引言
本文介绍网络IO编程的入门部分,Java 的传统BIO Socket编程源码分析,了解如何将BIO阻塞行为accept() 和 read() 改造为非阻塞行为,并且将结合Linux文档介绍其中的机制,文档中描述了如何处理Socket的accept,对比Java的Socket实现代码,基本可以发现和Linux行为基本一致。
废话不多说,我们直接开始。
draw.io 文件
本文涉及的个人源码分析绘图均由 draw.io 绘制,源文件如下:
链接:https://pan.baidu.com/s/1FHAYt4AxWh0Dd4qi2JKZLQ?pwd=qsmg
提取码:qsmg
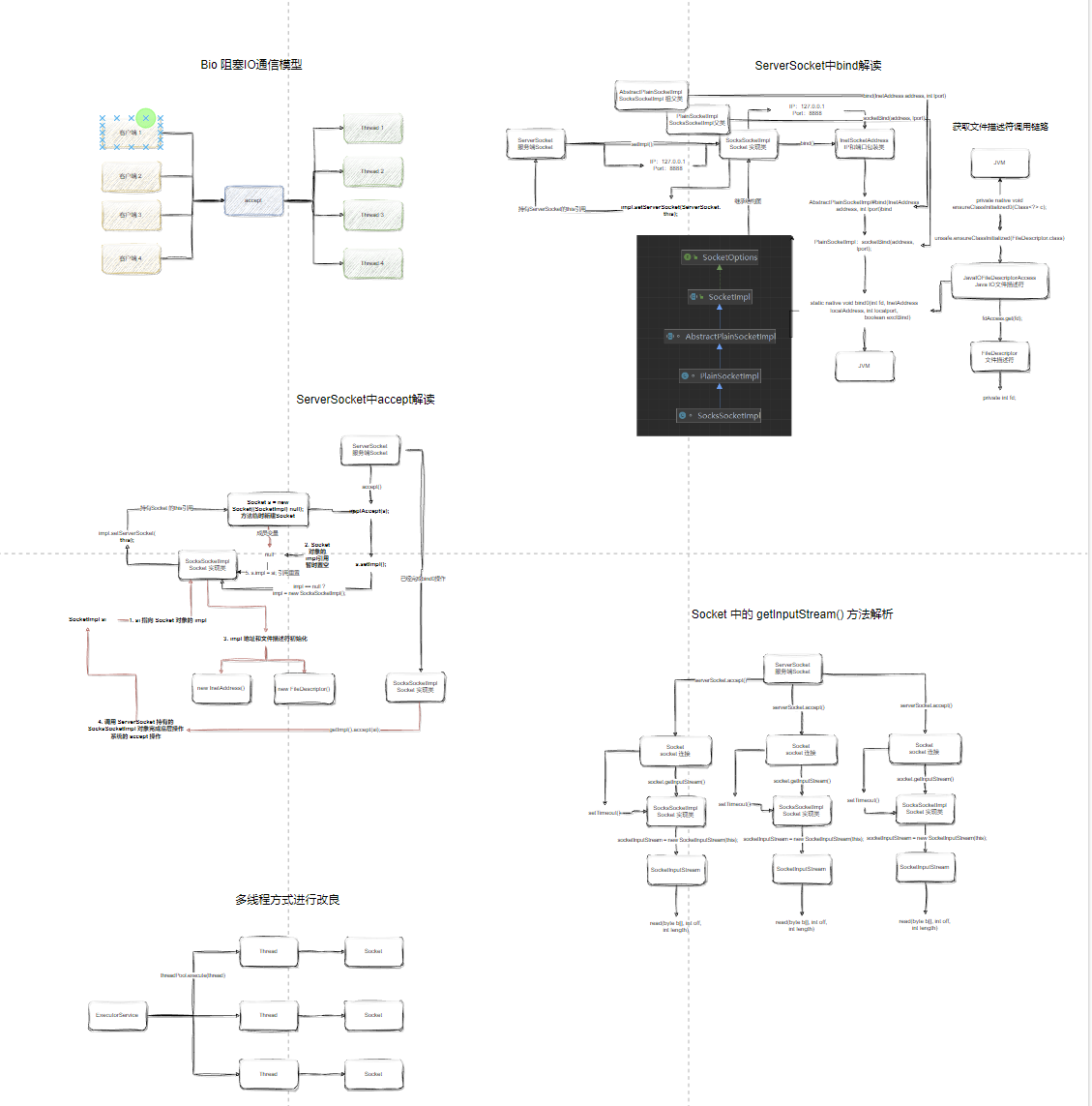
什么是Socket?
Socket起源于Unix的一种通信机制,中文通常叫他“套接字”,代表了网络IP和端口,可以看作是通信过程的一个“句柄”。
Socket 也可以理解为网络编程当中的API,编程语言提供了对应的API实现方式,电脑上的网络应用程序也是通过“套接字”完成网络请求接受与应答。
总而言之:Socket是应用层与TCP/IP协议族通信的中间软件抽象层。
图片来源:socket图解 · Go语言中文文档 (topgoer.com)
阻塞式IO模型
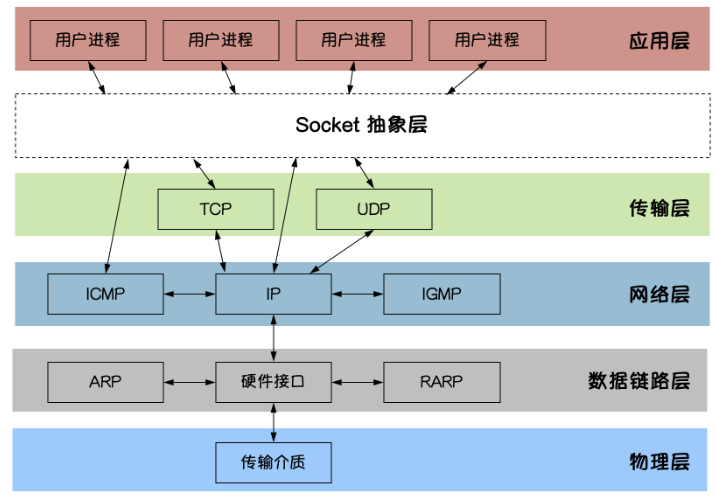
在 《UNIX Network Programming》 一书当中,用UDP传输的案例模拟了阻塞式的IO模型,这个模型的概念和Java BIO的阻塞模型类似。
下面函数中应用进程在调用 recvfrom 之后就开始系统调用并且进行阻塞,等待内核把数据准备并且复制完成之后才得到结果,或者等待过程中发生错误返回。
从图片可以看到,在内核工作的整个过程中应用进程无法做其他任何操作。
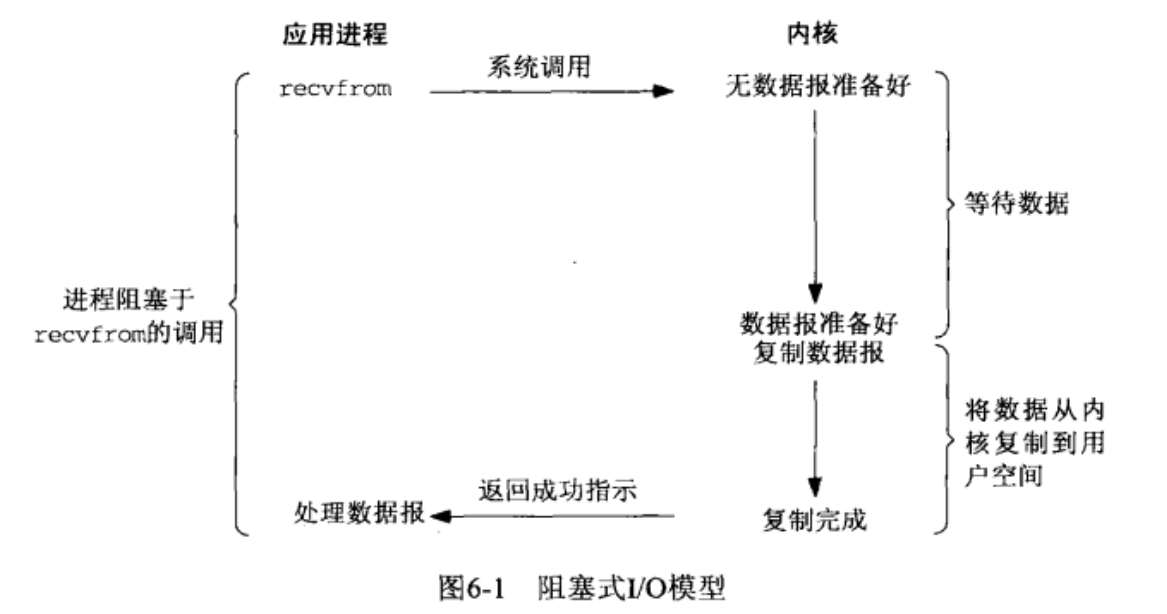
BIO 通信模型
我们把上面的阻塞IO模型转为IO通信模型,结果如下:
BIO对于每一个客户端进行阻塞等待接收连接,同一个时间只能处理一个Socket请求,并且在构建完成之后通常会分配一个Thread线程为其进行服务。
BIO 阻塞案例代码
BioClientSocket
1 | /** |
BioServerSocket
1 |
|
BIO 阻塞模型中,需要关注的代码主要是这几个:
serverSocket = new ServerSocket(port);socket = serverSocket.accept();socket = new Socket(host, port);
从代码中可以看出,客户端在获取Socket建立连接后,通过系统输入输出流完成读写IO操作,服务端则通过系统缓冲流Buffer来提高读写效率。
ServerSocket 中 bind 解读
在具体的解读之前,先看下整个调用的大致流程图。
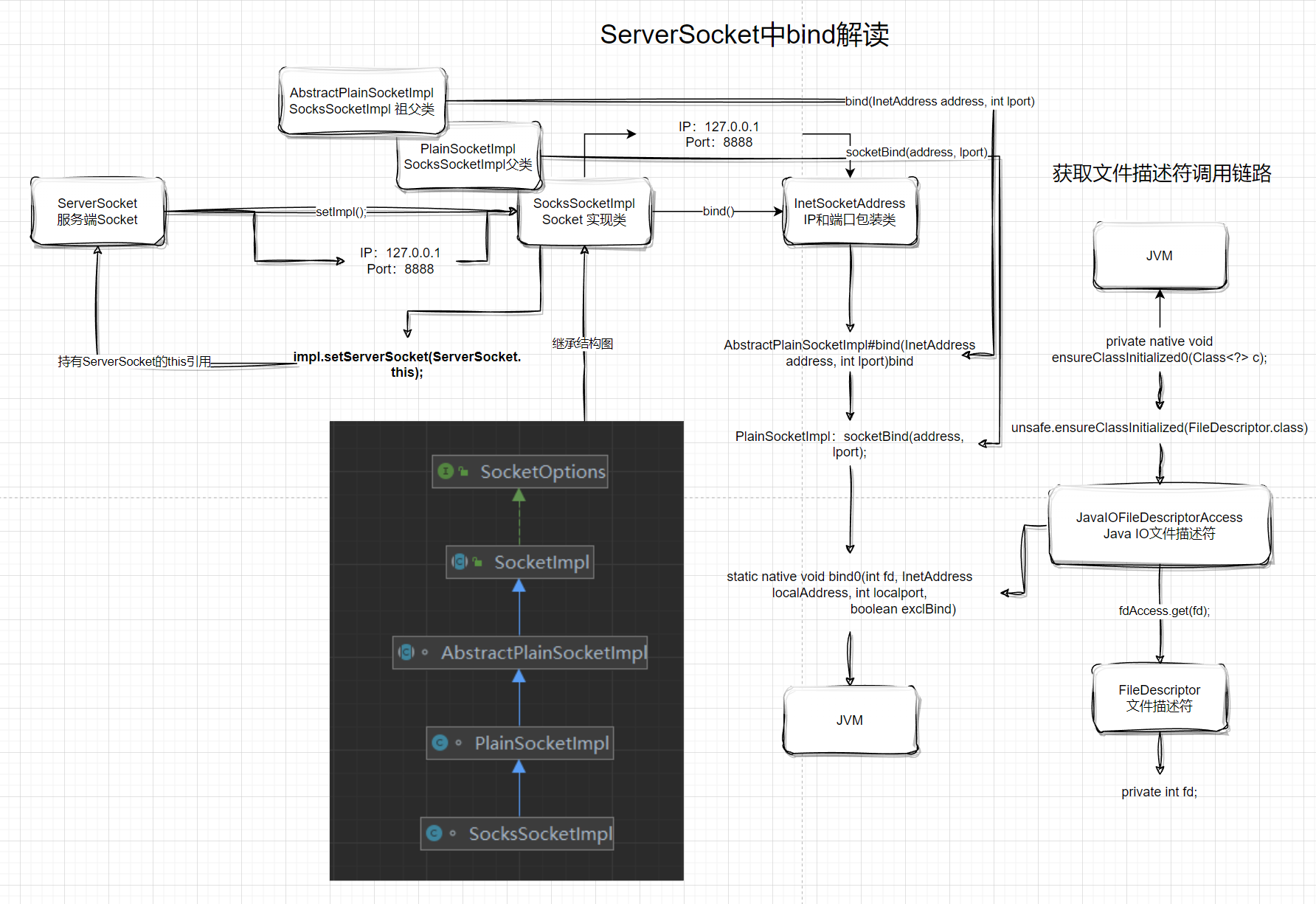
由于是ServerSocket服务端先启动,这里先对bind操作进行解读,bind操作是在本机的某个端口和IP地址上进行listen监听。
在bind成功之后,服务端进入accept阻塞等待,此时客户端Socket请求此地址将会进行Socket连接绑定。
我们从ServerSocket的初始化代码作为入口进行介绍。
1 | //java.net.ServerSocket#ServerSocket(int) |
setImpl();这个方法我们先暂时放到一边,我们简单扫一下其他代码。
在上面的案例代码当中,我们传入的ip和port都处在合法的范围内,Socket规定的端口范围是0 - 65525,超过这个范围不允许进行bind。
上面代码的核心逻辑是bind(xxx)这一段操作。
1 | bind(new InetSocketAddress(bindAddr, port), backlog); |
new InetSocketAddress(bindAddr, port)
在bind方法调用之前,ServerSocket会先构建 InetSocketAddress 对象。InetSocketAddress对象构建实际为InetSocketAddressHolder包装类。包装类的作用是可以防止IP和Port等敏感字段的外部篡改。
此外从代码可以看到,构建对象会对于IP和Port进行二次检查,如果IP地址不存在,会给一个默认值(通常是0.0.0.0 )。
Creates a socket address from an IP address and a port number.
A valid port value is between 0 and 65535. A port number of zero will let the system pick up an ephemeral port in a bind operation.|
根据IP地址和端口号创建Socket地址。有效的端口值介于0和65535之间。端口号为0时,系统将在绑定操作中使用短暂端口。
InetSocketAddressHolder 对象构建完成之后,接着就进入到核心的bind(SocketAddress endpoint, int backlog)内部代码。
bind(SocketAddress endpoint, int backlog)
java.net.ServerSocket#bind(java.net.SocketAddress, int)
1 | /** |
bind 方法是将 ServerSocket 绑定到一个特定的地址(IP地址和端口号), 如果地址为空,那么系统会选取一个临时端口和有效的本地地址来绑定 ServerSocket。
跳过不需要关注的校验代码,在·try 中有三行比较重要的代码。
1 | getImpl().bind(epoint.getAddress(), epoint.getPort()); |
这里的代码初步理解是获取一个impl对象,绑定地址和端口,调用listen方法传递backlog。
backlog这个值的作用可以看下面的地址,这里整理文章内容大致理解:
Linux Network Programming, Part 1 (linuxjournal.com)
详解socket中的backlog 参数 - 知乎 (zhihu.com)
backlog主要是和Socket有关。在Socket编程中listen函数的第二个参数为backlog,用于服务器编程。
1 | listen(sock, backlog); |

在TCP 三次握手当中,LISTEN 状态的服务端 Socket 收到 SYN,会建立一个 SYN_REVD 的连接,SYN_REVD 是一个半连接状态,只有在收到客户端的ACK之后才会进入ESTABLISHED,也就是说三次握手的过程必然会经历SYN_REVD和ESTABLISHED两个状态。
针对这两个状态,不同的操作系统有不同实现,在 FressBSD 中 backlog 就是描述状态为 SYN_REVD 和 ESTABLISHED 的所有连接最大数量。
在 Linux 系统当中,使用两个队列 syn queue和 accept queue,这两个队列分别存储状态为SYN_REVD和状态为ESTABLISHED的连接,Llinux2.2及以后,backlog表示accept queue的大小,而syn queue大小由 /proc/sys/net/ipv4/tcp_max_syn_backlog配置。
可以看到backlog的值直接影响了建立连接的效率。上面代码中backlog=50,可以认为 accept queue 的容量为 50。
listen方法执行完成之后,此时将设置bound = true,代码执行到此处说明Socket绑定成功了。
现在我们回过头看getImpl().bind(epoint.getAddress(), epoint.getPort());这块代码工作。
setImpl()
介绍getImpl()的前提是我们要知道如何set的,具体代码位于构造方法中一行不起眼的setImpl()操作。
java.net.ServerSocket#setImpl。
1 | private void setImpl() { |
注意,在第一次初始化的时候,SocketImplFactory是没有被初始化过的,所以走的是else分支,具体工作是为内部的成员变量 SocketImpl进行初始化。
1 |
|
SocksSocketImpl 初始化之后,将会设置它的成员变量ServerSocket为this引用
1 | if (impl != null) |
这里的处理工作很简单,分别是初始化 SocksSocketImpl ,把当前对象实例的this引用传递给这个初始化的 SocksSocketImpl 的成员变量(这时候自身的引用逸出了)。
了解setImpl之后,下面这里我们再看看 getImpl() 干了啥。
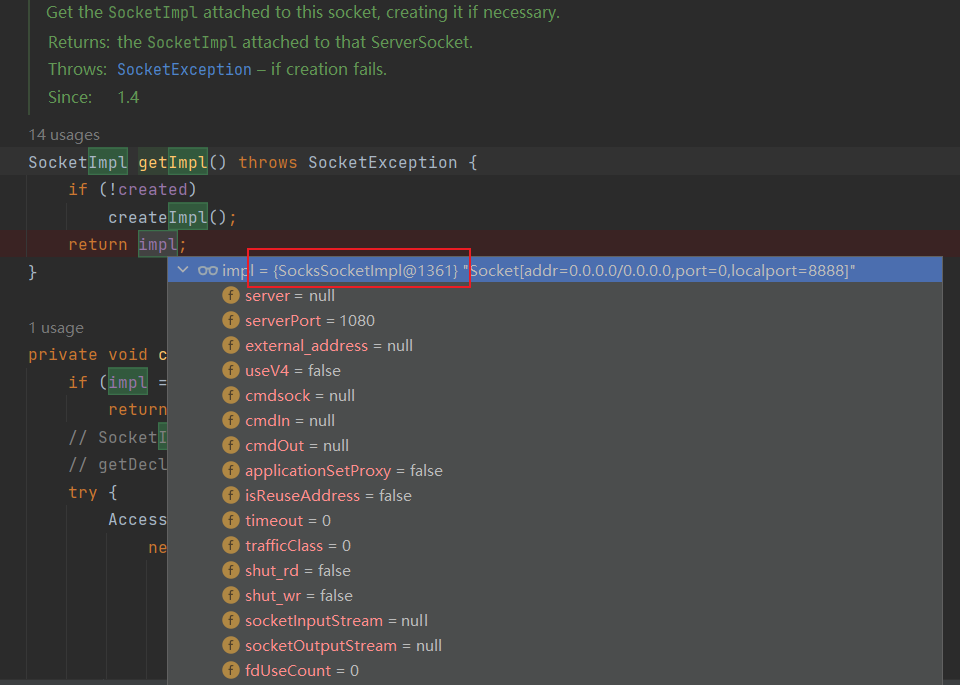
getImpl()
java.net.ServerSocket#getImpl
代码内容也比较简单,首先检查SocketImpl是否创建,第一次连接这里为false,此时会进入createImpl()方法。
1 | /** |
在createImpl()当中,通常 SocketImpl 已经在构造器初始化完成,这里直接更新 created 状态即可。
1 | void createImpl() throws SocketException { |
setImpl() 和 getImpl()方法配合,可以确定 SocketImpl 在使用的时候一定是被初始化完成的。
SocketImpl.bind(epoint.getAddress(), epoint.getPort())
下面再来看看它是如何进行下面两项关键操作的:
1 | getImpl().bind(epoint.getAddress(), epoint.getPort()); |
在之前的初始化代码中,InetAddress对象初始化设置了IP和Port等参数,现在委托 SocketImpl执行具体bind操作。
java.net.AbstractPlainSocketImpl#bind
bind方法是同步的,一开始需要先获取到fdLock锁,然后判断是否满足Socket绑定条件,如果满足则利用钩子(NetHooks) 对象进行前置TCP绑定。
注意,个人发现
NetHooks.beforeTcpBind(fd, address, lport);方法发现在JDK11之中是一个空方法,而JDK8当中会有一段provider.implBeforeTcpBind(fdObj, address, port);的调用。
1 | protected synchronized void bind(InetAddress address, int lport) |
加锁部分和核心逻辑无太多干系,我们跳过细枝末节,看socketBind(address, lport);这部分代码。
fdLock 锁作用:注释说明它用于在增加/减少fdUseCount时锁定。
1 | /* lock when increment/decrementing fdUseCount */ |
PlainSocketImpl#socketBind(InetAddress address, int port)
1 |
|
socketBind(address, lport);方法调用,最后绑定操作为JVM的底层C++操作bind0。
bind0属于比较底层的代码,这里我们就不继续探究了,如果读者好奇,可以阅读 HotSpot 的开源实现代码。
1 | static native void bind0(int fd, InetAddress localAddress, int localport, |
从整体上看,上面这一整个bind操作都是同步完成的,主要逻辑是先做一系列检查,之后调用底层的JVM方法完成Socket绑定。
画图小结
笔者通过个人理解画了一幅图,主要描述了 bind 操作大致的逻辑,可以看到很多地方都和JVM的底层C++代码打交道。
有必要说明一下,BIO毕竟是 Java1.0 出来的玩意,看源码我们要抓大放小,后续的JDK提案中,有人提出要收拾这个老古董=-=。
从图中也可以看出,要完成Socket连接构建,必须要获得文件描述符。
ServerSocket中accept解读
ServerSocket的accpet是如何阻塞获取连接的?
accept方法的作用是询问操作系统是否有收到新的Socket套接字信息,操作过程在操作系统底层调用实现上都是 同步的。
操作系统从Socket中没有Socket连接进来怎么办?根据Linux的accept文档描述,以及Java注释的JavaDoc文档描述,都明确说明此时会在底层操作系统阻塞 。
java.net.ServerSocket#accept
我们从代码层面看看 accept 方法干了啥。
1 | /** |
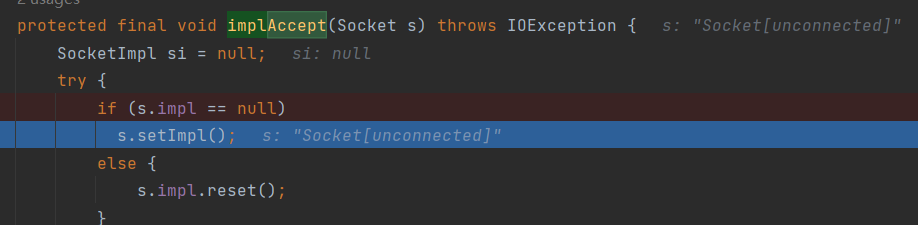
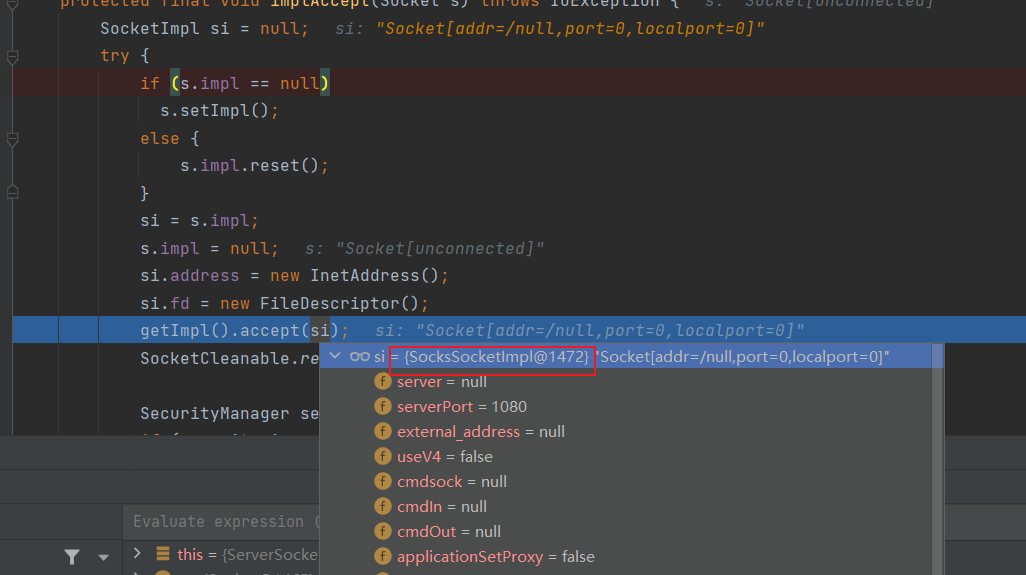
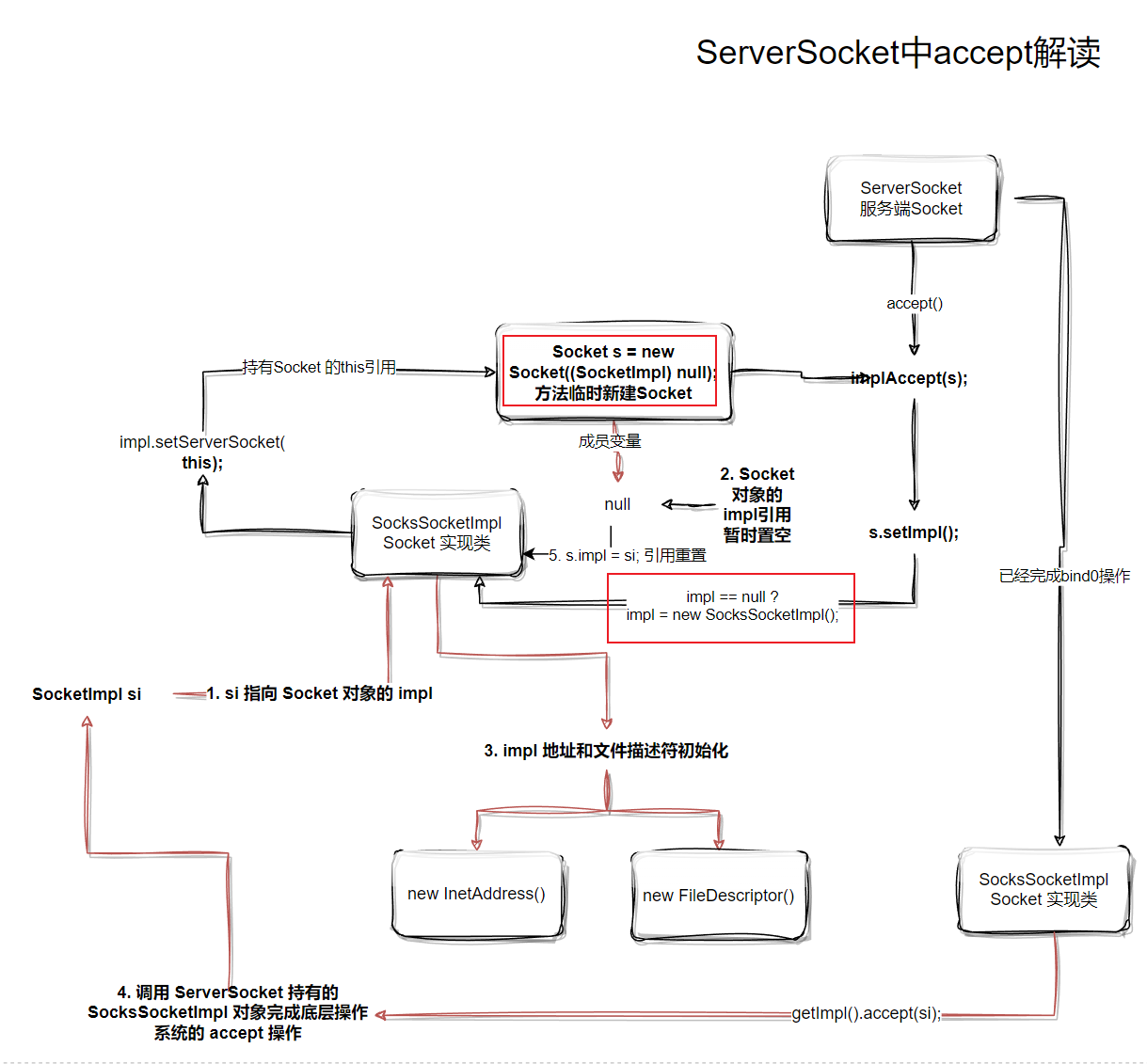
Java Doc 说明了accept()会进行阻塞,这里疑问比较大的点可能是Socket s = new Socket((SocketImpl) null);,这行代码为什么又要新建一个Socket?带着疑问我们继续看implAccept(s);方法。
java.net.ServerSocket#implAccept
1 | /** |
代码首先进入一个if判断,检查 new Socket 新对象的Socketimpl是否设置,如果为空则就设置,如果不为空,则reset() 重置。
毫无疑问,这里是刚刚初始化的Socket,此时Socket.Socketimpl 肯定是没有设置的。
1 | if (s.impl == null) |
首次进入代码通常就是走if分支。Socket.setImpl 这个方法和ServerSocket的setImpl非常像,new Socket 新对象会为自己的 SocketImpl 成员对象进行初始化。
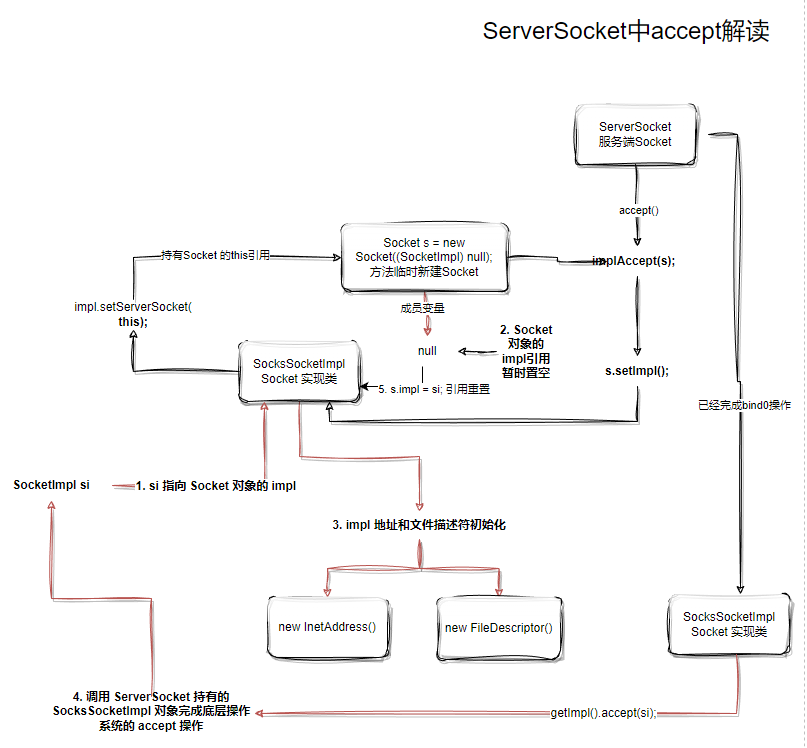
至此,我们画图理解代码操作逻辑:
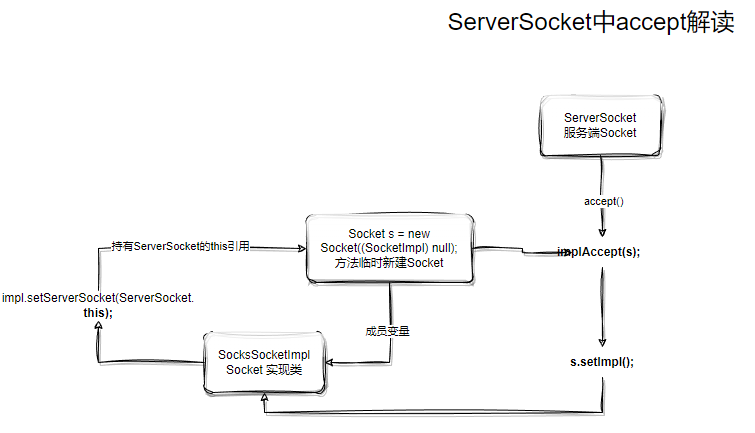
接下来是一些有点”绕“的操作,建议读者边调试边跟着图示理解:
1 | // 1. si 指向 Socket 对象的 impl |
这里吐槽下老外这种变量命名给规则,啥
si呀s,a,b,c,d 的,不画图很容易绕进去。
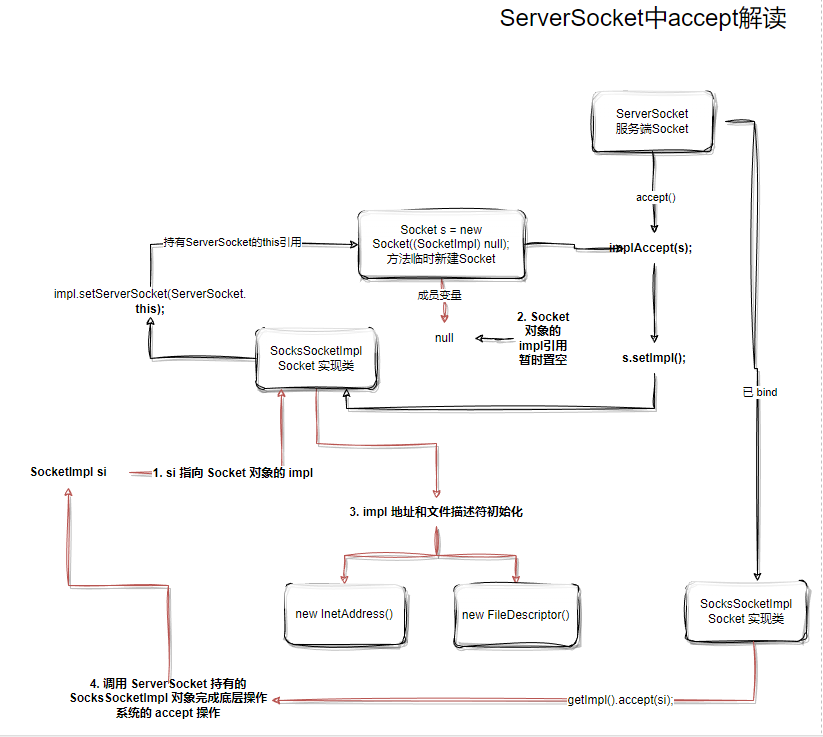
格外强调下, getImpl() 的 impl对象和 si.impl 对象并不是同一个,这些代码内容非常像但是属于不同的类,切记不要混淆。
代码最后有必定会执行的 s.impl = si;操作(因为之前暂时把引用“脱钩”了),如果是异常的si还会进行额外的reset重置。
1 | s.impl = si; |
这里回答一下之前遗留的问题,Socket s = new Socket((SocketImpl) null);这行代码为什么又要新建一个Socket?
我们观察上面绘制的操作图,s.impl = null;的执行,此时Socket对象和这个SocketImpl暂时”失去关联“,这个时候确保哪怕new Socket对象绑定失败,此时对于SocketImpl来说根本是无感知的。
换句话说,如果失败了Socket会完全重置,好像什么都没有发送过,而如果成功了,此时把引用“接回去”,必然得到的可用的Socket。
这里给一个不恰当的比喻,当年诸葛亮草船借箭,如果有碰到没有借箭的船,极端一点是不是就可以直接”烧了“不要了,而如果“接”到箭自然需要回港“卸货‘”,对于吴国来说,它们只看到“成功”借到箭的船只。
执行getImpl().accept(si);方法之后,我们在AbstractPlainSocketImpl找到accept方法。我
java.net.AbstractPlainSocketImpl#accept
1 | /** |
accept调用acquireFD();获取并且植入文件描述符号,加锁获取之后会把fdUseCount 的计数器值+1,表示有一个新增的Socket连接。
加锁保证 fdUseCount 计数是线程安全的
1 | // "Acquires" and returns the FileDescriptor for this impl |
java.net.PlainSocketImpl#socketAccept
不同的操作系统实现不同,这里仅以个人看到的JDK11版本源码为例。
1 |
|
我们只关心下面这部分代码,方法中首先判断 timeout 是否小于等于0(如果没有设置,那么默认就是 0),如果是则走accept0(nativefd, isaa)方法。
前面反复提到的,accept操作核心实现这是下面的 native accept0 方法,具体操作是:
在操作系统层面检查bind的端口上是否有客户端数据接入,如果没有则一直阻塞等待
1 | if (timeout <= 0) { |
1 | static native int accept0(int fd, InetSocketAddress[] isaa) throws IOException; |
因为操作系统层面的阻塞需要影响到应用程序级别阻塞?显然accept0(nativefd, isaa)的操作系统层面阻塞是无 法避免的。
仔细观察代码,上面的代码分支提供了另外一种选择, timeout 的值设置大于0的值,此时程序会在等到我们设置的时间后返回,并且只会阻塞设置的这个时间量的值(单位毫秒)。
注意,这里的 newfd 如果是 -1,表示底层没有任何数据返回,在Linux的文档中也有对应的介绍。
java.net.ServerSocket#setSoTimeout
既然不阻塞的关键参数是timeout , 接下来我们看下 timeout 值要如何设置。
1 | /** |
简单明了,java.net.SocketOptions#setOption 方法最终调用的是java.net.AbstractPlainSocketImpl#setOption()。
java.net.AbstractPlainSocketImpl#setOption
1 | public void setOption(int opt, Object val) throws SocketException { |
为了方便阅读,这里把其他的代码都删除了,只保留传参部分。
可以看到,这里仅仅是将setOption里面传入的timeout值,设置到了AbstractPlainSocketImpl的全局变量timeout。
画图小结
个人认为整个accept()操作比较”恶心“(个人观点)的是几个引用的赋值变化上面,暂时”解绑“的目的是在进行底层Socket连接的时候,如果Socket出现异常也没有影响,此时Socket持有的引用也是null,可以无阻碍的重新进行下一次Socket连接。
换句话说,整个Socket要么对接成功,要么就是重置回没对接之前的状态可以进行下一次尝试,保证ServerSocket会收到一个没有任何异常的Socket连接。
最后再看一眼图:
改造并实现accept的非阻塞实现
在进行案例程序的改造之前,必须要先理解同步、异步、阻塞、非阻塞这几个概念。
这个概念在之前的笔记中 [[《跟闪电侠学Netty》阅读笔记 - 开篇入门Netty]] 【洗衣机案例理解阻塞非阻塞,同步异步概念】这一部分提到过,[[【Java】《2小时搞定多线程》个人笔记]] 中又一次对于这几个概念做了个区分。
区分同步和异步的关键点是被调用方的行为,没有得到结果之前,服务端不返回任何结果,那么操作就是同步的。
如果没有得到结果之前,服务器可以返回结果,比如给一个句柄,通过这个句柄可以在未来某个时间点之后获得结果,那么操作就是异步的。
这个句柄可以对应Java 并发编程的 Future 的概念
再举个例子,比如说前面的accept0是应用程序调用操作系统,在Linux中就是访问系统内核,此时这一整块逻辑处理是选择”永久等待一个客户端连接“,符合 没有得到结果之前,服务端不返回任何结果 这种情况,所以它是同步的。
区分阻塞和非阻塞的关键点则是 对于调用者而言的服务端状态*,比如我们站在线程状态的角度,阻塞对应 Blocking,非阻塞此时应该对应Running正常执行。再比如站在线程发出请求之后请求方的角度,阻塞和非阻塞分别对应waiting和No waiting。
理解同步异步阻塞和非阻塞之后,下面来尝试改造相关代码accept的阻塞问题,实现方式很简单,那就是设置 ** timeout ** , 然后在异常处理上continue重试。
1 | /** |
设置了timeout之后,accept 方法每次都会在间隔指定时间之后被唤醒一次,如果没有收到连接就会抛出异常,我们的处理方式是吞掉异常并且重新accept,这样就实现了类似非阻塞的效果。
小结
Socket 当中 getInputStream() 的方法解析以及后续的read操作结构图如下。
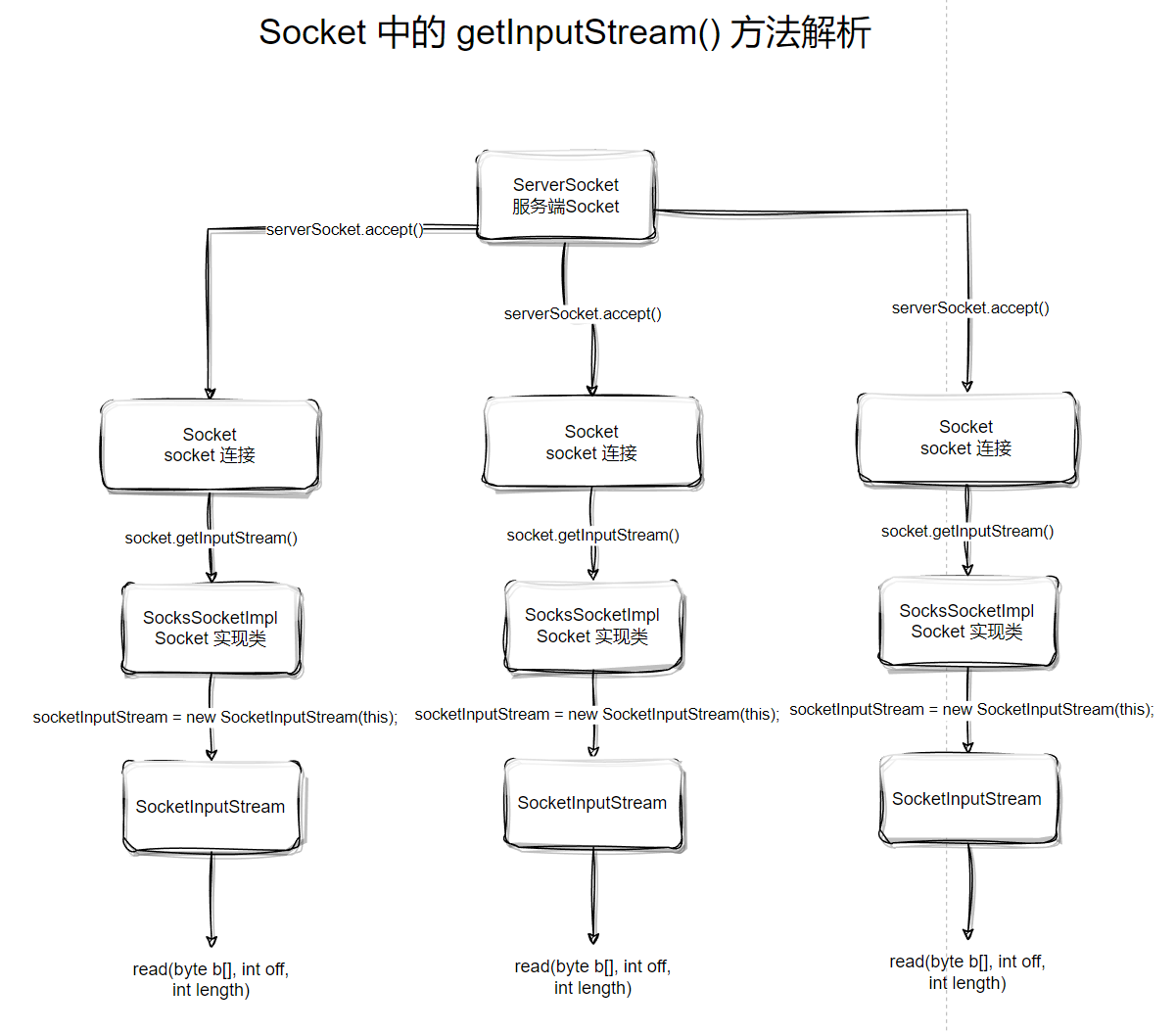
Socket 中的 getInputStream() 方法解析
实现了非阻塞的accept之后,再来看下另一个会产生阻塞的方法,那就是Socket.getInputStream,这个方法在Socket连接,服务端在read() 读取数据的时候会进行调用。
java.net.Socket#getInputStream
1 | /** |
上面通过AccessController进行授权,run方法中调用java.net.AbstractPlainSocketImpl#getInputStream方法。
1 | protected synchronized InputStream getInputStream() throws IOException { |
可以看到,代码中创建了 SocketInputStream 对象,并且会将当前AbstractPlainSocketImpl对象传进去(这个对象实际就是 SocksSocketImpl )。
read读数据的时候,则会调用如下方法:
1 | public int read(byte b[], int off, int length) throws IOException { |
1 | int read(byte b[], int off, int length, int timeout) throws IOException { |
重点关注下面这一行代码,这里在读取的时候同样传递了 timeout 参数:
1 | n = socketRead(fd, b, off, length, timeout); |
socketRead 方法会调用 native 的 socketRead0 方法,timeout 代表了读取的超时时间。
1 | private native int socketRead0(FileDescriptor fd, |
timeout 参数源于前面的new SocketInputStream(this)(也就是 AbstractPlainSocketImpl 对象)中的this引用impl.getTimeout(),这个参数的作用是指定read的超时时间,超时之后没有结果抛出异常。
1 | serverSocket.setSoTimeout(SO_TIMEOUT); |
了解read方法中timeout的作用之后,我们便可以着手改造代码了,具体的改造部分个人放到后文单独的 titile 进行说明,方便后续回顾。
此外,这里经过仔细考虑,判断这部分代码读者很有可能会存在理解误区,误以为此处的 AbstractPlainSocketImpl 属于 ServerSocket,实际上它属于 Socket,也就是说我们设置的 timeout 是设置到 Socket 的 AbstractPlainSocketImpl 。
最为简单的证明方法是先在 java.net.Socket#setImpl 中打上断点,在启动BIO的服务端之后,立即启动客户端,具体的Debug断点如下:
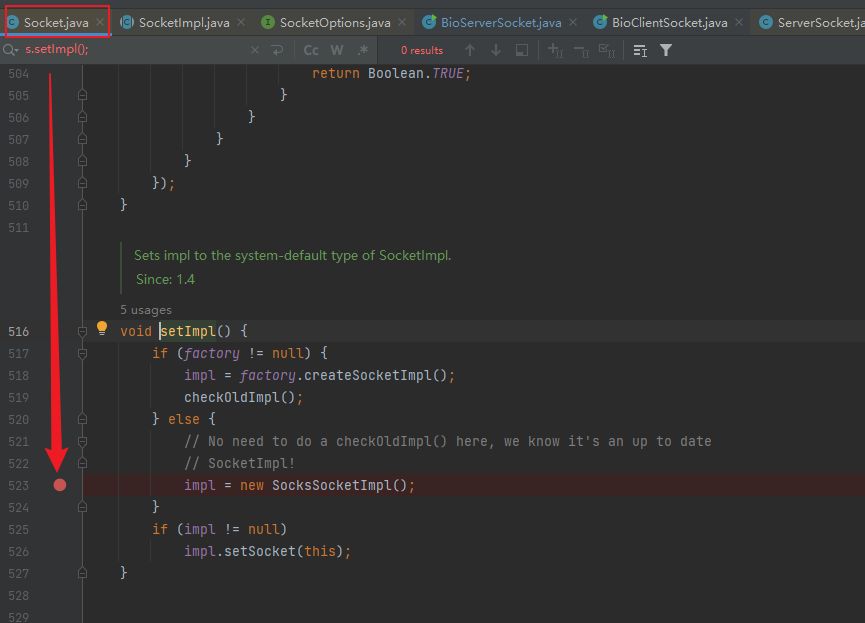
通过单步调试,我们在BioServerSocket 中看到两个对象是不一样的。
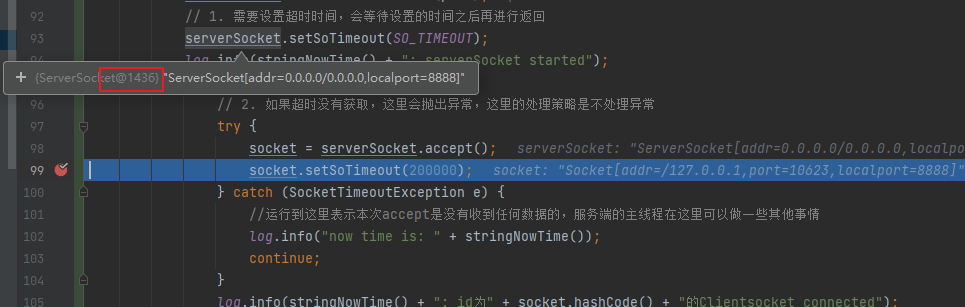

为什么不一样呢?这里需要回顾前面的【ServerSocket中accept 解读】这一部分的操作。这里把重要操作标记了一下:
这里复习之前提到的内容,在accept(); 中为了确保Socket连接是正确并且可用的,每次都会new Socket(),而这里的SocksSocketImpl 是属于 Socket 的成员变量。
在进行Socket套接字连接之前会先判断是否初始化,如果初始化没有就先进行初始化(具体可以看红框框的位置)。
如果还是理解不了,那么只能再次寄出另一张杀手锏图了:
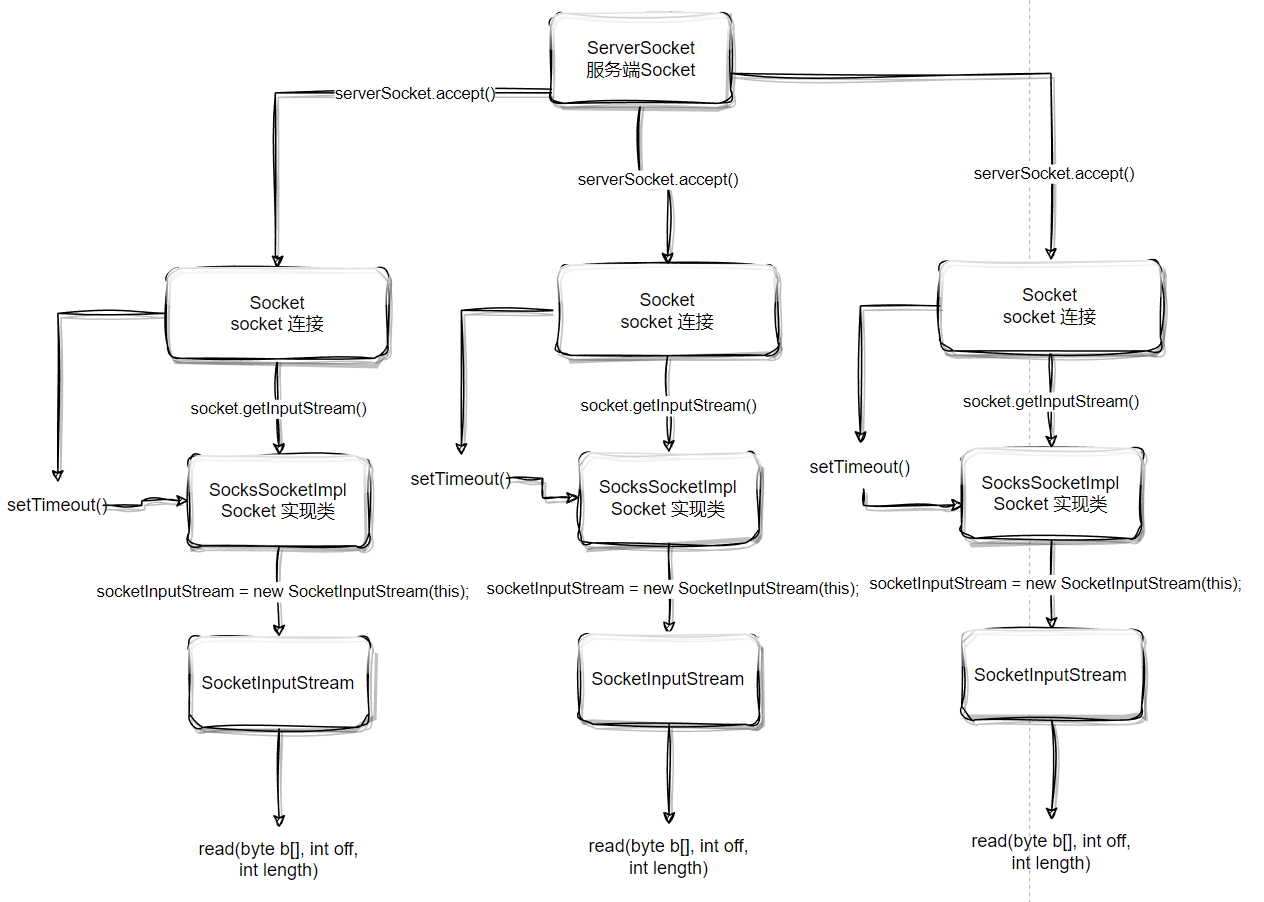
实现 Socket 中的 read 方法非阻塞
AbstractPlainSocketImpl实现socketRead方法非阻塞,具体做法其实就是使用 AbstractPlainSocketImpl 传入了 timeout 参数,实现 SocketInputStream 非阻塞read。
表面上看上去 read 方法是非阻塞的,实际上这里存在一个明显的 误区,那就是在socket = serverSocket.accept();这一段代码中,服务端构建出 Socket 连接之后,客户端和服务端交互是通过独立的Socket对象完成IO读写的。
然而在第一次改造过后,实际上还有两点不易察觉的问题:
(1)服务端read的非阻塞轮询效率非常低,基本上是“一核繁忙、多核围观”的情况。
(2)第一次改造设置的是设定的是ServerSocket级别的SocksSocketImpl的timeout。每个新的客户端进来都是新的Socket连接,每个Socket又有各自的 SocksSocketImpl,这里客户端连接所产生新的Socket的timeout是没有做设置的,换句话说,服务端针对每个Socket的read依然是完全阻塞。
前文提到,在BIO非阻塞同步模型中,我们虽然没法解决 系统底层”同步” 问题,但是我们可以让“非阻塞”这一块更为优化合理和更为高效。
第一个问题的解决策略是启动多线程以非阻塞read()方式轮询,这样做的另一点好处是,某个Socket读写压力大并不会影响CPU 切到其他线程的正常工作。
解决第二点问题,我们需要为每个新的Socket设置 timeout。
解决上面两个问题,真正BIO非阻塞实现才算是真正成立,下面我们来看下第二版代码优化:
1 | /** |
经过上面的改造,我们基本把 BIO 同步阻塞的工作方式更新为 同步非阻塞的工作方式,核心是对于 read()以及服务端接收新连接的accept()设置timeout参数。
在外部处理上,通过while(true) 加上“吞异常”方式,结合Thread.sleep()的套路实现“非阻塞”定期accept。
当然,我们也可以看到,通过线程池每次都构建新线程的方式,在连接比较少的时候是比较高效的,但是一旦连接暴增,理论上JVM虽然可以构建非常多线程,实际上CPU肯定是吃不消,多线程“空轮询”判断的方式也十分浪费CPU资源,多线程切换起来更是雪上加霜。
基于BIO的种种弊端,Sun 在JDK1.4 提供了 NIO 来解决上面的几点问题。
native accept方法在Linux运作解读
accept(2): accept connection on socket - Linux man page (die.net)
原始文档相关解读:[[【Linux】accept(2) - Linux man page]],下面的内容基本为文档的翻译和理解介绍。
accept()本地方法,我们可以来试着看一看Linux这块的相关解读:
1 | #include <sys/types.h> |
accept()系统调用主要用在基于连接的套接字类型,比如SOCK_STREAM和SOCK_SEQPACKET。它提取出所监听套接字的等待连接队列中第一个连接请求,创建一个新的套接字,并返回指向该套接字的文件描述符。新建立的套接字不在监听状态,原来所监听的套接字也不受该系统调用的影响。
备注:新建立的套接字准备发送send()和接收数据recv()。
sockfd,作用是 利用系统调用socket()建立的套接字描述符,通过bind()绑定到一个本地地址(一般为服务器的套接字),并且通过listen()一直在监听连接;
addr, 指向struct sockaddr的指针,该结构用通讯层服务器对等套接字的地址(一般为客户端地址)填写,返回地址addr的确切格式由套接字的地址类别(比如TCP或UDP)决定;
若addr为NULL,没有有效地址填写,这种情况下,addrlen也不使用,应该置为NULL;
备注:addr是个指向局部数据结构sockaddr_in的指针,这就是要求接入的信息本地的套接字(地址和指针)。
addrlen, 代表一个值结果参数,调用函数必须初始化为包含addr所指向结构大小的数值,函数返回时包含对等地址(一般为服务器地址)的实际数值;
备注:addrlen是个局部整形变量,设置为sizeof(struct sockaddr_in)。
如果队列中没有等待的连接,套接字也没有被标记为Non-blocking,accept()会阻塞调用函数直到连接出现;如果套接字被标记为Non-blocking,队列中也没有等待的连接,accept()返回错误EAGAIN或EWOULDBLOCK。
备注:一般来说accept()为阻塞函数,当监听socket调用accept()时,它先到自己的receive_buf中查看是否有连接数据包;若有,把数据拷贝出来,删掉接收到的数据包,创建新的socket与客户发来的地址建立连接;若没有,就阻塞等待;
为了在套接字中有到来的连接时得到通知,可以使用select() 或poll()。当尝试建立新连接时,系统发送一个可读事件,然后调用accept()为该连接获取套接字。另一种方法是,当套接字中有连接到来时设定套接字发送SIGIO信号。
返回值成功时,返回非负整数,该整数是接收到套接字的描述符;出错时会返回-1,相应地设定全局变量error。
所以,在Java部分的源码里(java.net.ServerSocket#accept)会new 一个Socket出来,方便连接后拿到的新Socket的文件描述符的信息给设定到我们new出来的这个Socket 上来,这点在java.net.PlainSocketImpl#socketAccept中看到的尤为明显,读者可以回顾相关源码。
总结
本文一开始介绍了Bio Socket的基本代码,接着从ServerSocket的bind方法解读,通过图文结合的方式介绍了源码如何处理,整个bind操作过程中有许多native层调用,所以Socket的代码调试是非常麻烦的。
介绍完bind之后,我们接着介绍了ServerSocket中accept方法,并且介绍了accept 方法的阻塞问题实际上和底层的操作系统行为有关,并且通过画图的方式理解accept中Socket连接比较“绕”的操作。
最后,文章的后半部分介绍了如何改造accept以及客户端的Socket连接解决非阻塞问题IO,最后我们介绍了 native accept方法在Linux运作,主要内容为Linux的相关文档理解。
写在最后
理解Socket的非阻塞操作有助于理解 NIO的Channel和Buffer的概念,实际上从我们的Demo代码可以看到Channel和非阻塞的BIO思路比较类似,而BufferReader缓冲流则贴合了 Buffer 的概念。
参考资料
Linux Network Programming, Part 1 (linuxjournal.com)
详解socket中的backlog 参数 - 知乎 (zhihu.com)
BIO到NIO源码的一些事儿之BIO - 掘金 (juejin.cn)
CachedThreadPool的工作原理
源码:
1 | public static ExecutorService newCachedThreadPool() { |
(1)corePoolSize = 0,maximumPoolSize = 最大值(无限大),keepAliveTime = 60s,workQueue = SynchronousQueue
(2)SynchronousQueue(实际上没有存储数据的空闲,是用来做多线程通信之间的协调作用的)。一开始提交一个任务过来,要求线程池里必须有一个线程对应可以处理这个任务,但是此时一个线程都没有,poolSize >= corePoolSize , workQueue已经满了,poolSize < maximumPoolSize(最大值),直接就会创建一个新的线程来处理这个任务。
这样的效果也就是来一个任务就开一个线程,无界,无限开新线程,线程过多容易导致JVM的压力过大甚至直接崩溃。这也是为什么阿里巴巴规范禁掉这个方法的直接原因,容易误用。
(3)如果短期内有大量的任务都涌进来,实际上是走一个直接提交的思路,对每个任务,如果没法找到一个空闲的线程来处理它,那么就会立即创建一个新的线程出来,来处理这个新提交的任务
(4)短时间内,如果大量的任务涌入,可能会导致瞬间创建出来几百个线程,几千个线程,是不固定的。
(5)但是当这些线程工作完一段时间之后,就会处于空闲状态,就会看超过60s的空闲,就会直接将空闲的线程给释放掉。