从事务自动注入的注解内,可以从下面的截图看到一些熟悉的影子,这里不再重复解释。

接着我们再回过头看一下@EnableTransaction注解内部的内容,这里使用了@Import注入了TransactionManagementConfigurationSelector,这个类的作用是根据导入 @Configuration 类上的 EnableTransactionManagement.mode() 的值选择应使用 AbstractTransactionManagementConfiguration 的哪个实现。
1 | (TransactionManagementConfigurationSelector.class) |
我们可以从下面的代码看到,这里提供了两种代理方式,一种是根据JDK的代理模式,另一种是根据AspectJ的代理默认,Spring在默认情况下会优先选择JDK的代理,如果没有才会选择AspectJ的代理(总觉得Spring作者对于Aop总有一种遗憾和执念),如果读者想知道在哪里配置的,可以看看org.springframework.scheduling.annotation.EnableAsync#mode中存在一个默认的JDK代理配置,在下面的代码中可以到走JDK的代理注入了两个类AutoProxyRegistrar.class和ProxyTransactionManagementConfiguration.class 。
1 | AdviceMode mode() default AdviceMode.PROXY; |
AutoProxyRegistrar.class:
这个类直译就是自动代理注册器,它是一个后置处理器,负责给容器中注册一个InfrastructureAdvisorAutoProxyCreator,InfrastructureAdvisorAutoProxyCreator,利用后置处理器机制在对象创建以后,对对象进行包装,返回一个代理对象(增强器),代理对象执行方法,利用拦截器链进行调用,下面是关于注册器的部分代码:
1 |
|
接着进入方法AopConfigUtils.registerAutoProxyCreatorIfNecessary(registry);的内部实现org.springframework.aop.config.AopConfigUtils#registerOrEscalateApcAsRequired方法,AopConfigUtils这个工具类为AOP动态代理类创建器的主要负责工具:
1 |
|
我们知道了InfrastructureAdvisorAutoProxyCreator这个类是如何集成到IOC容器之后,发现这个类属于一个下属的实现子类,我们通过继承链向上找到父类:AbstractAutoProxyCreator,这个类名字翻译过来是抽象自动代理创建器,他的作用是如果 bean 被子类标识为代理,则使用配置的拦截器创建代理,这里可以看作代理的生产者和执行者之间的解耦,核心代码如下部分:

1 |
|
内部的代码逻辑就不过多展开了,总结InfrastructureAdvisorAutoProxyCreator作用就是:利用后置处理器机制在对象创建以后,对对象进行包装,返回一个代理对象(增强器),代理对象执行方法,最后利用拦截器链进行调用。
Tips:这部分代码需要对于Spring IOC和AOP的实现底层掌握比较牢固才能彻底理解,建议阅读卡死之后不要死犟,可以补补其他的模块实现之后再来啃下事务是如何集成到IOC和AOP的。
注解拦截解析
我们大致了解了自动配置自动配置是如何注入到Spring IOC之后,我们接着来看下Spring是如何实现事务的注解拦截解析的,也就是@Transactional注解的解析过程,上文说过,注解拦截器调用这里不再啰嗦,这里回到前文的对象ProxyTransactionManagementConfiguration也就是代理配置管理器开始,这里读者可能有疑问这个类那里突然冒出来的,这里给个提示:
1 | case PROXY: |
下面截取了部分代码:
1 | (name = TransactionManagementConfigUtils.TRANSACTION_ADVISOR_BEAN_NAME) |
接着我们看一下被注入的属性:TransactionAttributeSource,这个类用于处理注解的属性和相关内容,也是注解解析器,这个类拥有很多的实现子类,因为是注解解析器,这里我们直接看:

部分代码如下:
1 | public AnnotationTransactionAttributeSource(boolean publicMethodsOnly) { |
上面的代码比较好理解,就是对于注解的内部进行解析和封装。接着我们看一下是拦截器TransactionAspectSupport,这个拦截器实现了MethodInterceptor接口,标志为他是一个方法的拦截器,核心方法是内部的invoke()方法。

内部的invoke()方法内容如下:
1 |
|
接着进入核心的适配方法invokeWithinTransaction,代码比较多,这里截取部分代码介绍:
1 |
|
六、Spring事务实战
(1)介绍
为了防止读者误解,这里提前介绍一下本次实验操作的Spring版本和数据库版本:
- spring-boot:5.2.8
- mysql:5.7
下面我们进入实际部分,实战部分主要针对事务比较常见的使用:
- 事务不生效的一些“坑”,以及如何规避或者如何解决。
- 不同事务的传播机制在实际代码中的效果。
- 大事务的问题,以及相关的处理方法。
(2)事务不生效的一些坑
首先来看一下事务不生效的一些坑,同样我们一开始需要构建一张表作为测试:
1 | CREATE TABLE `t_trans_test` ( |
这里构建两条数据,分别表示两个人的余额:
1 | INSERT INTO `transaction_tb`.`t_trans_test` (`id`, `name`, `amount`) VALUES (1, '用户A', 1000); |
1. 非事务方法调用事务方法
如果在一个非事务的方法内部调用一个事务的方法,无论是否加注解,会发现抛出异常的时候会事务不回滚的情况,也是最常见的情况,如下代码所描述的,假设我们用A给B转钱,A-100和B+100,如果在B中加入事务注解,但是A没有加,则会发现A的操作是没有回滚的:
提示:这样的操作仅作演示,工作中扣款和充值绝对不是这样操作的。
1 | // 随机异常触发flag |
解决方式:
解决方式有两种,一种是我们在事务A的上面增加一个回滚的注解,这个无需过多解释,但是如果有时候我们想让事务在一个内部的方法里面让事务的范围锁定在想要的方法。
最常见的一种方式是“注入自己”,还有一种方式是先允许获取Spring的代理对象,然后通过获取Spring的代理对象完成操作。
此外在spring5.0之后的版本又增加了新的获取方式,比如spring-test有AopTestUtils来获取,下面我们汇总一下这些方法,如果读者感兴趣可以实际验证一遍:
- 注入“自己”。丑陋又笨,但是又快又有效。
- 使用`AopContext.currentProxy()``。
- 注入
ApplicationContext,获取代理对象。
1 |
|
还有更多方法欢迎讨论。
2. 抛出不被回滚的异常
这也是非常常见的情况,所以很多时候建议使用注解就加上一个rollBackFor,哪怕使用默认的规则也建议标记一下,因为很多时候小小的疏忽就是埋雷。
比如下面的方法虽然抛出异常,但是可以发现最终数据是没有回滚的:
1 | /** |
3. “吞异常”
吞异常也是常见的,很多时候会发现忘记抛出异常,当然实际情况没有那么明显,更多是在捕获异常之后没有抛出:
1 | /** |
偷偷埋下宝藏,日后惊艳全场?更多时候建议把抓到的异常像是抓到了定时炸弹。
4. 数据库引擎不支持
这种情况绝大多数基本不会碰到,但是如果真遇到的时候确实很难想到,这里我们可以直接把表改了之后试了一下:
1 | alter table t_trans_test ENGINE=MyISAM; |
Mysql低版本的时候默认创建表就是用的MyISAM存储引擎,所以不要认为这种低级错误还会有人犯么?我只能说有,还不少。
修改表之后再进行前面的操作就会发现无论如何操作,最后都是没有办法回滚事务。
5. 非“公有”方法
这个相信几乎不会犯错(大概),因为如果你将一个事务注解放到一个不是public方法上,部分编辑器比如IDEA会直接提示的,比如idea提示如下:
1 | Methods annotated with '@Transactional' must be overridable |
如果你没看到那根红线,=-=那只能自求多福了。
一定要注意必须是public,非要问为什么,可以问问反射和动态代理。
有的同学可能会说那我IDEA设置成 Protected或者默认不加任何东西,IDEA也没报错但是也没回滚呀,我只能说楼下没单杠可以去体育场……
(3)事务传播特性实战
下面又是事务的一个重点,也是必须要掌握的一个重点,那就是关于事务隔离级别在代码中的实际使用效果,下面我们将所有的情况都试验一遍:
| 特点 | 传播级别 | 说明 |
|---|---|---|
| 支持当前事务的情况: | TransactionDefinition.PROPAGATION_REQUIRED | 如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务。 |
| 支持当前事务的情况: | TransactionDefinition.PROPAGATION_SUPPORTS | 如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务的方式继续运行。 |
| 支持当前事务的情况: | TransactionDefinition.PROPAGATION_MANDATORY | 如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常。(mandatory:强制性) |
| 不支持当前事务的情况: | TransactionDefinition.PROPAGATION_REQUIRES_NEW | 创建一个新的事务,如果当前存在事务,则把当前事务挂起。 |
| 不支持当前事务的情况: | TransactionDefinition.PROPAGATION_NOT_SUPPORTED | 以非事务方式运行,如果当前存在事务,则把当前事务挂起。 |
| 不支持当前事务的情况: | TransactionDefinition.PROPAGATION_NEVER | 以非事务方式运行,如果当前存在事务,则抛出异常。 |
| 其他情况 | TransactionDefinition.PROPAGATION_NESTED | 如果当前存在事务,则创建一个事务作为当前事务的嵌套事务来运行;如果当前没有事务,则该取值等价于TransactionDefinition.PROPAGATION_REQUIRED。 |
1. PROPAGATION_REQUIRED
这个级别表示:如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务。这意味如果存在嵌套的事务操作,默认会以最外层的事务的为准,这里可以验证一下:
1 | /** |
从运行结果可以看出,如果在外层抛出事务的异常,哪怕内部的方法看似已经直接,最终结果依然会回滚,这也是十分常用的一种方式,所以被Spring设置这个级别为默认级别也可以理解。
2. PROPAGATION_SUPPORTS
如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务的方式继续运行。这种方式也好理解,就是有我就使用事务,没有我就该咋样咋样,比较随性的方式,和TransactionDefinition.PROPAGATION_REQUIRED最大区别就是在没有事务的时候不会主动创建。
这里我们来看一个比较奇怪的现象,读者可以思考一下为什么会出现下面的情况:
1 | /** |
从上面的代码可以看到,我们将事务的传播特性改变之后,发现无论是外部还是内部哪怕都抛出了异常,都没有进行回滚也就是说当前 的代码是没有使用事务的!!!如果我们需要让他们在同一个事务里面,可以做如下调整,下面的代码经过调整之后,在内部的事务中发现外层是存在事务的,所以他会加入到外层的事务当中,但是此时如果把外层的注解去掉,会发现它依然会非事务方式执行。
1 | /** |
可以看到这个传播级别使用比较容易犯错的,所以如果有必要使用的时候一定要手动抛出异常自己测试一下。
3. PROPAGATION_MANDATORY
这个级别比较简单粗暴,意思就是必须要有失误,否则我就报错,这里我们简单修改一下上一个小节的传播级别即可看到效果:
1 | /** |
4. PROPAGATION_NOT_SUPPORTED
创建一个新的事务,如果当前存在事务,则把当前事务挂起。这种级别设置意思是说内部的嵌套事务是独立的,如果内部存在失误则单独开启一个事务操作,但是我们实际操作之后发现居然报错了,抛出了一个CannotAcquireLockException的异常,这个异常搜索之后发现是数据库的数据行死锁了,为什么会死锁?这里建议读者可以先自己思考一下然后搜索下答案,这里就直接说了,这里涉及mysql的update机制,一个update的操作使用的是排他锁,此时按照当前的传播级别设置会出现事务挂起,但是挂起的时候锁是不会释放的,所以在内部方法执行的时候由于一直拿不到锁导致等待超时报错了:
1 | /** |
这里我们通过调整事务的执行操作顺序之后,可以看到在内部的事务回滚了,但是外部的事务没有回滚,这也意味着内部的事务回滚之后外部的事务直接失效了:
1 | (rollbackFor = Exception.class) |
5. PROPAGATION_NEVER
意思是不能有事务,有事务还会报错,这种情况就不演示了,用注解还不如不用注解,脱裤子放屁,目前个人没看到这个注解的实际使用场景。
6. PROPAGATION_NESTED
如果当前存在事务,则创建一个事务作为当前事务的嵌套事务来运行;如果当前没有事务,则该取值等价于TransactionDefinition.PROPAGATION_REQUIRED。
七、总结
这篇文章的内容比较多,Spring的事务在现在看来算是比较基础的东西,实际看代码发现并不是特别难,如果对于设计模式比较熟基本能看懂Spring的设计,下面我们来总结一下这篇文章的大致内容。
事务介绍:在文章的开始我们介绍了数据库事务的概念,事务是数据库是否流行的关键,事务的特性ACID,并发事务的问题,事务的主要四个隔离级别,以及简单介绍了事务中保存点的使用,这些是事务最为基础的内容,也是我们了解Spring事务的基础知识。
Spring事务:Spring 的事务在设计的考虑到了不同数据源以及多数据源的事务管理,在一开始我们重点列举了Spring事务的三个核心组件,将一个事务操作抽象为三个操作,获取连接,创建提交事务,回滚事务,这和上面提到的事务操作和特性和相吻合的。接着在事务隔离级别的基础上,Spring 设计了特性也就是事务的传播级别来实现不同的事务特性,在最后可以看一下整个S print设计的思路。
介绍完Spring的事务之后,开始介绍编程式事务的实现方式和声明式事务的实现方式,同时从源码的角度简单介绍了一下事务设计的核心,比如线程之间的事务隔离是通过ThreadLocal进行存储和隔离的,这也是实现嵌套事务的时候使用同一个事务的核心部分,介绍完编程式事务之后介绍了事务的核心声明式事务的,声明式的事务架构要比编程式事务复杂不少,需要更多的时间消化,并且需要一定的IOC容器和自动配置注入的知识才能看懂。
在最后的实战部分,我们总计了事务不生效的一些坑,和事务传播特性的一次实战,基本上把Spring事务注解基本使用场景列举了一下。
写在最后
主要的时间花费在阅读和理解源代码,不知道有多少人可以坚持到最后的,如果文章有任何建议或者错误欢迎指出。
巨人的肩膀
- 如何使用原始的方式进行事务管理:https://cloud.tencent.com/developer/article/1697221
- Spring Transaction Management: @Transactional In-Depth
- Spring源码分析:声明式事务梳理
- Spring声明式事务源码探究