if [ $# -lt 1 ]; then # 提示命令使用方法 echo"USAGE: $0 [-daemon] server.properties [--override property=value]*"exit 1 fi base_dir=$(dirname $0) if [ "x$KAFKA_LOG4J_OPTS" = "x" ]; then export KAFKA_LOG4J_OPTS="-Dlog4j.configuration=file:$base_dir/../config/log4j.properties" fi
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G" fi EXTRA_ARGS=${EXTRA_ARGS-'-name kafkaServer -loggc'} COMMAND=$1 case$COMMANDin -daemon) EXTRA_ARGS="-daemon "$EXTRA_ARGS shift ;; *) ;; esac exec$base_dir/kafka-run-class.sh $EXTRA_ARGS kafka.Kafka "$@"
xander@xander:~$ lll Command 'lll' not found, did you mean: command'lld' from deb lld (1:14.0-55~exp2) command'dll' from deb brickos (0.9.0.dfsg-12.2) command'lli' from deb llvm-runtime (1:14.0-55~exp2) command'llt' from deb storebackup (3.2.1-2) command'llc' from deb llvm (1:14.0-55~exp2) Try: sudo apt install <deb name> xander@xander:~$ echo $? 127 xander@xander:~$ echo"hello world"
#!/bin/sh # 从环境变量当中获取RocketMq环境变量地址 if [ -z "$ROCKETMQ_HOME" ] ; then ## resolve links - $0 may be a link to maven's home ## 解决链接问题 - $0 可能是maven的主页链接 # PS:$0 是脚本的命令本身 PRG="$0"
# need this for relative symlinks # 需要相关链接 while [ -h "$PRG" ] ; do ls=`ls -ld "$PRG"` link=`expr "$ls" : '.*-> \(.*\)$'` if expr "$link" : '/.*' > /dev/null; then PRG="$link" else PRG="`dirname "$PRG"`/$link" fi done # 暂存当前的执行路径 saveddir=`pwd`
ROCKETMQ_HOME=`dirname "$PRG"`/..
# make it fully qualified # 拼接获取RocketMQ绝对路径 ROCKETMQ_HOME=`cd"$ROCKETMQ_HOME" && pwd` # 跳转到当前暂存的命令执行路径 cd"$saveddir" fi
export ROCKETMQ_HOME
# 关键: 执行runserver.sh脚本,携带logback的日志xml配置,以及传递JVM的启动main方法的入口类绝对路径 sh ${ROCKETMQ_HOME}/bin/runserver.sh -Drmq.logback.configurationFile=$ROCKETMQ_HOME/conf/rmq.namesrv.logback.xml org.apache.rocketmq.namesrv.NamesrvStartup $@
#=========================================================================================== # JVM Configuration #=========================================================================================== # The RAMDisk initializing size in MB on Darwin OS for gc-log # 在 Darwin OS 上为 gc-log 初始化 RAMDisk 的大小(以 MB 为单位) DIR_SIZE_IN_MB=600
choose_gc_log_directory() { # Darwin 操作系统需要特殊处理,忽略 case"`uname`"in Darwin) if [ ! -d "/Volumes/RAMDisk" ]; then # create ram disk on Darwin systems as gc-log directory DEV=`hdiutil attach -nomount ram://$((2 * 1024 * DIR_SIZE_IN_MB))` > /dev/null diskutil eraseVolume HFS+ RAMDisk ${DEV} > /dev/null echo"Create RAMDisk /Volumes/RAMDisk for gc logging on Darwin OS." fi GC_LOG_DIR="/Volumes/RAMDisk" ;; *) # # check if /dev/shm exists on other systems # 检查 /dev/shm 是否存在于其他系统上 # What Is /dev/shm And Its Practical Usage # https://www.cyberciti.biz/tips/what-is-devshm-and-its-practical-usage.html if [ -d "/dev/shm" ]; then GC_LOG_DIR="/dev/shm" else GC_LOG_DIR=${BASE_DIR} fi ;; esac }
# 在 Darwin OS 上为 gc-log 初始化 RAMDisk 的大小(以 MB 为单位) DIR_SIZE_IN_MB=600
choose_gc_log_directory() { # Darwin 操作系统需要特殊处理,忽略 case"`uname`"in Darwin) if [ ! -d "/Volumes/RAMDisk" ]; then # create ram disk on Darwin systems as gc-log directory DEV=`hdiutil attach -nomount ram://$((2 * 1024 * DIR_SIZE_IN_MB))` > /dev/null diskutil eraseVolume HFS+ RAMDisk ${DEV} > /dev/null echo"Create RAMDisk /Volumes/RAMDisk for gc logging on Darwin OS." fi GC_LOG_DIR="/Volumes/RAMDisk" ;; *) # # check if /dev/shm exists on other systems # 检查 /dev/shm 是否存在于其他系统上 # What Is /dev/shm And Its Practical Usage # https://www.cyberciti.biz/tips/what-is-devshm-and-its-practical-usage.html if [ -d "/dev/shm" ]; then GC_LOG_DIR="/dev/shm" else GC_LOG_DIR=${BASE_DIR} fi ;; esac }
-XX:G1ReservePercent=10 Sets the percentage of reserve memory to keep free so as to reduce the risk of to-space overflows. The default is 10 percent. When you increase or decrease the percentage, make sure to adjust the total Java heap by the same amount. This setting is not available in Java HotSpot VM, build 设置保留内存的百分比,以减少到空间溢出的风险。默认是10%。当你增加或减少这个百分比时,请确保预留足够的空间并且调整Java堆大小。注意这个设置在Java HotSpot VM中是不可用的。
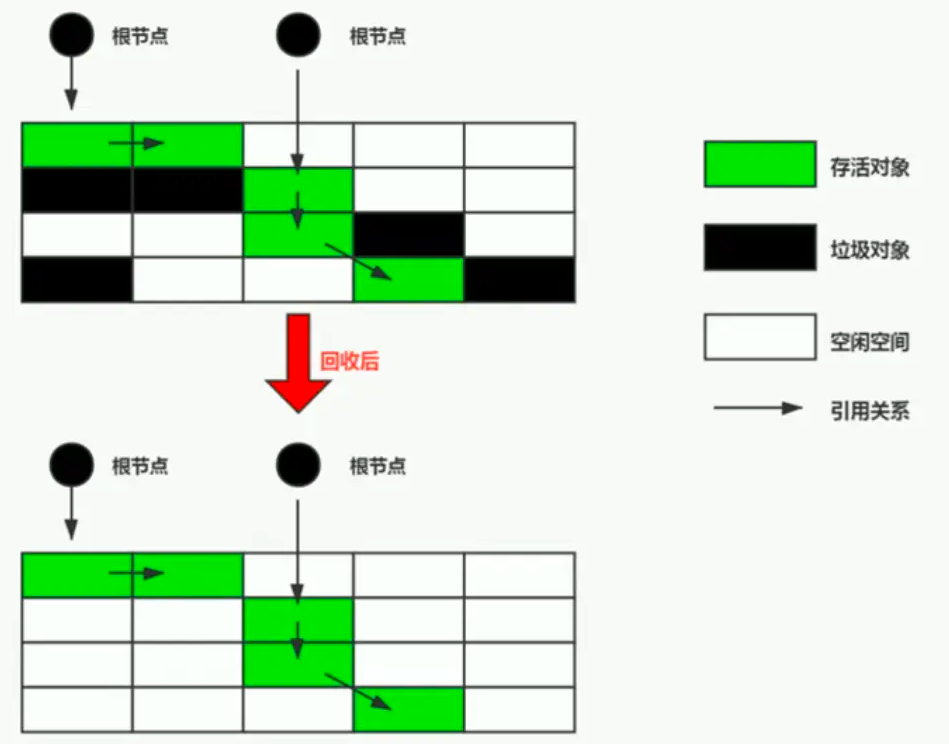
扩大这个数值可以保证在进行GC 的时候提供更多堆内存保证存活空间存放晋升老年代的Region.
G1为分配担保预留的空间比例:通过-XX:G1ReservePercent指定,默认10%。也就是老年代会预留10%的空间来给新生代的对象晋升,如果经常发生新生代晋升失败而导致 Full GC,那么可以适当调高此阈值。但是调高此值同时也意味着降低了老年代的实际可用空间。
As shown above, the JVM will rotate the GC log file whenever its size reaches 20MB. It will generate up to five files, with extensions gc.log.0, gc.log.1, gc.log.2, gc.log.3, and gc.log.4.